In 1978, Leslie Lamport published a four-page paper called "Time, Clocks, and the Ordering of Events in a Distributed System." It introduced logical clocks, a way to order events across multiple computers without a shared physical timer, and won him the Turing Award thirty-five years later. Most of the field of distributed systems hangs from that paper, including the entire CRDT lineage this post is about.
Forty-eight years later, in 2026, Conflict-free Replicated Data Types power Figma's multiplayer cursor, Linear's offline-first issue sync, Apple Notes' cross-device sync, Obsidian Sync, the Automerge ecosystem, and the Yjs library running inside Tiptap and tens of thousands of collaborative editors.
This is the story of how math beat the distributed-systems problem, and why Taskade Projects still uses Operational Transformation instead.
TL;DR: CRDTs converge math-first rather than coordination-first. From Lamport (1978) to Bayou (1987-95) to WOOT (2006) to Shapiro's 2011 CRDT formalization to YATA / Yjs / Automerge / Peritext / Diamond Types, CRDTs are now a mature production category. They power peer-to-peer and local-first software. They do not universally beat OT, for server-mediated AI-agent workspaces, OT is still the right call. Taskade Projects chose OT precisely because AI agents are server-side. Try Taskade Genesis →
🗺️ 48 Years of CRDTs in One Diagram
Four eras. One unbroken line from a four-page 1978 paper to today's local-first software.
⏰ 1978: Lamport's Logical Clocks: The Real Beginning
Leslie Lamport's 1978 paper "Time, Clocks, and the Ordering of Events in a Distributed System" is the founding document of distributed systems theory. The core insight: distributed events have a partial order, not a total order, and you can compute that partial order without a shared physical clock by giving each node a logical counter that increments on local events and updates when messages arrive.
Logical clocks gave the field the concept of a happens-before relation:
Event A happens-before Event B if:
- A and B are on the same node, and A precedes B locally, OR
- A is the sending of a message and B is the receipt, OR
- There exists C such that A → C and C → B (transitive)
Lamport clocks count events linearly per node. Vector clocks (independently proposed by Mattern and Fidge in 1988) generalize this to capture the full causal history. Vector clocks are the engine inside almost every modern CRDT, every operation carries a vector clock so any replica can determine whether two operations are concurrent or causally ordered.
Lamport won the Turing Award in 2013 specifically for "fundamental contributions to the theory and practice of distributed and concurrent systems, notably the invention of concepts such as causality and logical clocks." Without those concepts, CRDTs cannot exist.
🌀 1987–1995: Bayou at Xerox PARC: The First Modern Replication System
In 1987, a research group at Xerox PARC led by Terry, Theimer, Petersen, Demers, Spreitzer, and Hauser began work on a system called Bayou, a replicated database for mobile and disconnected computing. The defining Bayou paper (1995, SOSP) introduced ideas that are the direct conceptual ancestors of CRDTs:
- Anti-entropy gossip, peers exchange operations during sync windows
- Tentative writes, operations can be applied locally and reordered later
- Conflict detection with application-specific resolution
- Eventual consistency as a stated design goal, not a bug
Bayou wasn't a CRDT by the 2011 formal definition. It had explicit conflict resolution rather than algebraically conflict-free merges. But it framed the problem space the way the CRDT community would later inherit it.
In parallel, Lotus Notes 1.0 (December 1989) shipped commercial replicated-database collaboration, see our Lotus Notes history for that story. Ray Ozzie's Notes was the practical evidence that replicated collaborative systems could ship at scale.
📐 2006: WOOT: The First Text CRDT
Anatomy of a WOOT W-character — what every node carries W-character "h"
┌──────────────────────────────────────┐
│ id: (siteA, 1701) │ ◄── unique tuple: site + counter
│ visible: true │ ◄── tombstone flag
│ alpha: "h" │ ◄── the actual rune
│ prev: (start, 0) │ ◄── partial-order neighbour
│ next: (siteA, 1702) │ ◄── partial-order neighbour
└──────────────────────────────────────┘
Concurrent insert from siteB:
"i" between "h" and "e" of "hello"
┌──────────────────────────────────────┐
│ id: (siteB, 412) │
│ visible: true │
│ alpha: "i" │
│ prev: (siteA, 1701) ◄── "h" │ All four sites converge:
│ next: (siteA, 1703) ◄── "e" │ "h" → "i" → "e"
└──────────────────────────────────────┘ because IDs break ties.
Delete "e":
Mark visible=false (tombstone). Keep the node forever
so future concurrent inserts referencing prev/next
still find a target. Yjs/Automerge inherited this.
In 2006, Gérald Oster, Pascal Urso, Pascal Molli, and Abdessamad Imine at INRIA Lorraine published "Data Consistency for P2P Collaborative Editing" (CSCW 2006). The paper introduced WOOT (WithOut Operational Transformation), the first algorithm that achieved collaborative text editing without a central server and without Operational Transformation.
WOOT's key idea: every character carries a unique ID and a partial order based on its insertion neighbours. Concurrent inserts are resolved by a deterministic rule on IDs. The whole document is technically an append-only log of character creations and tombstone marks; the rendered text is computed by walking the partial order.
This was groundbreaking. The Oster paper also proved that achieving TP2 (correctness under three-way concurrent OT transforms without a central arbiter) was impractical for the OT family, motivating the entire CRDT research agenda that followed.
Then in 2009, Stéphane Weiss, Pascal Urso, and Pascal Molli at INRIA published Logoot, replacing WOOT's neighbour-based IDs with fractional position identifiers. Each character gets a position like [0.3, 0.7, 0.42] and concurrent inserts get fresh positions in between. Logoot was simpler to implement and faster than WOOT, and it's the basis for several modern CRDTs.
🏆 May 2011: The Shapiro CRDT Paper: Theory Crystallizes
Marc Shapiro, Nuno Preguiça, Carlos Baquero, and Marek Zawirski at INRIA published "Conflict-free Replicated Data Types" as INRIA technical report RR-7687 in May 2011, followed by the SSS 2011 conference paper. This is the moment the field acquired a name.
Three contributions:
1. The Term "CRDT"
Before this paper, the field used "commutative replicated data types," "convergent replicated data types," and various informal labels. The unified term "Conflict-free Replicated Data Type" with the abbreviation CRDT made the field legible to industry.
2. The Two Families
Shapiro et al. formally distinguished:
- State-based CRDTs (CvRDTs), replicate the entire state; merge using a join-semilattice. Requires only eventual delivery.
- Operation-based CRDTs (CmRDTs), replicate operations; require exactly-once causal delivery from the transport layer.
The two are theoretically equivalent (every CvRDT can be expressed as a CmRDT and vice versa) but practically pick different trade-offs.
3. The Standard Library of CRDTs
The paper enumerated the canonical "starter set" of CRDT data types:
- G-Counter, grow-only counter
- PN-Counter, increment-and-decrement counter
- G-Set, grow-only set
- 2P-Set, add-once, remove-once set
- LWW-Element-Set, last-writer-wins set
- OR-Set, observed-remove set
- MV-Register, multi-value register
- LWW-Register, last-writer-wins register
- RGA, replicated growable array (sequence)
This catalogue became the API surface of every CRDT library that followed. If you read the Yjs or Automerge documentation today, you are looking at the descendants of this list.
In the same year, Hyun-Gul Roh, Myeongjae Jeon, Jin-Soo Kim, and Joonwon Lee at KAIST published the RGA (Replicated Growable Array) algorithm, a high-performance sequence CRDT that's still the basis for most production text CRDTs.
🏗️ 2014: Riak DT: CRDTs Hit Production Databases
The first widely-deployed production CRDT system was Riak DT, shipped by Basho in 2014. Riak, a distributed key-value store popular in the 2010s, added support for CRDT-typed values: counters, sets, maps, and flags that converged automatically across geographically distributed replicas without read-time conflict resolution.
Riak DT proved CRDTs could survive operations at scale. It also showed the cost: garbage collection of tombstones, vector-clock bloat, and the operational complexity of running an anti-entropy gossip protocol on a multi-data-center cluster.
After Riak's sunsetting, the production-CRDT mantle moved to client-side libraries (Yjs, Automerge) where the deployment story was simpler.
📚 2016: Yjs and the YATA Algorithm
In 2016, Petru Nicolaescu, Kevin Jahns, Patrick Derntl, and Ralf Klamma at RWTH Aachen published "Near Real-Time Peer-to-Peer Shared Editing on Extensible Data Types", introducing YATA ("Yet Another Transformation Approach"), a high-performance text CRDT algorithm.
Kevin Jahns simultaneously released Yjs as an open-source JavaScript implementation. Yjs achieved production performance through several engineering tricks:
- Run-length encoding, consecutive characters typed by the same client are compressed into single structs with a length field
- B-tree indexing, positional queries (line N, column M) traverse a balanced tree over the operation log
- State-vector deltas, peers exchange only the operations the other side is missing
- Garbage collection, tombstones are reclaimed when no future operation can reference them
By 2026, Yjs is the most-deployed CRDT library in the world:
| Yjs adopters | Workload |
|---|---|
| Tiptap | Headless rich-text editor with built-in collaborative editing |
| Hocuspocus | Production Yjs server / sync hub |
| BlockSuite | Block-style document editor (used by AFFiNE) |
| JupyterLab | Real-time collaborative notebook editing |
| CodeMirror 6 | Live cursor + collaborative editing extension |
| Outline (the wiki) | Collaborative wiki editing |
| Logseq | Local-first networked thought |
| Roam Research-likes | Many block-based note tools |
Yjs is the engine room of the local-first software movement.
🔄 2017: Automerge and the JSON CRDT
In 2017, Martin Kleppmann, by then a Senior Research Associate at the University of Cambridge, released Automerge, a CRDT library for arbitrary JSON-shaped data.
Automerge wasn't the first JSON CRDT (academic prototypes had existed for years), but it was the first one designed for ergonomic use by application developers. Automerge supports:
- Text via RGA + later Peritext
- Maps with concurrent key updates
- Lists with concurrent insertions and deletions
- Counters with concurrent increments
- Nested structures of arbitrary depth
Kleppmann's other writing, "Designing Data-Intensive Applications" (2017, the most-cited distributed-systems book of the decade) and the "Local-First Software" essay (2019, with Adam Wiggins / Peter van Hardenberg / Mark McGranaghan at Ink & Switch), made him the central voice of the CRDT and local-first movements.
Automerge 3.x (2024-2025) added columnar storage (compressing operations to disk-friendly byte layouts), the Peritext rich-text algorithm, and substantial performance improvements. It is the leading "JSON CRDT" of 2026 alongside Yjs's text-and-shared-types model.
🌍 2019: The Local-First Manifesto
In April 2019, Ink & Switch published "Local-First Software: You Own Your Data, in Spite of the Cloud", an essay by Martin Kleppmann, Adam Wiggins, Peter van Hardenberg, and Mark McGranaghan that crystallized a design philosophy:
The Seven Ideals of Local-First Software
- No spinners, software works at the speed of local I/O
- Multi-device, your data follows you across devices
- Network is optional, works offline
- Real-time collaboration with co-located peers when online
- Longevity, your data outlives the vendor
- Privacy and security by default
- You retain ultimate ownership and control
CRDTs are the technical enabler. They make eventual consistency mathematical rather than coordination-based. The manifesto became the rallying cry for a generation of CRDT-based applications: Linear's offline-first sync, Obsidian Sync, Apple Notes cross-device sync, the Automerge ecosystem of local-first apps, and dozens of indie experiments.
Linear is the canonical commercial success story, a project management tool with full offline sync, instant UI, and CRDT-backed state that won developers' hearts.
⚡ 2020–2023: Joseph Gentle, Diamond Types, and "CRDTs Go Brrr"
The most influential practitioner voice in the OT/CRDT debate is Joseph Gentle, a former Google Wave engineer who extracted the Wave OT primitives into open source as ShareJS and ot-json0 (the same library Taskade Projects runs on today).
Gentle's three-essay arc shifted the field:
2011: "Implementing OT Sucks"
The candid practitioner take on OT's combinatorial complexity. "There's a million algorithms with different tradeoffs, mostly trapped in academic papers." Gentle had shipped OT at scale at Google and could explain why it was painful to maintain.
2020: "I Was Wrong. CRDTs Are the Future"
The essay every Reddit thread quotes. Gentle argued that CRDTs had matured to the point where new offline-first or peer-to-peer projects should not start with OT. Read in context, this was not a generic OT obituary, Gentle was specifically arguing for CRDTs in workloads where their advantages applied. He never claimed Google Docs or Etherpad should switch.
2021: "CRDTs Go Brrr"
Gentle introduced Diamond Types, his own text CRDT. The headline: ~5,000× faster than the CRDT implementations he had benchmarked the year before, with wire-format parity to OT for many workloads. The breakthroughs:
- Columnar encoding, operations are stored in column-oriented byte layouts, not row-oriented, dramatically improving compression
- B-tree internals, fast positional queries
- Optimized rebase, common-case fast paths for non-overlapping concurrent edits
Diamond Types changed practitioner opinion on CRDT performance. By 2023 the consensus was that the perf gap between OT and CRDT had closed.
📝 November 2022: Peritext Closes the Rich-Text Gap
Until 2022, rich-text CRDTs had a known weak spot: inline formatting intent preservation. The canonical example:
Alice formats "abc" as bold:
Document state: [bold(a, b, c)]Bob (concurrent edit) inserts "x" between b and c:
Document state: [bold(a, b), x, bold(c)]?
OR [bold(a, b), x, bold(c)] with x outside bold?
What the user intended is for x to be bold. It was inserted inside the bold range. Classic text CRDTs couldn't easily express this because their operation set was character-level inserts and deletes, not range-level format intents.
Rich-text OT (Quill Delta, used in Google Docs since 2010 and in Taskade Projects today) solved this in 2009 by treating format ranges as a separate operation type with explicit transform rules.
Peritext, published November 2022 by Geoffrey Litt, Jason Lim, Martin Kleppmann, and Peter van Hardenberg at Ink & Switch, closed the gap. Peritext encodes formatting intentions as range anchors (start and end markers tied to specific character IDs) and uses operation-based merge logic that preserves the user's intent in the bold/italic/heading boundary cases.
Peritext is a major step toward production rich-text CRDT. Production deployment is still in early days as of 2026, Automerge 3.x integrated Peritext, and Yjs has its own rich-text approach via Y.Text. But the algorithmic catch-up has now happened.
🛠️ The Production CRDT Stack in 2026
The mature CRDT ecosystem:
| Library | Primary use | Notable adopters |
|---|---|---|
| Yjs | Text + shared types; ergonomic JS API | Tiptap, Hocuspocus, BlockSuite, JupyterLab, Outline, Logseq |
| Automerge | JSON CRDT + Peritext rich-text | Local-first apps, research projects, Ink & Switch ecosystem |
| Diamond Types | Pure-text CRDT optimized for performance | Research, perf-sensitive use cases |
| Loro | Modern Rust + WASM CRDT | Newer ecosystem, gaining traction |
| Y-CRDT (yrs) | Rust port of Yjs | Mobile and embedded applications |
| Liveblocks Storage | Sync-as-a-service with CRDT primitives | SaaS apps not building from scratch |
| Apple Notes Sync | Internal CRDT for cross-device notes | Apple ecosystem |
| Linear sync engine | Custom CRDT-like for issue tracking | Linear users |
| Figma multiplayer | Custom LWW tree (CRDT-ish) | Figma users |
Yjs vs Automerge vs Loro vs Diamond Types: the head-to-head
| Library | Algorithm family | Memory per op (approx) | Network overhead | Rich-text strategy | Production users (2026) |
|---|---|---|---|---|---|
| Yjs | YATA + delta CRDT | ~30 bytes baseline; tombstones grow | Compact CBOR-like binary; ~2× plaintext on insert-heavy workloads | Y.Text with delta intents | Tiptap, BlockSuite, Logseq, JupyterLab |
| Automerge 3 | RGA + Peritext for text | ~50 bytes / op; columnar compression cuts cold-storage size 4-10× | JSON-compatible binary; supports incremental sync via heads | Peritext range-anchor model | Ink & Switch projects, local-first apps |
| Loro | YATA-inspired, Rust + WASM | ~25 bytes / op, tombstone GC on full acknowledgment | Compact binary; partial-tree fetch supported | Loro Text type with intent preservation | Loro Cloud, growing OSS adopters |
| Diamond Types | RLE-encoded position-based | ~12 bytes / op on text-heavy workloads (best in class) | Tiny — run-length encoded ops on the wire | Plain text only as of 2026 | Joseph Gentle's benchmarks, perf-critical use cases |
| Obsidian Sync | Internal CRDT for note sync | Obsidian users |
A CRDT category that did not exist commercially in 2014 now has more than a dozen production-grade implementations across multiple languages.
🤖 Where CRDTs Sit in the AI-Agent Era
CRDTs are perfect for workloads where:
- Multiple devices need to sync without a server arbitrating every keystroke
- Offline work is expected and important
- Local-first is a product value (data ownership, privacy, longevity)
- Peer-to-peer trust is the model (no central authority needed)
- The document shape is a tree of structured objects (Figma's design tree) or independent JSON shapes
CRDTs are less ideal for workloads where:
- Central server already exists for auth, billing, AI inference, durable execution
- AI agents are first-class participants and live server-side
- Audit trail and permissioning are core (linearized server-side logs are easier)
- Wire format budget is tight (CRDTs carry IDs, origins, vector clocks, tombstones)
- Rich-text fidelity requires 15+ years of production maturity that OT has
This is why Taskade Projects chose Operational Transformation, see our OT vs CRDT deep-dive for the full reasoning. Same workspace can have humans, Custom Agents v2, the meta-agent EVE, and 100+ integrations all submitting changesets to one central OT engine.
📊 OT vs CRDT vs Hybrid: The 2026 Workload Scorecard
Picking a sync substrate is a workload bet, not a religion. Here is how the four most-deployed real-time stacks compare across the dimensions that actually matter for AI-agent workspaces:
Picking a sync substrate is a workload bet, not a religion. Here is how the four most-deployed real-time stacks compare across the dimensions that actually matter for AI-agent workspaces:
| Capability | Taskade Genesis (OT) | Google Docs (OT) | Linear (CRDT-style) | Figma (custom tree-CRDT) |
|---|---|---|---|---|
| Sync engine | OT (ot-json0 + Quill Delta + Text0 subtypes) |
OT (proprietary, Wave-derived) | Custom sync engine with delta pulls (CRDT-ish) | LWW-Register per object property |
| Lineage receipt | Aaron Iba on cap table · ot-json0 from Joseph Gentle (ex-Wave) |
Built by ex-Wave engineers | Built in-house | Built in-house |
| Offline-first | No (server-mediated by design) | Partial (offline edits queue) | Yes (full local cache) | Partial |
| AI agents as co-editors | Custom Agents v2 + meta-agent EVE editing the OT stream | Gemini sidebar (assistive, not a co-editor) | None native | None native |
| Built-in automations | 100+ bidirectional integrations · Temporal durable execution · triggers pull events in, actions push data out | None native | Limited (Linear webhooks) | None |
| Memory persistence | Workspace DNA · Memory → Intelligence → Execution loop · agents accumulate expertise across sessions | Per-doc only | Per-issue only | Per-file only |
| Rich-text fidelity | 15+ years OT maturity via Quill Delta | 15+ years OT maturity | N/A (issue tracker) | N/A (design tool) |
| Project views | 7: List · Board · Calendar · Table · Mind Map · Gantt · Org Chart (Timeline lives inside Gantt) | 1 (document) | List + Kanban + Timeline + Roadmap | Canvas |
| RBAC | 7 tiers: Owner · Maintainer · Editor · Commenter · Collaborator · Participant · Viewer | 3 tiers | 4 tiers | 4 tiers |
| Clone the app | Genesis Apps · 150K+ in Community Gallery · clone in 60 seconds | Docs templates | None | Community files |
| MCP both sides | Yes — Taskade-as-Server (Claude Desktop / Cursor / VS Code) + Taskade-as-Client (external Notion / Linear) | No | No | No |
| Models | 15+ frontier models from OpenAI, Anthropic, Google plus open-weight providers, auto-routed by plan | Gemini only | None | None |
| Pricing (paid entry) | $6/mo Starter · $16/mo Pro · $40/mo Business | $7/mo Workspace Business Starter | $8/mo Standard · $14/mo Plus | $12/mo Professional · $45/mo Organization |
The pattern: CRDT-first products (Linear, Figma) win at offline-first and peer-to-peer; OT-first products (Google Docs, Taskade Genesis) win at server-mediated rich-text plus AI-agent participation. The Aaron Iba lineage is what makes the Taskade column architecturally legible, same OT conviction Iba carried through Etherpad and Google Wave, now carrying agents on the wire.

🧬 Taskade Genesis: The Workspace Where OT Hosts AI Agents
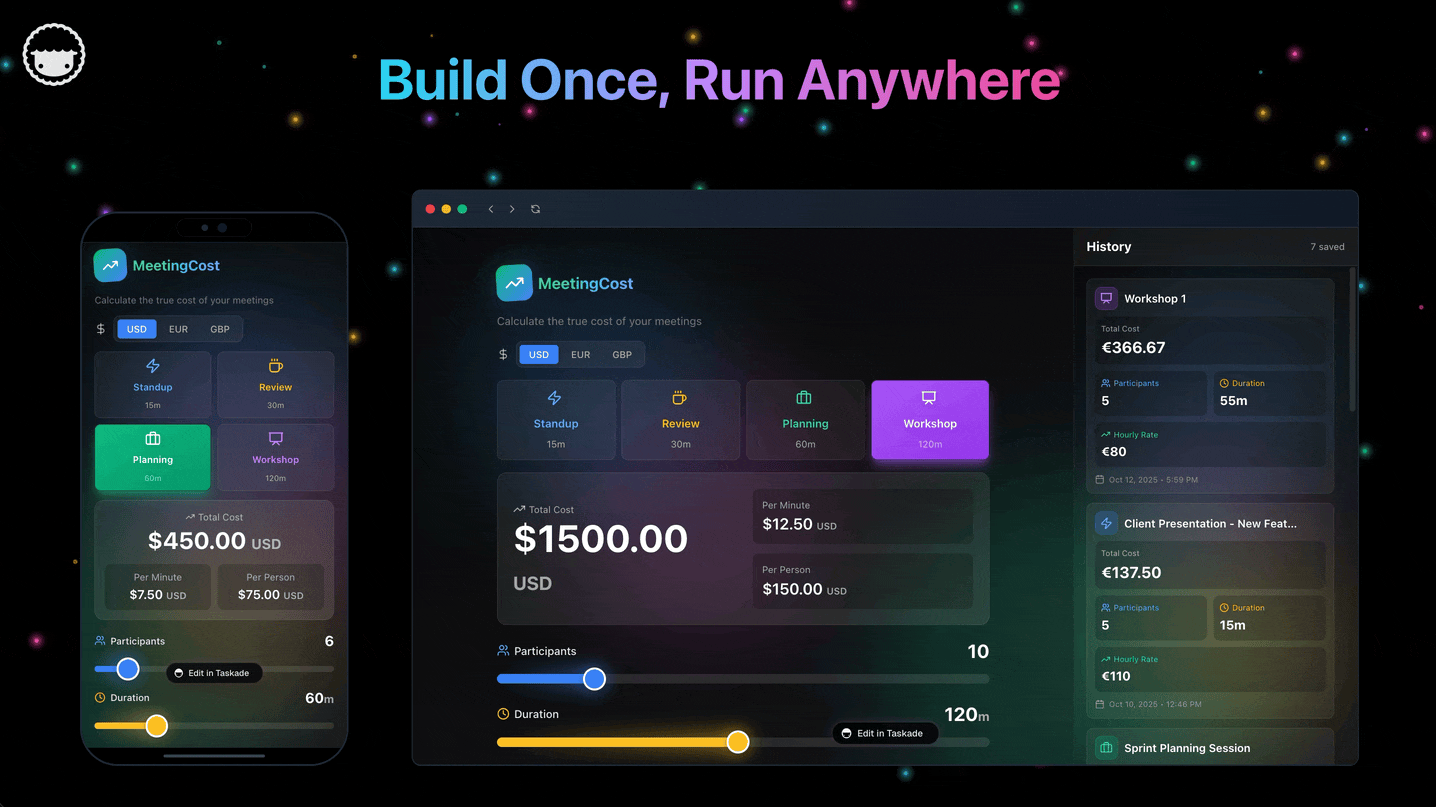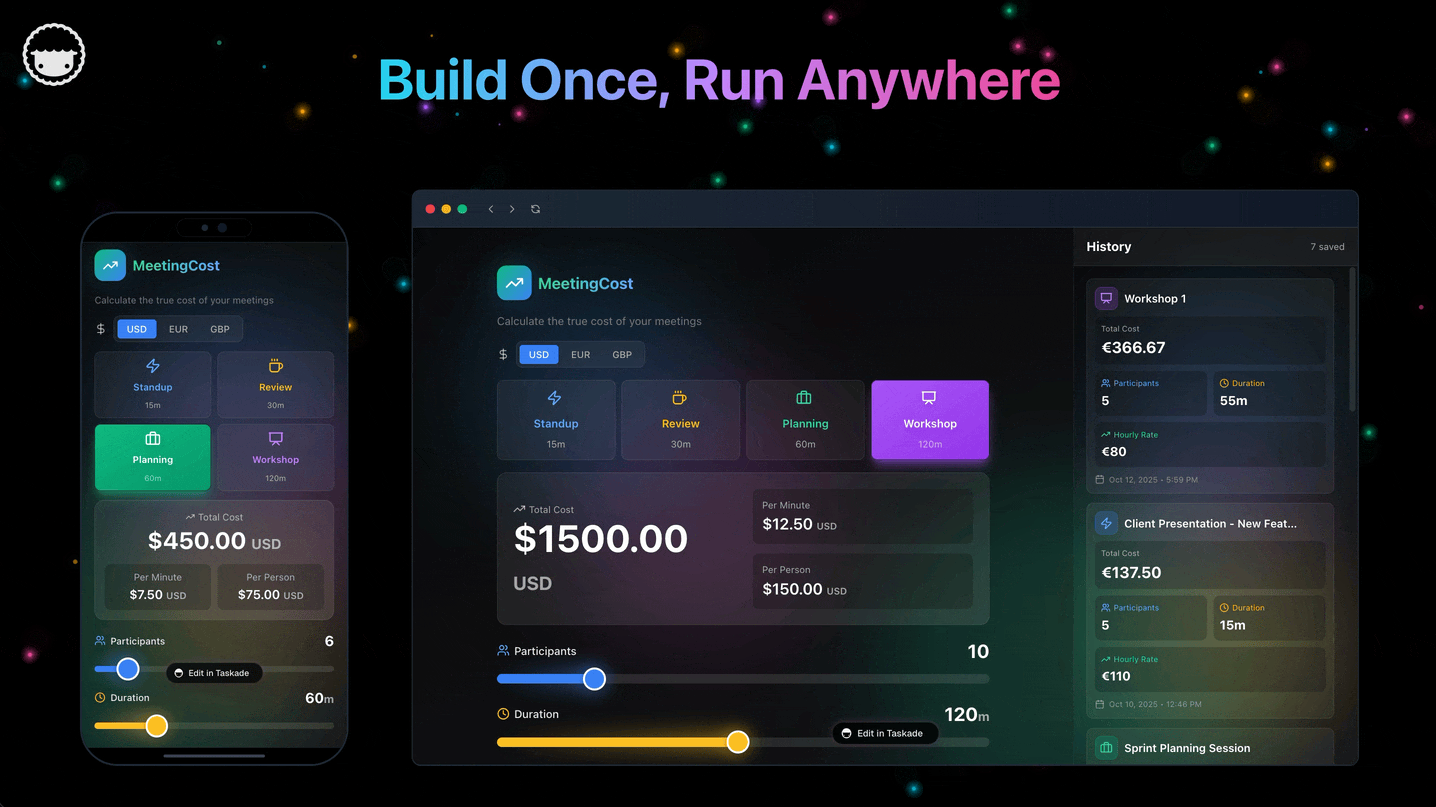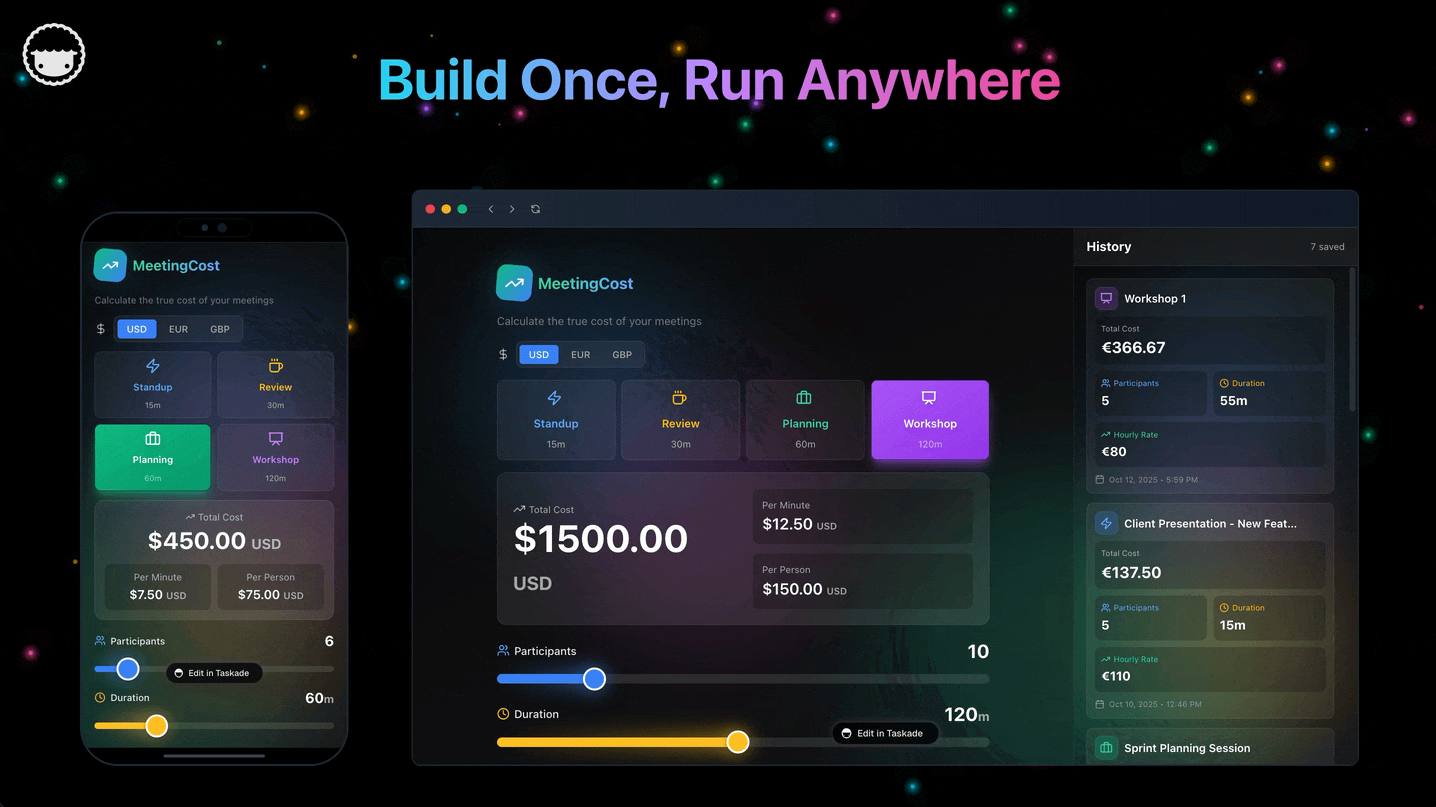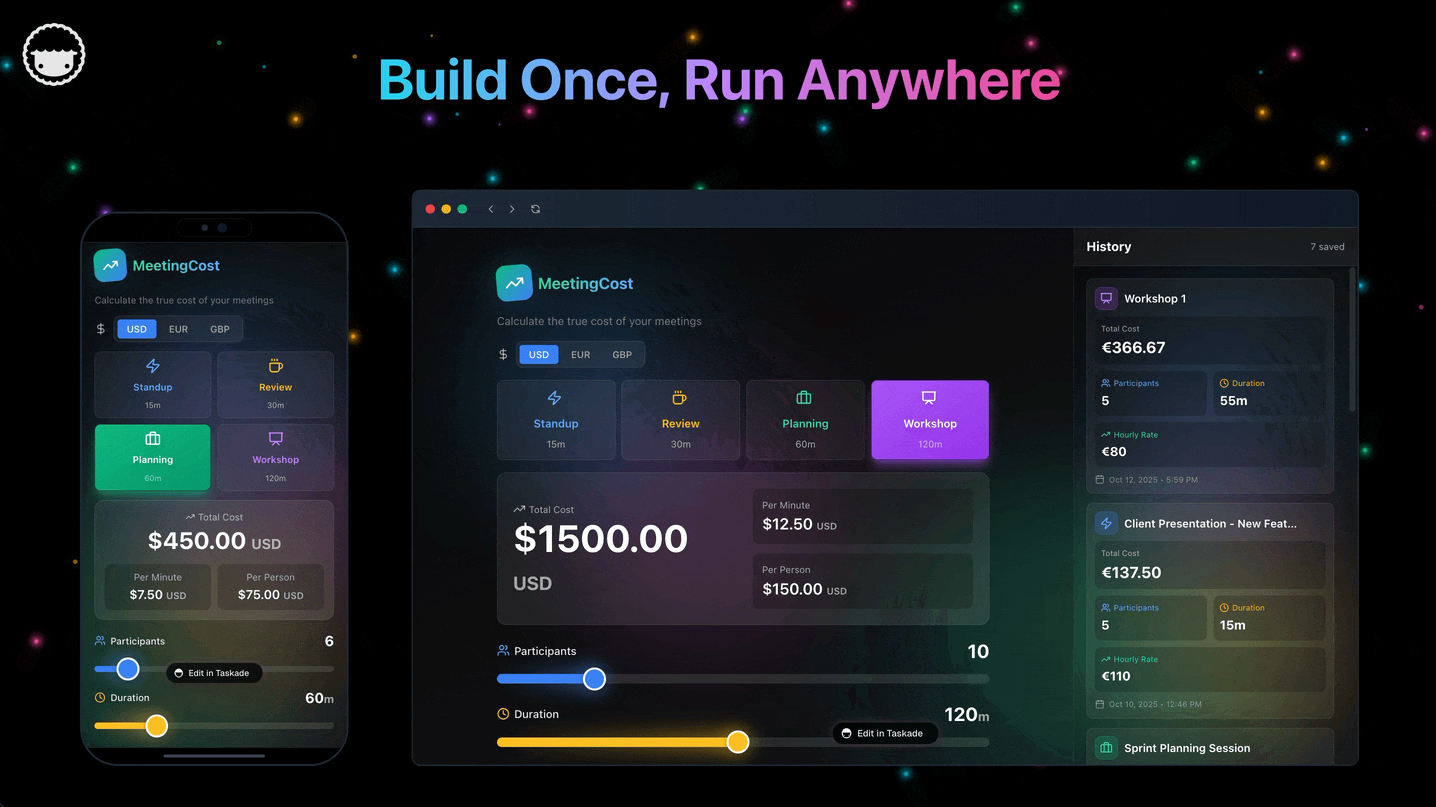
Genesis Capability Map: From the May 2026 Newsletters
| Newsletter chapter | What Taskade ships |
|---|---|
| Workspace Memory · Mind Graph | Workspace-scoped knowledge graph |
| Agent Workflows · Tools Wired | 34 built-in tools + 100+ bidirectional integrations |
| App Payments · Stripe Live | Native Stripe Checkout actions |
| Frontier Models · Auto-Routed | Frontier models from OpenAI, Anthropic, Google + open-weight |
| Embed Apps · Anywhere | Genesis Apps embed as responsive widgets on any site |
| Clone Apps · Instantly | 150,000+ apps in the Community Gallery; clone in 60 seconds |
Plus vibe coding · vibe payments · vibe workflows · vibe marketing · vibe tracking and MCP both sides. 198 platform releases in 2026.
Taskade's choice is not "OT good, CRDT bad". It's "OT is the right substrate for AI-agent workspaces." Taskade Genesis demonstrates what's possible when the substrate is OT-driven and the participant class is multiplied:
- Workspace DNA loop: Memory (Projects) feeds Intelligence (Agents), Intelligence triggers Execution (Automations), Execution writes back to Memory. All running through the OT engine.
- EVE, the meta-agent reading entire workspace DNA, orchestrating across Memory + Intelligence + Execution + Media
- 33 built-in agent tools, web search, file editing, image generation, slash commands, web fetch, project read/write, agent-to-agent, MCP tool calling
- 100+ bidirectional integrations: Slack, Stripe, Notion, GitHub, Shopify, Salesforce, Calendar, Linear, Monday, Airtable, Telegram, RSS, Webhooks
- MCP both sides: Taskade-as-Server (Claude Desktop / Cursor / VS Code drive your workspace) and Taskade-as-Client (your agents call external Notion / Linear / Salesforce MCP servers)
- Vibe Coding · Vibe Payments · Vibe Workflows · Vibe Marketing · Vibe Tracking, natural-language descriptions compile to OT changeset patterns
150,000+ Genesis apps built since launch. 3M+ automations executed.
CRDTs solved the data-sync layer. Cloud computing solved the compute layer. Both had to mature before workspace-native software was possible. For the parallel sixty-year arc of how compute became a utility, IBM CP-40 (1964) → AWS (2006) → Docker (2013) → Kubernetes (2015) → Lambda (2014) → AI compute (2022+), see The History of Cloud Computing. The workspace runs on top of both stacks.
The two histories are co-dependent:
| Year | CRDT / sync milestone | Cloud / compute milestone |
|---|---|---|
| 1978 | Lamport's logical clocks | (Mainframe timesharing already 14 years old) |
| 2001 | (Bayou replication papers) | VMware ESX 1.0 |
| 2006 | WOOT — first text CRDT | AWS S3 + EC2 launch |
| 2011 | Shapiro CRDT paper | AWS GovCloud, Heroku acquired |
| 2014 | Riak DT production CRDTs | AWS Lambda (serverless born) |
| 2016 | Yjs / YATA | Cloudflare Workers preview |
| 2022 | Peritext (rich-text CRDT) | ChatGPT (AI compute begins) |
| 2026 | OT-driven AI-agent workspaces | Workspace-native software era |
The workspace needs both, a sync substrate that handles many humans + many agents editing the same memory, and a compute substrate that makes per-token, per-agent, per-branch cost negligible. Take either away and the seventh era stops working.
For local-first or peer-to-peer or pure-offline products, CRDTs are likely the right substrate. For an AI-agent workspace where the agents themselves are server-side participants and rich-text fidelity matters, OT is the right call, and Taskade is the production proof.
🔮 What's Next: 2026–2030
| Direction | What changes |
|---|---|
| Rich-text CRDTs mature | Peritext-style algorithms become production-grade across libraries |
| Hybrid OT+CRDT | Linear-style, Notion-style hybrids become the dominant pattern |
| CRDT-on-database | SQLite + CRDT, PostgreSQL + CRDT extensions for distributed apps |
| Local-first AI agents | On-device models edit locally, sync via CRDT to server-side agents on OT |
| MCP-aware sync | The agent-tool protocol becomes substrate-agnostic; OT or CRDT underneath is implementation detail |
| Sync-as-a-service | Liveblocks, PartyKit, Replicache abstract OT/CRDT choice away from app developers |
The next decade is convergence on the strengths of both, not a winner.
🔗 Further Reading
- OT vs CRDT: The Two Algorithms Behind Every Real-Time App, the engineering deep-dive companion
- History of Real-Time Collaboration: From Engelbart to AI Agents, the pillar piece
- Google Wave Lessons, the OT side of the lineage
- History of Etherpad, Aaron Iba's OT-based predecessor
- History of Lotus Notes, the replication side of the 1989 fork
- Joseph Gentle, "I was wrong. CRDTs are the future"
- Joseph Gentle, "CRDTs go brrr"
- Shapiro et al., Conflict-free Replicated Data Types (INRIA RR-7687)
- Local-First Software (Ink & Switch, 2019)
- Peritext, Rich-Text CRDT (Ink & Switch, 2022)
- crdt.tech bibliography
- Yjs · Automerge · Diamond Types
❓ Frequently Asked Questions
What does CRDT stand for?
Conflict-free Replicated Data Type. Coined by Marc Shapiro and colleagues at INRIA in May 2011 (technical report RR-7687, followed by SSS 2011 conference paper).
Are CRDTs only for text editing?
No. The original Shapiro 2011 paper enumerated counters, sets, maps, registers, and sequences. Yjs and Automerge support JSON-like structures with maps and lists. Figma uses a custom tree-CRDT for design objects. CRDTs work for any data shape where eventual consistency is acceptable and you can define commutative-associative-idempotent merge semantics.
Is Yjs faster than Automerge?
Historically, Yjs was faster for text workloads; Automerge had a richer JSON model but traded some performance for it. Automerge 3.x (2024-2025) closed much of the gap with columnar storage and Peritext integration. For new projects in 2026, choose Yjs if your primary need is text + shared types with ergonomic JavaScript and the deepest production ecosystem (Tiptap, Hocuspocus, BlockSuite); choose Automerge if you need a rich JSON CRDT with explicit local-first design and strong rich-text via Peritext.
What is Diamond Types?
Joseph Gentle's text CRDT, written in Rust and JavaScript. Diamond Types achieved roughly 5,000× speedups over earlier CRDTs through columnar encoding and B-tree internal structure. It's influential because Gentle is one of the few people who has shipped both OT and CRDT at scale, and his benchmarks shifted practitioner opinion. Diamond Types is not yet as widely deployed as Yjs but is a leading research-grade implementation.
Should I use CRDTs for my new app?
If you need peer-to-peer, offline-first, or local-first behavior, yes. If you need a server-mediated workspace with AI agents, audit trails, and rich-text fidelity, likely OT. If you're not sure, use a sync-as-a-service like Liveblocks which gives you both primitives. The honest answer is: pick by workload shape, not algorithmic religion.
Can CRDTs handle rich text now?
Yes, as of Peritext (2022) and its integration into Automerge 3.x and Yjs's Y.Text. Production deployment is still earlier than OT-based rich text (Quill Delta / Google Docs have 15+ years of production maturity), but the algorithmic catch-up has happened.
How does CRDT garbage collection work?
Tombstoned characters and operations are retained in the CRDT state as anchors for potentially-delayed remote operations. Periodic garbage-collection passes identify tombstones that no causally-newer operation could possibly reference (typically because all replicas have observed the deletion's causal predecessors) and remove them from storage. Garbage collection is one of the operationally complex parts of running a production CRDT, and one of the reasons CRDT wire formats are larger than OT's.
Why does Taskade use OT instead of CRDT?
Four reasons: (1) AI agents are server-side clients with no offline-merge problem; (2) rich-text needs OT's 15-year maturity advantage; (3) permission enforcement is simpler against a linearized op stream; (4) wire format economics favor OT for short ops. Plus the Aaron Iba lineage receipt, Etherpad co-founder, ex-Google Wave engineer, now a Taskade angel investor. Same architectural conviction across eighteen years.
Where can I learn more about CRDT theory?
Start with: Lamport's 1978 logical-clocks paper for foundations; Shapiro 2011 INRIA RR-7687 for the formal CRDT definition; Kleppmann's "Designing Data-Intensive Applications" Chapter 5 for the practitioner's distributed-systems context; the Ink & Switch 2019 local-first essay for the philosophy. After that, the crdt.tech bibliography is the canonical reading list. Joseph Gentle's blog posts at josephg.com/blog are the most-cited practitioner writing.
What is Taskade Genesis and where does it fit?
Taskade Genesis is the AI-native workspace platform that turns one prompt into a live app in seven minutes, built on Taskade's OT-driven Project editor (using ot-json0, the open-source descendant of the Google Wave OT engine). It demonstrates what happens when an OT substrate hosts not just humans but also AI agents, automations, and external MCP clients on the same stream. 150,000+ apps built since launch.