






The history of cloud computing is the history of one idea. That compute should be a utility you tap into, not a machine you own, repeated at seven different layers over sixty years. IBM proved it on a mainframe in 1964. Salesforce proved it for applications in 1999. AWS proved it for infrastructure in 2006. Docker and Kubernetes proved it for containers in 2013-2015. AWS Lambda proved it for functions in 2014. ChatGPT proved it for AI in 2022. And in 2025, Taskade Genesis is proving it one layer higher, the workspace itself becomes the runtime, and the cloud becomes plumbing.
TL;DR: Cloud computing evolved through seven distinct eras: mainframe timesharing on IBM's CP-40 (1964), commercial VPS hosting via VMware ESX (2001), the public cloud launched by AWS S3 (2006), container orchestration via Docker (2013) and Kubernetes (2015), serverless functions with AWS Lambda (2014), the AI compute era ignited by ChatGPT (2022), and today's workspace-native software layer where AI agents replace the runtime. Build your first workspace app free →
This is the complete timeline, every date verified against primary sources, every era mapped to the technology that ended it, and every wave traced forward to the next.
The Seven Eras of Cloud Computing at a Glance
Cloud computing is usually told as a decade story (1960s, 1990s, 2000s, 2010s, 2020s). That framing hides the actual mechanism, each era ended because a new layer of abstraction made the previous layer's pain disappear. Here is the era model:
Each era inherits the layer below it and abstracts away its pain. Mainframes were the first cloud. They were just owned by IBM instead of Amazon. Virtual machines let one box pretend to be many. Containers let one operating system run many isolated apps. Serverless made even the runtime invisible. AI compute made the model itself a callable service. Workspace-native software makes the entire stack invisible. You describe what you need, and the workspace builds it.
Here is the same story as a date timeline:
| # | Year | Milestone | What It Made Possible |
|---|---|---|---|
| 1 | 1961 | John McCarthy predicts computing-as-a-utility at MIT centennial | The thesis statement of cloud |
| 2 | 1964 | IBM CP-40 — first virtualized timesharing system | Multi-tenant compute on shared hardware |
| 3 | 1969 | CompuServe founded; ARPANET first packet sent | Remote access over a network |
| 4 | 1996 | Compaq's George Favaloro coins "cloud computing" internally | The phrase enters business vocabulary |
| 5 | 1999 | Salesforce launches with "No Software" slogan | The first SaaS company |
| 6 | 2001 | VMware ESX 1.0 ships (March 23) | Production x86 server virtualization |
| 7 | 2006 | AWS S3 launches (March 14, Pi Day); EC2 (August) | The public cloud era begins |
| 8 | 2013 | Docker first release (March 15, PyCon lightning talk) | Containers go mainstream |
| 9 | 2014 | AWS Lambda announced (November 13, re:Invent) | The serverless era begins |
| 10 | 2015 | Kubernetes 1.0 (July 21); CNCF founded same day | Container orchestration becomes standard |
| 11 | 2021 | GitHub Copilot launches (June 29) | AI joins the developer workflow |
| 12 | 2022 | ChatGPT launches (November 30) | AI compute becomes a consumer product |
| 13 | 2024 | Claude Computer Use launches (October 22) | AI controls a virtual computer directly |
| 14 | 2025 | Workspace-native software becomes the new abstraction layer | One prompt → one deployed app |
Now let's walk each era in detail.
Era 1: Mainframe Timesharing (1964–1990)
Cloud computing did not start in 2006. It started in 1964, when IBM researchers Robert Creasy and Les Comeau began work on CP-40 at the Cambridge Scientific Center, the first commercial system that let multiple users share one mainframe through virtualization. CP-40 ran on a modified IBM System/360 Model 40 and used a control program (CP) to give each user the illusion of having their own complete machine. The idea was so successful that it became CP-67 in 1967, then VM/370 in 1972, and the lineage continues today as IBM z/VM, sixty years of unbroken production virtualization.

Why does timesharing matter for cloud history? Because the economic argument was identical:
Without timesharing: With timesharing:
$5M mainframe $5M mainframe
Used 5% of the day Used 80% of the day
By one company By 200 companies
Cost / user / month: $50K Cost / user / month: $1.5K
Substitute "mainframe" with "AWS EC2 instance" and you have the entire pitch for the public cloud forty-two years later. The unit economics never changed; only the hardware and the customer count did. This is why the history of virtualization is structurally inseparable from the history of cloud, virtualization is the technology that made cloud's unit economics work.
In 1961, John McCarthy stood at MIT's centennial celebration and told an audience that "computation may someday be organized as a public utility." In 1962, J.C.R. Licklider, soon to be DARPA's first computing director, wrote a memo describing an "intergalactic computer network" that anyone could plug into from anywhere. CP-40 was the technical proof. CompuServe, founded in 1969, was the commercial proof: pay-as-you-go remote computing over telephone lines, the first time you could rent compute by the hour without owning a building.
The mainframe-timesharing era ended for two reasons. First, the personal computer arrived, the IBM PC in 1981 and the Macintosh in 1984 put a CPU on every desk, and the value of renting one slipped. Second, the LAN and the client-server architecture replaced timesharing terminals with networked workstations. By the mid-1990s, "the mainframe is dead" was the conventional wisdom. It was wrong, IBM mainframes are still running about 70% of the world's enterprise transactions in 2026. But the era of timesharing as the dominant compute model was over. The next abstraction was forming.
For the longer arc of how computation itself emerged from binary, see the complete history of computing.
Era 2: Virtualization and the VPS Boom (1998–2005)
When the mainframe era waned, x86 servers replaced it. But x86 hardware in the 1990s had a critical problem: it could not be virtualized. The x86 instruction set had seventeen "sensitive" instructions that broke the Popek-Goldberg theorem (the 1974 academic standard for what makes a CPU virtualizable). Every attempt to run a hypervisor on x86 hit the same wall. Until 1998, when a small Stanford team founded VMware.
Diane Greene, Mendel Rosenblum, Edouard Bugnion, Scott Devine, and Edward Wang figured out how to virtualize x86 anyway, using a technique called binary translation that rewrote the sensitive instructions at runtime. VMware Workstation shipped in 1999. VMware ESX 1.0, the production server hypervisor, shipped on March 23, 2001. For the first time since the IBM mainframe, you could run multiple isolated operating systems on commodity hardware. The full history of virtualization traces VMware's lineage from CP-40 through Xen, KVM, and Firecracker. But the punchline is that VMware ESX is what made the public cloud economically viable.
Why? Because cloud providers need to sell compute by the slice. Without virtualization, you would have to dedicate a physical server to each customer (the unit economics of dedicated hosting), and the cloud would never have crossed the threshold of being cheaper than running your own datacenter. With virtualization, one $5,000 server can serve forty customers at $50 each, and you have just inverted the cost structure of computing.
This era also gave birth to the VPS (Virtual Private Server) industry. Linode launched in 2003 selling Xen-based VPS slices for $19.95 per month. Slicehost followed in 2006 (acquired by Rackspace in 2008). DigitalOcean opened in 2011 with the marketing line "spin up a server in 55 seconds." The VPS market trained an entire generation of developers to think of compute as something you rent by the month, not something you bolt to a rack.
The most consequential business of this era was not a VPS host, though. It was Salesforce, founded by Marc Benioff in March 1999. Salesforce wasn't selling raw compute; it was selling finished CRM software through a browser, with no installation. The slogan was "No Software" and the logo had a software icon crossed out. Salesforce was the first $1B-revenue SaaS company. It proved that the application layer of the cloud could be more valuable than the infrastructure layer, a lesson that took fifteen years for the industry to fully absorb, and one that Taskade Genesis is repeating at the workspace layer today.

By 2005, the pieces were on the board: virtualization worked, broadband was everywhere, REST APIs had standardized on JSON, and a generation of developers had cut their teeth on VPS. The market was waiting for someone to put it together at scale. That someone was Amazon.
Era 3: AWS and the Public Cloud Explosion (2006–2010)
On March 14, 2006, Pi Day, Amazon launched S3 (Simple Storage Service). It was a HTTP-accessible object store priced at fifteen cents per gigabyte-month. For the first time in computing history, any developer with a credit card could rent infinite storage with one API call. Five months later, on August 25, 2006, EC2 (Elastic Compute Cloud) launched in beta. EC2 let you rent a virtual machine by the hour. The starting price was ten cents per hour. The implications were not obvious.
In hindsight, the AWS launch was the moment cloud became inevitable. But at the time, it looked like a side project, an online bookstore renting out spare datacenter capacity. The deeper bet was that Amazon's internal need to scale (Werner Vogels was already preaching the "primitives, not frameworks" gospel inside the company, see the history of primitives for that lineage) would force them to build infrastructure that any developer would want. They were right. By 2010, AWS was a multi-billion-dollar business that had reshaped venture capital, the YC startup playbook switched from "raise to buy servers" to "raise to pay AWS bills."
The competition arrived in waves:
| Year | Hyperscaler Launch | Why It Mattered |
|---|---|---|
| March 2006 | AWS S3 | First true public cloud service |
| August 2006 | AWS EC2 | Rent VMs by the hour |
| April 2008 | Google App Engine | First major PaaS — write code, Google deploys it |
| February 2010 | Microsoft Azure (GA) | Enterprise gets a credible alternative to AWS |
| August 2011 | Google Compute Engine (preview) | The third hyperscaler enters IaaS |
| April 2013 | Alibaba Cloud (international) | Asia gets its hyperscaler |
The economic shape of the public cloud era was a power law. AWS led; Azure and GCP followed. By 2026 the top three hyperscalers represent roughly two-thirds of the public cloud market, with AWS still dominant but Azure closing the gap on enterprise workloads. The remaining third is split across Oracle Cloud, IBM Cloud, Alibaba, and a long tail of regional providers.
Public Cloud Market (rough 2026 share) AWS ████████████████████████████████ ~31%
Azure ██████████████████████████ ~25%
GCP ████████████ ~11%
Other ███████████████████████████████ ~33%
(Alibaba, Oracle, IBM, regional)
The 2006-2010 window produced more startups than any window in tech history, because the capital cost of starting a software company dropped by an order of magnitude. Dropbox (2007), Airbnb (2008), Stripe (2010), Slack (2013), and ten thousand others were only economically possible because they could rent compute by the hour. The Cloud was a startup industrial revolution.
But by 2013 a new problem had emerged. Cloud servers were too granular, every team was provisioning EC2 instances by hand, configuring them with Puppet or Chef, and writing custom deployment scripts. The cloud had won, but the human workflow on top of it was a mess. The next layer of abstraction was about to arrive.
Era 4: Containers and Kubernetes (2013–2018)
On March 15, 2013, Solomon Hykes walked onto the stage at PyCon and gave a five-minute lightning talk titled "The Future of Linux Containers." He demonstrated a tool called Docker that bundled an application and all its dependencies into a portable image that could run identically on any Linux machine. By the end of the talk, Docker was open-source on GitHub. Within two years, it was the second-most-starred project on the platform. Within three, every cloud provider supported it natively.
Docker didn't invent containers. Linux had cgroups since 2007, LXC since 2008, and FreeBSD jails dated to 2000. What Docker added was developer ergonomics, a simple Dockerfile, a portable image format, and a public registry (Docker Hub). The "works on my machine" problem disappeared. So did the "spin up an EC2 instance and configure it with Chef for forty minutes" problem.
Containers solved the unit-of-deployment problem. But they introduced a new one: if your application runs as fifty containers across twenty servers, how do you schedule them, restart them when they crash, route traffic between them, and roll out updates without downtime? Docker Swarm tried. Apache Mesos tried. Then Google open-sourced its answer.
Inside Google, a system called Borg had been scheduling containerized workloads since 2003. It was the secret weapon that let Google run the world's largest fleet of machines as if they were one giant computer. In 2014, Google donated a clean-room reimplementation of Borg to the open-source world. They called it Kubernetes. Version 1.0 shipped on July 21, 2015, the same day the Cloud Native Computing Foundation (CNCF) was founded to govern it.
Kubernetes won the orchestrator wars in under three years. By 2018 it was the default substrate for new cloud applications, and the term "cloud-native" essentially meant "runs on Kubernetes." Every hyperscaler now offers managed Kubernetes (EKS, AKS, GKE), and the patterns Kubernetes introduced, declarative configuration, desired-state reconciliation, immutable infrastructure, are now baseline expectations for any cloud platform.
The container era also produced a new generation of developer tools. Helm became the Kubernetes package manager. Istio added a service mesh. Prometheus and Grafana standardized observability. The entire CNCF landscape ballooned to hundreds of projects, and "cloud-native engineer" became its own job title with its own salary band. The complexity was real, running Kubernetes well became a full-time job for entire teams. But the productivity payoff was real too. Application teams stopped writing deployment scripts; they wrote YAML.
By 2018 the next question was already forming: if Kubernetes can schedule any container anywhere, why am I still thinking about servers at all?
Era 5: Serverless and Edge Compute (2014–2020)
The serverless era technically began before the container era ended. On November 13, 2014, at AWS re:Invent in Las Vegas, Amazon announced Lambda, a service that ran a function on demand, billed in 100-millisecond increments, with no servers to provision. The pitch was radical: write the code, push it to AWS, and never think about infrastructure again. Cold-start latency was 50-200 milliseconds. Pricing was $0.20 per million invocations plus compute time. For a workload with bursty traffic, the savings versus a 24/7 EC2 instance were enormous.
The hyperscalers all followed. Google Cloud Functions arrived in 2016. Azure Functions launched the same year. Cloudflare Workers (built on V8 isolates instead of containers) shipped in 2018 with sub-millisecond cold starts. Vercel and Netlify made serverless the default deployment model for new web applications. By 2021, "serverless-first" was the recommended architecture for new startups.
Compute granularity over time
(smaller = better unit economics) Mainframe ████████████████████████████████ one machine, many users
VPS ████████████████ one VM, one user
VM ████████████ one EC2, one workload
Container ██████ one container, one process
Function ██ one function, one request
Edge █ one request, anywhere on Earth
Edge compute extended the idea geographically. Instead of running your function in one of AWS's twenty-six regions, Cloudflare Workers ran it in 300+ cities, whichever city was closest to the user. Latency dropped from 100ms to 10ms for global applications. The unit of compute went from "a VM in us-east-1" to "a V8 isolate in São Paulo." The cloud was no longer a place; it was a substrate spread across the planet.
The serverless era also coincided with the rise of "Jamstack", pre-built static sites paired with serverless functions for dynamic behavior. Next.js (2016, Vercel), Gatsby (2015), and SvelteKit (2020) became the new application frameworks. The deployment model became git push, your code is on the global edge in 90 seconds, no infrastructure to manage. This is the model Taskade itself runs on for the marketing site you're reading right now.
By 2021, the application-layer cloud, SaaS, serverless, edge, was the dominant compute model for new software. The mainframe was forty years away in the rearview mirror. But a new compute primitive was about to take over: the model.
Era 6: The AI Compute Era (2021–2024)
The AI compute era did not arrive in a single moment, but three milestones made it inevitable.
June 29, 2021: GitHub Copilot launched in technical preview. For the first time, an AI model became a daily developer tool. Copilot autocompleted code by calling OpenAI's Codex API behind the scenes. The economic structure was new: developers paid $10/month, GitHub paid OpenAI per inference, OpenAI paid Azure for GPU compute. AI inference was a new compute layer that none of the existing cloud abstractions captured.
November 30, 2022: ChatGPT launched. It hit 100 million users in two months, the fastest consumer adoption curve in history. ChatGPT was a model call wrapped in a chat UI, but it crossed a threshold, the AI model itself became a consumer product. Cloud providers scrambled to add GPU capacity. NVIDIA's H100 and B100 GPUs became the new EC2, the foundational unit of AI compute.
October 22, 2024: Anthropic released Claude Computer Use in public beta. For the first time, an AI model could control a virtual computer directly, move the mouse, type into windows, click buttons, take screenshots, run commands. The compute primitive shifted again: instead of an AI model that responded to a prompt, the AI became an agent that operated a machine. For the deeper context, see the history of Anthropic and Claude.
The AI compute era introduced four new infrastructure primitives:
| Primitive | What It Is | Cloud Equivalent | Example |
|---|---|---|---|
| Inference endpoint | A hosted model you call with a prompt | EC2 instance | OpenAI API, Anthropic API |
| Vector database | Storage indexed by embedding similarity | S3 + RDS | Pinecone, Weaviate, pgvector |
| Agent sandbox | Isolated VM where an AI agent can run code | Lambda function | E2B, Daytona, Modal |
| Agent runtime | Orchestration layer for multi-step AI workflows | Kubernetes | Anthropic Computer Use, OpenAI Agents |
The AI compute era is still being built. Token pricing has dropped 90%+ since 2023. Context windows have grown from 4K to 1M tokens. Frontier models from OpenAI, Anthropic, Google, and open-weight providers like Qwen and DeepSeek now compete on price, latency, and capability. For the model-by-model lineage of how we got here, see the history of Google Gemini and the history of Anysphere Cursor.
But the AI compute era is still fundamentally an infrastructure-layer story, the world's largest cloud bills are now GPU bills. The next layer, the one that turns AI compute into useful software for people who don't write code, is workspace-native.
Era 7: Workspace-Native Software (2025+)
The seventh era is the one we are inside right now. Workspace-native software is the abstraction layer above the AI compute era, the layer where a non-programmer describes what they want in plain English, and the workspace generates a full application: databases, AI agents, automations, custom domains, shareable URLs, and team permissions.
The thesis is simple: every previous cloud era abstracted away the layer beneath it, but the developer was always still in the loop. Mainframes abstracted away the hardware, but you still wrote COBOL. VPS abstracted away the hardware purchase, but you still configured the OS. AWS abstracted away the datacenter, but you still wrote application code. Kubernetes abstracted away the server, but you still wrote YAML. Serverless abstracted away the runtime, but you still wrote functions. The AI compute era abstracted away the algorithm, but you still wrote the prompt-handling logic and glued together the inference, vector store, and agent code.
Workspace-native software abstracts away the application itself. You describe what your team needs, "a CRM that tracks deals and emails me when a client goes quiet for two weeks", and the workspace generates the database, the AI agent that watches deals, the automation that sends the alert, the project views your team uses, and the shareable URL your client portal lives on. This is the model Taskade Genesis ships today.
The Workspace-Native era runs on a self-reinforcing loop called Workspace DNA: Memory + Intelligence + Execution. Your projects hold the memory. Your custom AI agents read that memory and turn it into intelligence. Your automations execute on that intelligence, sending the email, creating the task, updating the spreadsheet, and the result writes back into your projects, making the workspace smarter the next time. Learn the loop in depth →
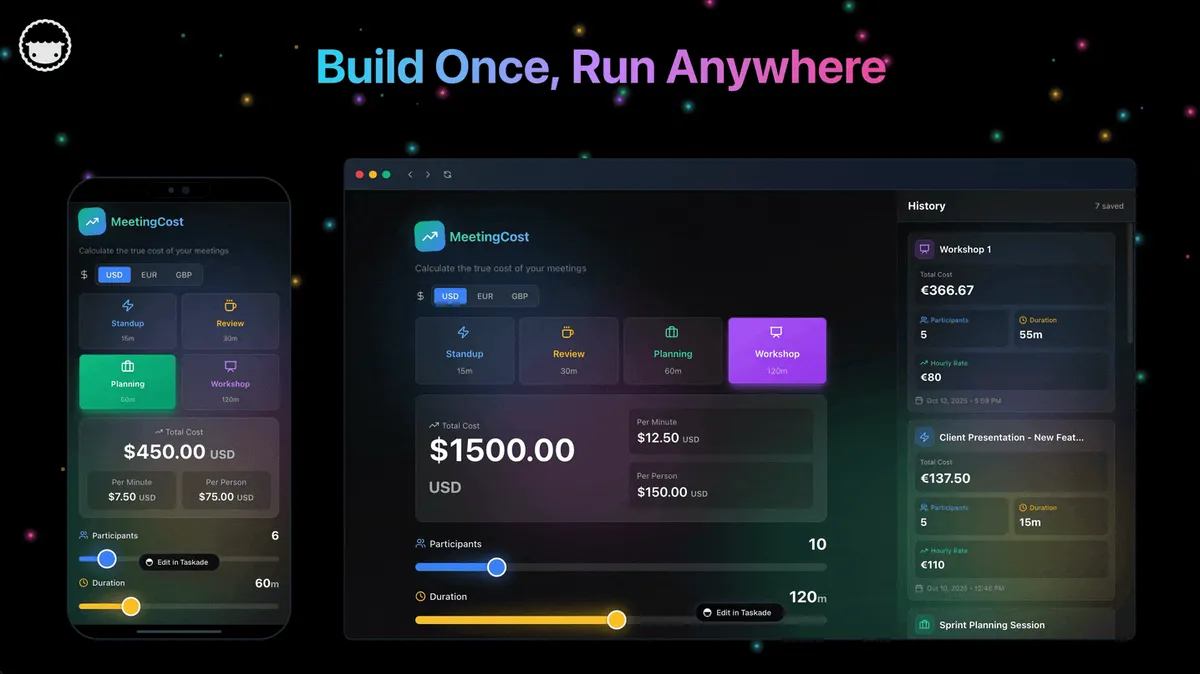
The Workspace DNA loop is what every prior cloud era was missing. AWS gave you compute. Heroku gave you a runtime. Lambda gave you a function. OpenAI gave you a model. None of them gave you a self-reinforcing system where the output of each cycle is the input to the next. That coupling is the seventh-era primitive:
The capability surface is significantly larger than any prior era's developer-facing platform. From a single prompt, Taskade Genesis generates apps that include:
- A live database with custom fields, 7 project views (List, Board, Calendar, Table, Mind Map, Gantt, Org Chart), and team role-based permissions across 7 tiers
- AI agents trained on your workspace context, with 34 built-in tools, slash commands, persistent memory, and public embedding
- Automations with triggers (Slack, Gmail, Calendly, webhooks) and actions across 100+ bidirectional integrations
- Multi-agent collaboration. You can compose multi-agent teams that hand work off to each other through a shared inbox
- A shareable URL with your own custom domain, OIDC/SSO authentication, and a community-gallery listing if you want it
- Access to 15+ frontier models from OpenAI, Anthropic, Google, plus open-weight providers, the workspace handles model routing automatically
- An MCP server so other AI tools can call into your workspace as a tool
The Genesis Capability Map: What "Workspace-Native" Actually Ships
Workspace-native is not a slogan. Every prior cloud era required you to glue together at least five products to get a working app (a compute provider, a database, an auth system, a queue, a deploy pipeline). Taskade Genesis ships all of them, and twenty more, as one coherent surface:
| Capability | What It Replaces | Cloud-Era Equivalent |
|---|---|---|
| Plain-English prompt | Visual builder, code editor | Bubble, Webflow, Lovable, Cursor |
| Projects + 7 views | Database + UI framework | Postgres + Retool + React |
| AI agents (custom, multi-agent, 34 built-in tools) | LangChain + agent runtime | LangGraph, AutoGPT, Modal |
| Automations (Temporal-backed) | Workflow engine | Zapier, Make, n8n, Temporal Cloud |
| 100+ bidirectional integrations | Custom API glue | MuleSoft, custom webhooks |
| Frontier models, auto-routed | Model gateway | OpenRouter, LiteLLM |
| MCP server (both directions) | Tool calling protocol | Custom REST adapters |
| Custom domains + SSL + auth | Hosting + CDN + OIDC | Vercel + Auth0 + Cloudflare |
| Community Gallery (clone in 60s) | App marketplace | GitHub + npm + ProductHunt |
| Stripe checkout actions | Payment integration | Stripe + Lambda + webhook glue |
| Vibe Coding / Payments / Workflows / Marketing | Natural-language → behavior | None — workspace-native primitive |

The MCP-both-sides design is the seventh-era version of what REST APIs did for the third era. In 2006, "everything is a REST endpoint" became the lingua franca of the cloud. In 2026, "everything is an MCP tool call" is becoming the lingua franca of AI agents. Genesis acts as both an MCP server (so Claude Desktop, Cursor, and VS Code can drive your workspace) and an MCP client (so your agents can call into external Notion, Linear, Salesforce, and GitHub MCP servers). The workspace becomes the universal switchboard.
The first six eras of cloud computing were a thirty-year project to make compute cheap. The seventh era is a project to make software accessible, to put the power of "describe an app, deploy it in minutes" into the hands of anyone with a browser. For the parallel arc in productivity software, see the history of Airtable, Lotus Notes, and HyperCard, each of which tried to do this at the abstraction level of its own era.
For a wider look at the trajectory that ends here, see the history of primitives (file → icon → page → account → block → note → task) and why SaaS is being unbundled in 2026. The seventh era's pricing model is part of that unbundling, flat per-workspace pricing (Free, Starter $6, Pro $10, Business $25, Max $100, Enterprise $250 per month on annual billing) replaces per-seat SaaS, because one workspace runs many apps.
A Visual Timeline of Cloud Computing
The full timeline of cloud computing, in ASCII, fits on one screen:
1961 ─ McCarthy predicts computing-as-utility
1962 ─ Licklider's "intergalactic computer network" memo
1964 ┤ IBM CP-40 ── first virtualized timesharing system
1969 ─ CompuServe founded; ARPANET first packet
1972 ─ IBM VM/370 ships
1974 ─ Popek-Goldberg virtualization theorem published
1981 ─ IBM PC launches; mainframe era starts to wane
1996 ─ Compaq's George Favaloro coins "cloud computing"
1998 ─ VMware founded at Stanford
1999 ┤ Salesforce founded; "No Software" launches SaaS
2001 ┤ VMware ESX 1.0 (March 23) ── x86 virtualization
2003 ─ Linode launches Xen-based VPS hosting
2006 ┤ AWS S3 (March 14); EC2 (August) ── public cloud begins
2008 ─ Google App Engine launches (first major PaaS)
2010 ─ Microsoft Azure GA; Heroku acquired by Salesforce
2013 ┤ Docker first release (March 15) ── containers go mainstream
2014 ┤ AWS Lambda announced (November 13) ── serverless begins
2015 ┤ Kubernetes 1.0 (July 21); CNCF founded same day
2017 ─ Cloudflare Workers preview (edge compute)
2018 ─ Kubernetes is the default substrate
2021 ┤ GitHub Copilot launches (June 29) ── AI joins dev workflow
2022 ┤ ChatGPT launches (November 30) ── AI compute consumer era
2023 ─ Frontier model APIs become commodity
2024 ┤ Claude Computer Use (October 22) ── AI operates a machine
2025 ┤ Workspace-native era ── one prompt, one deployed app
2026 ─ You are here
Here is the same timeline as an adoption curve:
And the same sixty-year story as a cost curve, the marginal cost of one second of compute, indexed (mainframe-1964 = 100,000,000; serverless-2014 = 1; workspace-native = effectively 0 because the user never thinks about it):
Marginal cost of 1 second of compute (log scale, indexed) 1964 mainframe ████████████████████████████████ 100,000,000
1981 minicomputer ████████████████████████ 10,000,000
1999 VPS ████████████████ 100,000
2006 EC2 on-demand ████████████ 1,000
2013 Docker container ████████ 100
2015 Kubernetes pod ██████ 50
2014 Lambda function ██ 10
2018 Cloudflare Worker █ 1
2025 Workspace-native ▏ ~0 (invisible)
The story is one curve, eight orders of magnitude, sixty-one years. Each successive abstraction killed the unit economics of the layer below it.
AWS vs Azure vs GCP vs Taskade Genesis
The three hyperscalers dominate the infrastructure layer. Taskade Genesis sits at the workspace-native layer above them, the table compares apples to apples on what each one is best at:
| Capability | AWS | Azure | GCP | Taskade Genesis |
|---|---|---|---|---|
| Launch year | 2006 | 2010 | 2011 | 2025 |
| Primary abstraction | Infrastructure (IaaS) | Infrastructure + enterprise apps | Infrastructure + data | Workspace (apps from prompts) |
| You bring | Code, config, ops | Code, config, ops | Code, config, ops | A plain-English description |
| You manage | Servers, storage, networking | Servers + Microsoft stack | Servers + data pipelines | Nothing |
| Pricing model | Per-second compute, per-GB storage | Per-second compute, per-seat M365 | Per-second compute, per-query BigQuery | Flat per-workspace |
| Time to first app | Hours to days | Hours to days | Hours to days | Under 5 minutes |
| Integrations | API gateway, you build | Logic Apps + connectors | Cloud Functions, you build | 100+ bidirectional, built-in |
| AI included | Bedrock (pay extra) | Azure OpenAI (pay extra) | Vertex AI (pay extra) | 15+ frontier models, included |
| Best for | Custom infrastructure | Enterprise Microsoft shops | Data-heavy workloads | Teams that want working apps now |
Hyperscalers and workspace-native platforms are not competitors. They are layers of the same stack. Taskade Genesis runs on top of hyperscaler infrastructure (the same way every SaaS company does), but the user never sees it. The workspace is the runtime, and the cloud is plumbing.
For more on how Taskade compares to other application-layer cloud platforms, see our Airtable comparison, the story of ClickUp, and Basecamp's history, three companies who built at different layers of this stack.
Who Invented Cloud Computing?
The honest answer is "nobody and everybody". But here are the people who deserve the most credit, in chronological order:
| Person | Year | Contribution |
|---|---|---|
| John McCarthy | 1961 | Predicted "computation as a public utility" at MIT centennial |
| J.C.R. Licklider | 1962 | Wrote "Intergalactic Computer Network" memo at DARPA |
| Robert Creasy & Les Comeau | 1964 | Built IBM CP-40, the first virtualized timesharing system |
| Jeffrey Wilkins | 1969 | Founded CompuServe, the first commercial timesharing service |
| Gerald Popek & Robert Goldberg | 1974 | Published the formal theory of virtualization |
| Marc Benioff | 1999 | Founded Salesforce, proved SaaS could be a category |
| George Favaloro | 1996 | Coined "cloud computing" internally at Compaq |
| Diane Greene | 1998 | Co-founded VMware, made x86 virtualization production-ready |
| Andy Jassy | 2003 | Wrote the AWS business plan; later launched S3 and EC2 |
| Solomon Hykes | 2013 | Open-sourced Docker, made containers a developer primitive |
| Joe Beda, Brendan Burns, Craig McLuckie | 2014 | Open-sourced Kubernetes from Google's Borg |
| Tim Wagner | 2014 | Led AWS Lambda from idea to launch — the serverless era |
| Sam Altman, Dario Amodei, Demis Hassabis | 2022+ | Shipped the frontier AI models that became the new compute primitive |
The phrase "cloud computing" itself has the cleanest origin story, Compaq executive George Favaloro used it in an internal 1996 document titled "Internet Solutions Division Strategy for Cloud Computing," referring to the consumer market for internet-delivered services. The phrase escaped Compaq in the late 1990s and was used publicly by Google's Eric Schmidt at a conference in August 2006, two weeks before EC2 launched. Schmidt is sometimes credited with popularizing it. The architectural idea is much older than the phrase.
The Five Technologies That Made Cloud Possible
Cloud computing did not arrive because one company built it; it arrived because five underlying technologies hit maturity at the same time:
Virtualization. Without VMware ESX (and Xen, KVM, Firecracker after it), one physical server could not safely host workloads from forty customers. The history of virtualization is sixty years of solving this one problem. Without it, the unit economics of the cloud collapse.
Commodity x86 hardware. Intel and AMD made server-class CPUs cheap enough that hyperscalers could buy them by the container-load. The IBM mainframe was technically superior for decades. It just cost a hundred times more per CPU cycle.
Broadband internet. Cloud requires the client to trust a remote server with its data and compute. Sub-100ms round-trip latency to a hyperscaler region only became routine in the 2005-2010 window for residential users and 2000-2005 for enterprises. Before that, the cloud's user experience was unacceptable.
REST APIs and JSON. The cloud needs a universal protocol for "let me ask the platform to do something." HTTP + JSON became that protocol around 2005, replacing SOAP/XML, which had been the previous candidate. Every cloud service today is some variant of "POST a JSON document, get a JSON document back." This standardization is often invisible but it was decisive.
Containers and orchestration. Docker and Kubernetes finished the job that VMs started, making the unit of deployment small enough to compose hundreds of services into one application. Without containers, microservices architecture is too operationally expensive to be practical.
Each of these technologies is itself the product of many smaller stories, see the history of computing for the underlying CPU and protocol lineage, the history of CRDTs for the data-sync layer that makes cloud collaboration work, and the history of mermaid for the diagrams-as-code culture that lets cloud-native teams document their systems faster than the systems change.
What Comes After the Cloud?
The cloud is not going away, every workspace-native app runs on hyperscaler infrastructure. But the cloud is becoming invisible. The interesting question for 2026 and beyond is: what is the layer above the cloud?
The honest answer has three parts:
1. The workspace is the runtime. The unit of deployment is no longer a function or a container; it's a workspace, a coherent environment with memory, intelligence, and execution all coupled. You don't deploy code; you describe outcomes, and the workspace generates the code, the database, the agents, and the automations that produce those outcomes. This is what Taskade Genesis ships today. For the build-from-a-prompt walkthrough, see /learn/genesis/first-app.
2. AI agents are the new operating system. The mainframe ran COBOL. The PC ran Windows. The cloud ran Linux containers. The workspace runs AI agents. An agent is a configurable, persistent, tool-using process that takes intent as input and produces work as output. Multi-agent collaboration replaces the old microservices pattern of "many small programs that call each other", except now the small programs are AIs that can reason.
3. The pricing model becomes per-workspace, not per-seat. Per-seat SaaS pricing was a side effect of cloud-era SaaS: you had one app per company, and you charged per user. In the workspace era, one workspace runs many apps, and pricing collapses to flat per-workspace tiers. The unbundling of SaaS and the SaaS-apocalypse thesis are both downstream consequences of this shift.
What the seventh era looks like in practice is a single screen, a workspace that holds your team's memory (projects, files, notes), runs your team's intelligence (AI agents, knowledge graph), and triggers your team's execution (automations, integrations, deployed apps). The cloud is still there, doing the work. You just don't have to think about it anymore.
The seventh-era stack, end-to-end:
Every layer above inherits the one below it and abstracts away its operational pain. The user at the top, the person describing an app in plain English, never sees any of the layers underneath. That is what "the cloud is plumbing" means.

To experience the seventh era directly, build your first workspace app from a prompt, five minutes, no credit card, no infrastructure. To see what apps other people have built, browse the Community Gallery. To learn how workspace-native apps actually work under the hood, start with the Genesis FAQ and the Workspace DNA explainer.
Frequently Asked Questions
Who invented cloud computing?
No single person. But the credits cluster around a few names. John McCarthy predicted computing-as-a-utility in 1961. J.C.R. Licklider sketched the intergalactic computer network in 1962. IBM's Robert Creasy and Les Comeau built CP-40 in 1964, proving virtualization works. Marc Benioff founded Salesforce in 1999, proving SaaS is a category. Andy Jassy and team launched AWS S3 in 2006, proving infrastructure can be a public utility.
What year was cloud computing invented?
The technical foundation is 1964 (IBM CP-40, the first virtualized timesharing system). The commercial application layer is 1999 (Salesforce). The public infrastructure layer is 2006 (AWS S3 on March 14, EC2 in August). All three years are defensible answers depending on which layer you mean.
What was the first cloud platform?
The first SaaS platform was Salesforce, launched March 8, 1999 with the "No Software" slogan. The first public IaaS platform was Amazon S3, launched March 14, 2006 ("Pi Day"). EC2 followed in August 2006. The first PaaS was Google App Engine in April 2008.
When did AWS launch S3?
Amazon S3 launched on March 14, 2006, known internally at AWS as "Pi Day" because of the date. EC2 launched five months later in August 2006. Lambda, the first major serverless platform, launched November 13, 2014 at AWS re:Invent.
When did Kubernetes 1.0 release?
Kubernetes 1.0 shipped on July 21, 2015. The Cloud Native Computing Foundation (CNCF) was founded the same day to govern the project. Google donated Kubernetes based on a decade of running its internal Borg cluster scheduler. Docker had launched the modern container era two years earlier on March 15, 2013.
What is serverless computing?
Serverless lets developers deploy code without managing servers. The cloud provider runs the function only when it's needed and bills per invocation in millisecond increments. AWS Lambda kicked off the modern serverless era on November 13, 2014. Cloudflare Workers, Vercel, and Netlify made it the default deployment model for new web applications.
What is the difference between IaaS, PaaS, and SaaS?
IaaS rents raw infrastructure (AWS EC2). PaaS rents a managed runtime (Heroku, Google App Engine). SaaS rents finished software (Salesforce, Gmail). The 2025+ era adds a fourth layer, workspace-native, where you describe an app in plain English and the platform generates it. Taskade Genesis is the canonical example of this fourth layer.
How much does cloud computing cost?
Hyperscaler infrastructure still bills per-second on compute and per-gigabyte on storage. Application-layer cloud platforms have largely moved to flat per-user or per-workspace pricing. Taskade Genesis is Free, Starter $6, Pro $10, Business $25, Max $100, and Enterprise $250 per month on annual billing, flat per-workspace rather than per-seat.
What came before AWS?
Before AWS launched in 2006, companies either ran their own data centers, rented space in colocation facilities, or rented VPS slices from hosts like Linode (founded 2003), Slicehost, and Rackspace. Before VPS, dedicated hosting and shared hosting were the options. Before all of those, the mainframe-timesharing model from 1964 onward let multiple users share one IBM machine, economically the same idea, technically the same idea.
How does AI compute differ from regular cloud compute?
Traditional cloud compute is CPU-driven and optimized for request-response web applications. AI compute is GPU-driven and optimized for matrix multiplication, large language model inference and training. The AI compute era was ignited by GitHub Copilot (June 29, 2021), ChatGPT (November 30, 2022), and Claude Computer Use (October 22, 2024). NVIDIA GPUs are the new EC2, the foundational hardware unit of the era.
Is the cloud the same as the internet?
No. The internet is the network (TCP/IP, DNS, HTTP) that lets any computer talk to any other. The cloud is a deployment model where computation lives on someone else's servers, accessed over the internet. You can have an internet without a cloud (the 1990s) and you can have a cloud without using public internet (private cloud, on-premise Kubernetes). The cloud is what you do with the internet.
What comes after cloud computing?
The next layer is workspace-native software, where the workspace itself is the runtime, AI agents are the operating system, and the cloud is plumbing the user never sees. Taskade Genesis is one implementation: describe an app, get a deployed app with database, agents, automations, and a shareable URL in minutes.
Sources and Further Reading
The dates and milestones in this article are verified against primary sources:
- IBM, "z/VM: 40 Years of Virtualization Innovation"
- Wikipedia, History of cloud computing and Cloud computing
- AWS, "Twenty years of Amazon S3 and building what's next" (2026 retrospective)
- AWS, "AWS Lambda turns ten: The first decade of serverless innovation"
- VMware history archive, "The History of VMware ESXi (2001–2025)"
- Google Cloud Platform Blog, "Kubernetes V1 Released" (July 21, 2015)
- GitHub Blog, "Introducing GitHub Copilot: your AI pair programmer" (June 29, 2021)
- Anthropic, "Introducing computer use, a new Claude 3.5 Sonnet" (October 22, 2024)
- CompuServe corporate history archive (Compu-Serv Network, Columbus OH, 1969)
For related history-series posts: the history of computing, history of virtualization, history of primitives, history of mermaid, history of CRDTs, history of HyperCard, history of Etherpad, history of Lotus Notes, history of quantum computing, history of Anthropic Claude, history of Anysphere Cursor, history of Google Gemini, history of Airtable, history of ClickUp, and history of Basecamp.
For the conversion arc above the cloud, see why SaaS is being unbundled, the SaaS-pocalypse explained, and SaaS evolved into living software.
Build the seventh era yourself, start a free Taskade workspace, browse the Community Gallery, or browse the AI Apps showcase, Agents and Automate hubs to see workspace-native software in production.