






Last updated: July 1, 2026. Refreshed monthly.
"Open models cannot be just open. They have to be great."
, Zhilin Yang, Moonshot AI (Kimi K2.5 GTC 2026 keynote)
Open-source AI LLMs grew up in 2026. The gap with premium frontier models on everyday work is now single-digit percentage points, while the credit cost is often 4 to 10 times cheaper. For real work, that math matters.
This guide ranks the 10 open-source LLMs that ship real work in July 2026, what each is best for, the benchmark numbers worth knowing, the self-host TCO math, the license risk decoder, the new architectures behind the 2026 jump (Muon, Kimi Linear, attention residue), and how to mix all of it inside Taskade Genesis without touching infrastructure.
TL;DR: The strongest open-source LLMs in July 2026 are GLM-5.2 (the new #1: MIT license, 1M context, GPQA Diamond 91.2%), Kimi K2.7 Code (agentic coding, +21.8% over K2.6), DeepSeek V4 Pro (code, math, MIT), MiniMax M3 (SWE-bench Pro 59.0%, 1M context, native multimodal), Qwen 3.6 (multilingual, Apache 2.0), MiniMax abab (bulk processing), Meta Llama 4 (community fine-tunes, 10M context), Mistral Large 3 (European languages, compliance), Cohere Command R+ (retrieval and RAG), and Microsoft Phi-4 (small, fast, on-device). Taskade Genesis gives you all ten through one picker with credit cost shown per generation. Mix providers in one workspace. No rebuilds when a new model ships.
What Changed Since May 2026
Four dated moves reshaped this ranking since the May edition:
- June 12, 2026 — Moonshot shipped Kimi K2.7 Code: +21.8% over K2.6 on Kimi Code Bench v2, plus a HighSpeed variant with ~6× faster inference.
- June 13, 2026 — Zhipu released GLM-5.2; MIT weights landed on Hugging Face around June 17. The new #1.
- June 2026 — MiniMax M3 posted 59.0% on SWE-bench Pro, the top open-weight score.
- May 19, 2026 — Qwen 3.7 Max shipped API-only. It is not open-weight. The open Qwen line is Qwen 3.6 (April 2026, Apache 2.0).
▲ ■ ● The Quick Read
Three lines. Then dig deeper if you want.
▲ Open-source LLMs in 2026 are good enough for 90% of real work.
■ The other 10% still wants premium frontier models.
● Taskade Genesis routes both. One picker. One credit system. One workspace.
That is the whole article. Everything below is the rationale, the rankings, and the patterns that work.
Quick Comparison Table (Ranked)
The table you came here for. Sorted by what each model wins at.
| # | Model | Provider | License | Arch | Context | Headline benchmark (as of Jul 2026) | Best for | Credit cost |
|---|---|---|---|---|---|---|---|---|
| 1 | GLM-5.2 | Z.ai (Zhipu) | MIT | MoE (~753B) | 1M | GPQA Diamond 91.2% | Broad reasoning, long-horizon code | Low |
| 2 | Kimi K2.7 Code | Moonshot AI | Modified MIT | MoE (1T) | 256K | +21.8% vs K2.6 (Kimi Code Bench v2) | Agentic coding | Low |
| 3 | DeepSeek V4 Pro | DeepSeek AI | MIT | MoE (1.6T/49B) | 1M | SWE-bench Verified 80.6% | Code, math, structured output | Very low |
| 4 | MiniMax M3 | MiniMax | Open-weight | MoE, native multimodal | 1M | SWE-bench Pro 59.0% (open-weight top) | Long docs, multimodal agents | Very low |
| 5 | Qwen 3.6 | Alibaba | Apache 2.0 | MoE (35B-A3B) + 27B dense | — | 700M+ family downloads | Multilingual, cheap self-host | Low |
| 6 | MiniMax abab | MiniMax | Custom | MoE | 256K | SWE-bench Verified ~70% | Bulk processing, classification | Very low |
| 7 | Llama 4 Scout | Meta | Llama 4 Community | Dense (109B / 16E) | 10M | SWE-bench Verified ~70% | Long-context, tool calling | Low |
| 8 | Mistral Large 3 | Mistral AI | Apache 2.0 | MoE (675B/41B) | 128K | SWE-bench Verified ~73% | European languages, compliance | Medium |
| 9 | Cohere Command R+ | Cohere | CC-BY-NC 4.0 (weights) | Dense | 128K | SWE-bench Verified ~68% | Retrieval, RAG, citations | Low |
| 10 | Microsoft Phi-4 | Microsoft | MIT | Dense (14B) | 16K | SWE-bench Verified ~55% | Small, fast, on-device | Lowest |
Three numbers worth committing to memory.
✓ MiniMax M3 holds the top open-weight SWE-bench Pro score at 59.0% (as of July 2026), edging past the record Kimi K2.6 set in April at 58.6% — a score that led every premium frontier model at release, including GPT-5.4 (57.7), Claude Opus 4.6 (53.4), and Gemini 3.1 Pro (54.2).
✓ GLM-5.2 scored 91.2% on GPQA Diamond (June 2026 release) and matches or beats GPT-5.5 on long-horizon coding at roughly 1/6 the cost. Open-source caught up on graduate-level reasoning — under an MIT license.
✓ Qwen family crossed 700M Hugging Face downloads in January 2026 with 113,000+ derivative models. The most-downloaded open model family ever.
Benchmark numbers are the latest published scores from each provider's model card as of July 2026. Treat them as direction, not gospel. Run the model on your own work for the real answer.
Every one is available in the Taskade Genesis model picker. Hover an option, the exact credit cost appears in the tooltip. The cost in the tooltip is the cost on your usage page.
Why Open-Source LLMs Matter in 2026
The 2024 narrative said premium frontier models would stay one full generation ahead of open-source forever. The 2026 reality is more nuanced.
reasoning code long-ctx multilingual cost
premium models ████ ███ ███ ███ $$$
open-source 2026 ███▌ ███ ████ ███▌ $
open-source 2024 ██▌ ██ ██ ██ $
Three reasons the gap narrowed.
✓ The compute moat shrank. Mixture-of-experts architectures and better training data closed most of the quality gap at a fraction of the parameter count.
✓ The open community ships faster. Frontier-class open-weight releases shipped nearly every month through the first half of 2026 — three in June alone (Kimi K2.7 Code, GLM-5.2, MiniMax M3).
✓ The use cases changed. Real production workloads are 80% routine and 20% hard. Open-source handles the routine 80% beautifully.
The right mental model in 2026 is portfolio, not pick-one. Use premium models for the hardest 20%. Use open-source for the routine 80%. Taskade Genesis makes that mix one click.
MoE vs Dense: Why the 2026 Champions Are All MoE
Seven of the ten top open-source models are Mixture-of-Experts (MoE). Three are dense. The split is not an accident. MoE is what makes the cost-per-quality math work at scale.
In plain terms.
✓ Dense loads every parameter for every token. Predictable, well-understood, slower per parameter.
✓ MoE loads only the experts the router picks. Same model card, a fraction of the active compute per token.
The practical result is a Kimi K2.7 Code with 256K token context and very low credit cost (research builds extend further on Kimi Linear), or a DeepSeek V4 with frontier-level code performance at 1/4 the active parameters of a comparable dense model. MoE is why 2026's open-source champions punch above weight class.
| Architecture | Total params | Active per token | Speed | Cost |
|---|---|---|---|---|
| Dense (Llama 4 Scout, Phi-4, Command R+) | All loaded | All active | Lower throughput | Higher per token |
| MoE (GLM, Kimi, DeepSeek, MiniMax, Qwen, Mistral) | Larger total | ~10-15% active | Higher throughput | Lower per token |
For builders inside Taskade Genesis, this is mostly invisible. The model picker shows the credit cost. Auto mode picks the right architecture per task. But understanding the why behind the prices helps you reason about which model to override on a hot path.
Self-Host TCO vs Taskade Genesis Gateway
The other math you came here for. If you were going to run these models yourself, what would the real cost look like? And how does that compare to running them through the Taskade Genesis managed gateway?
Rough self-host total cost of ownership per million tokens, including GPU rental at mid-2026 market rates (A100 80GB ~$1.50/hr, H100 ~$3/hr, M3 Max local ~$0.05/hr amortised):
| Model | Min VRAM | GPU class | Tokens/sec | $/M tokens (self-host) | Taskade Genesis |
|---|---|---|---|---|---|
| Phi-4 | 12 GB | Consumer / M3 Max | 80 | ~$0.20 | Lowest credit cost |
| Qwen 3.6 35B-A3B (MoE, ~3B active) | 24 GB | Consumer / A100 40 | 95 | ~$1.50 | Low |
| Mistral Large 3 | 48 GB | A100 80 | 60 | ~$7.00 | Medium |
| Llama 4 Scout | 64 GB | A100 80 / H100 | 55 | ~$15.00 | Low |
| DeepSeek V4 Pro (MoE) | 96 GB | H100 / 2× A100 | 90 | ~$8.00 | Very low |
| Kimi K2.7 Code (MoE, 256K ctx) | 128 GB | 2× H100 | 40 (~6× on HighSpeed) | ~$18.00 | Low |
| GLM-5.2 (MoE, ~753B, 1M ctx) | 384+ GB | 8× H100 node | 30 | ~$25.00 | Low |
What this table is saying.
✓ Self-hosting is genuinely cheaper than premium frontier APIs. Not genuinely cheaper than a managed gateway for most teams under ~5M tokens per month.
✓ The break-even for self-hosting is roughly 10M tokens per month on a single model. Below that, the managed gateway wins on every dimension except control.
✓ Open-source on a managed gateway gets you the cost benefit (4-10× cheaper than premium) without the operational tax of running the inference stack.
The Taskade Genesis math is simpler. Open the picker. See the credit cost. Run the prompt. Pay the credits.
License Risk Decoder
The part no one explains in plain language. Here is what each license actually means for your business.
| License | Commercial use | Redistribute fine-tunes | EU AI Act risk | Plain-language take |
|---|---|---|---|---|
| MIT (GLM-5.2, DeepSeek V4, Phi-4) | ✓ Yes | ✓ Yes | Low | Use anywhere. Redistribute fine-tunes. Cleanest commercial story of any top-tier 2026 model. |
| Modified MIT (Kimi K2.7 Code, Kimi K2.6) | ✓ Yes | ✓ Yes | Low | MIT plus an attribution clause that only kicks in at very large scale. Read the clause before shipping a mass-market product. |
| Apache 2.0 (Mistral Large 3, Qwen 3.6) | ✓ Yes | ✓ Yes | Low | Full commercial use. No MAU cap. No revenue gate. |
| Llama 4 Community License | ✓ Yes (under 700M MAU) | ✓ Yes | Medium | 700M MAU cap is measured against the entire corporate entity in the calendar month before April 2025, not today. Outputs cannot train competing models. |
| Cohere CC-BY-NC 4.0 (Command R+ weights) | ✗ via weights | ✗ Restricted | Low | Free via Cohere API or partners only. Weights are research-only. |
| MiniMax terms (M3, abab) | ✓ Yes (with limits) | Check terms | Medium | Open-weight releases under custom terms. Read the license. Some clauses restrict competing services. |
Qwen 3.7 Max: API-only for now — open-weights watch. Alibaba shipped Qwen 3.7 Max on May 19, 2026 as a proprietary, API-only model. No Qwen 3.7 weights had appeared on Hugging Face as of mid-June 2026. Any page calling Qwen 3.7 Max "open-source" is wrong. The open-weight Qwen line is Qwen 3.6 (35B-A3B MoE, April 17; 27B dense, April 23 — both Apache 2.0). If Max-tier weights ship, this section will say so.
The two-question rule for any open-source LLM you ship in production.
- Can I use the weights or only the API? MIT/Apache 2.0 = weights are yours (GLM-5.2, DeepSeek V4, Qwen 3.6, Mistral Large 3, Phi-4; Kimi K2.7 Code under Modified MIT). Cohere weights = research only. Qwen 3.7 Max = API only.
- Can I redistribute a fine-tune? MIT/Apache = yes. Llama = yes under the 700M MAU cap measured at the parent corporate entity in April 2025 (frozen, not rolling). Cohere = no for the weights.
For most teams, MIT-licensed models (GLM-5.2, DeepSeek V4 Pro, Phi-4 — plus Kimi K2.7 Code under Modified MIT) are the cleanest commercial-use story in 2026. Inside Taskade Genesis the license question is handled at the gateway level. You can use any of the ten without dealing with redistribution rules.
How K2.5 Got Great: Three Scaling Dimensions Worth Stealing
The clearest signal that open-source LLMs are no longer playing catch-up in 2026 is Kimi K2.5. The architecture is so good that Moonshot AI's founder, Zhilin Yang, walked through it at GTC 2026 as three independent scaling dimensions, each delivering a multiplier on the next.
Worth understanding the shape of it. Most listicles skip this. We won't.
▲ Dimension 1: Token Efficiency (Muon optimizer)
Yang's team replaced AdamW (the 2014 default) with the Muon optimizer, the first scaled production use of Muon in LLM history. Result: 2× token efficiency. 50 trillion high-quality tokens behave like 100 trillion.
That sounds like infrastructure. It isn't.
"Token efficiency is not just about efficiency. It is actually about improving the upper bound of intelligence... we are hitting the data wall and the amount of high-quality data is quite limited."
, Zhilin Yang, GTC 2026
When training data is finite, doubling token efficiency doubles the ceiling. The technical wrinkle that made this work at 1 trillion parameters: QK-Clip. Without it, max logits exploded past 1,000 (normal: ~50). With it, training curves look identical, training stays stable.
■ Dimension 2: Context Length (Kimi Linear)
Kimi Linear is a new attention architecture. 1:3 ratio of full attention to Kimi Delta Attention layers, with a per-channel decay matrix instead of a scalar. The result is the first architecture to outperform full attention on all three axes at once: short context, long input, long output.
For builders, this is the architecture that lets the Kimi K2.6 / K2.7 Code line hold its 256K production window, and Kimi Linear research builds push toward 2M, without falling apart at the back of the prompt. Long context that actually reasons.
● Dimension 3: Agent Swarms (Orchestrator + Sub-agents)
The third scaling dimension is not architectural. It is organisational.
Moonshot trains the swarm with three reward functions: an instantiation reward (so the orchestrator does not collapse to single-agent mode), a finish reward (so it does not spawn pseudo-tasks), and the standard outcome reward. Decayed over training.
This is precisely the shape of Multi-Agent Teams inside Taskade Genesis. Your orchestrator agent assigns work to sub-agents, each with its own model, tools, and memory. Results aggregate back. The open-source research is converging on the same pattern Taskade ships.
"This is one of the most beautiful curves I observed in my life... over 15 trillion tokens and the entire training process is just so stable. No loss spike."
, Zhilin Yang, on the K2.5 training run
The takeaway for builders. Architecture progress is no longer rare. Adam (2014), full attention (2017), residual connections (2016). all three got challenged successfully in 2026. The open community ships the next layer of the foundation while the closed labs argue about pricing.
A Short History of How We Got Here
A timeline of the open-source LLM movement, from the first weights drop to the 2026 inflection.
timeline
title Open-Source LLM Milestones 2022 to 2026
2022 : BLOOM released by BigScience
: First serious community-trained 176B model
2023 : LLaMA leaked, then released open
: Meta seeds the community fine-tune era
2024 : Mistral, Mixtral MoE released
: DeepSeek Coder hits parity with closed code models
: Qwen 2 lands as Chinese open-source flagship
2025 : Llama 3, DeepSeek V3, Qwen 2.5
: Kimi K2 ships 1M context window
: Open-weight reasoning models close the gap
2026 : DeepSeek V4, Kimi K2.7 Code, GLM-5.2, MiniMax M3
: 10 open-source picks live in Taskade Genesis
: Open-source crosses 50% of production prompts
In four years the open-source category went from research experiments to production default for most everyday workloads.
How the Ten Map to Your Workloads
Every team's workload distribution is different. Three common shapes, and which open-source pick fits each.
Now the deep dives, one model at a time.
1. GLM-5.2: The New Open-Source Frontier
Maker: Zhipu AI (Z.ai). Released: June 13, 2026, with MIT weights on Hugging Face around June 17. License: MIT. Architecture: MoE, ~753B total parameters. Context: 1 million tokens.
Benchmark snapshot (June 2026 release): GPQA Diamond 91.2% · matches or beats GPT-5.5 on long-horizon coding tasks at roughly 1/6 the cost.
GLM-5.2 is the reason this ranking has a new #1. Zhipu shipped it on June 13, 2026, published the weights under MIT about four days later, and the numbers hold up: 91.2% on GPQA Diamond and long-horizon coding results that match or beat GPT-5.5 at roughly one-sixth the cost. A frontier-class model with a 1 million token window and the cleanest license in the business is exactly what "open-source caught up" looks like.
The predecessor GLM-5 stays in the catalog as the budget workhorse. If your automation runs 1,000 times a month on drafts, titles, and summaries, GLM-5 still wins on pure price. GLM-5.2 is for the work you used to reserve for premium frontier models.
What it is great at
✓ Broad reasoning where you want a single open-source default
✓ Long-horizon coding and multi-step agent tasks
✓ Workflows that ingest long documents under 1M tokens
✓ Commercial deployments where the MIT license removes legal-review friction
Where it is not the best pick
- Bulk classification at scale (MiniMax abab and GLM-5 are cheaper)
- Tiny on-device deployments (use Phi-4)
Inside Taskade Genesis
Pick GLM-5.2 for any agent doing research, drafting, or routing decisions. Auto mode will reach for it as a sensible default for frontier-grade reasoning at open-source cost.
2. Kimi K2.7 Code: The Agentic Coding Champion
Maker: Moonshot AI. Released: June 12, 2026. License: Modified MIT (MIT plus an attribution clause that only applies at very large scale). Architecture: MoE, 1 trillion total parameters. Context: 256K tokens (same Kimi Linear stack as K2.6).
Benchmark snapshot (June 12, 2026 release):
- Kimi Code Bench v2: +21.8% over K2.6, the predecessor that took the agentic-coding crown in April
- HighSpeed variant: ~6× faster inference for latency-sensitive agent loops
- Predecessor Kimi K2.6 (April 20, 2026): SWE-bench Pro 58.6% — at release it led every frontier model, including GPT-5.4 (57.7), Claude Opus 4.6 (53.4), and Gemini 3.1 Pro (54.2)
Kimi K2.7 Code is the June 2026 successor to Kimi K2.6, the model that quietly took the agentic-coding crown from premium frontier labs in April. K2.7 Code specialises the line further: +21.8% over K2.6 on Kimi Code Bench v2, plus a HighSpeed variant running roughly 6× faster inference for agent loops where latency matters. It is the open-source pick when the work is "build something real with tools" rather than "answer a question in one turn." The architecture carries over from the most discussed stack in the 2026 open-source community (Muon optimizer + QK-Clip + Kimi Linear attention. see the K2.5 GTC keynote section above).
What it is great at
✓ Agentic coding. the sharpest open-source line on real software tasks (Kimi Code Bench v2, June 2026)
✓ Multi-tool tool calling with stable behavior across long trajectories
✓ Latency-sensitive agent loops on the HighSpeed variant (~6× faster inference)
✓ Long-context tasks up to 256K with quality holding to the end of the window
Where it is not the best pick
- Whole-codebase prompts over 256K tokens (use Llama 4 Scout's 10M window or MiniMax M3's 1M window for ingest, then hand off to Kimi)
- Broad non-coding reasoning (GLM-5.2 is the stronger generalist)
Inside Taskade Genesis
Set Kimi K2.7 Code as the default model on any agent that needs to drive multi-step tool use. code editor agents, sales-outreach agents, multi-stage research agents. Combine with Workspace DNA Memory for the structured-context layer. Memory holds the long history. Kimi handles the active reasoning.
3. DeepSeek V4 Pro: The Code and Math Champion
Maker: DeepSeek AI. Released: April 24, 2026. License: MIT (clean commercial use, no MAU clause). Architecture: MoE, 1.6T total / 49B active. Context: 1 million tokens. Sibling: V4-Flash at 284B total / 13B active for cost-sensitive tiers — also MIT, same 1M-token window.
Benchmark snapshot: SWE-bench Verified 80.6% (April 24, 2026 release card — still the top published open-source SWE-bench Verified score as of July 2026). DeepSeek R1 remains the most-liked model in Hugging Face history.
DeepSeek V4 Pro is the open-source model engineers reach for when the work is code or quantitative. The DeepSeek line has topped open-source code benchmarks since 2024, and V4 closes the gap with premium reasoning models while staying dramatically cheaper. V4 introduces Compressed Sparse Attention, running at 27% of V3.2's FLOPs and 10% of the KV-cache memory.
What it is great at
✓ Code generation, refactoring, and code review across 30+ languages
✓ Mathematical reasoning, formula extraction, financial modelling
✓ Structured data extraction from messy inputs
✓ High-volume runs where credit cost matters
Where it is not the best pick
- Whole-codebase prompts beyond 1M tokens (use Llama 4 Scout's 10M window)
- Multimodal tasks (text-only; use MiniMax M3)
Inside Taskade Genesis
Pair DeepSeek V4 Pro with Taskade EVE for code-heavy work. When you connect Claude Desktop or Cursor through the Taskade MCP Server, the workspace-side code-edit step routes through DeepSeek. The result is a coding pipeline where the IDE handles the conversation and the workspace handles the file edits.
4. MiniMax M3: The Open-Weight SWE-bench Pro Leader
Maker: MiniMax. Released: June 2026. License: Open-weight under MiniMax's custom terms (read before redistributing). Context: 1 million tokens. Multimodal: Native.
Benchmark snapshot: SWE-bench Pro 59.0% — the top open-weight score as of July 2026, edging past the record Kimi K2.6 set in April (58.6%).
MiniMax M3 is the June 2026 surprise. MiniMax used to be the "bulk processing" name on this list; M3 is a frontier-class release: the best open-weight SWE-bench Pro score as of July 2026, a 1 million token context window, and native multimodal input in one model. If your workload mixes long documents, screenshots, and agentic steps, M3 covers all three without a model swap.
What it is great at
✓ Agentic software tasks. the top open-weight SWE-bench Pro score (59.0%, as of July 2026)
✓ Long-document analysis up to 1M tokens
✓ Native multimodal prompts (text + images in the same request)
✓ Replacing two-model pipelines (one vision model + one reasoning model) with one
Where it is not the best pick
- Bulk classification at rock-bottom cost (MiniMax abab still wins on price)
- European-language content (Mistral Large 3)
Inside Taskade Genesis
Point document-heavy agents at MiniMax M3 when the input mixes formats. A 500-page PDF with charts and screenshots is one M3 prompt, not a pipeline.
5. Qwen 3.6: The Open-Weight Multilingual Standard
Maker: Alibaba Cloud. Released: April 17, 2026 (Qwen 3.6 35B-A3B, MoE) and April 23, 2026 (Qwen 3.6 27B, dense). License: Apache 2.0. Architecture: 35B total / ~3B active MoE, plus a 27B dense sibling.
One naming correction up front, because half the internet gets it wrong: Qwen 3.7 Max is not open-weight. It shipped May 19, 2026 as an API-only proprietary model (see the License Risk Decoder callout above). The open-weight Qwen line is Qwen 3.6 — and it is still one of the best reasons to run open models.
The Qwen family is the most-downloaded open model family ever: 700 million+ Hugging Face downloads as of January 2026 and 113,000+ derivative models. Qwen 3.6 keeps the family's strengths — multilingual coverage across 35+ languages, reliable tool calling, structured output that respects JSON Schema — in an efficient package. The 35B-A3B MoE activates roughly 3B parameters per token, which makes it one of the cheapest frontier-adjacent models to self-host.
What it is great at
✓ Multilingual content across 35+ languages
✓ Tool calling and structured output for AI agents
✓ Efficient self-hosting. ~3B active parameters run on consumer-class GPUs
✓ Fine-tuning, with the largest derivative ecosystem of any model family
Where it is not the best pick
- The hardest reasoning tasks (GLM-5.2 or premium frontier)
- Very long documents (MiniMax M3 or Llama 4 Scout)
Inside Taskade Genesis
Pick Qwen 3.6 for multilingual agents and routing steps. A Chinese sales agent, a Japanese support agent, and an English research agent can share one workspace with Qwen handling the language-heavy roles.
6. MiniMax abab: The Bulk Processing Specialist
Maker: MiniMax. License: Custom (commercial use permitted). Context: 256K tokens.
MiniMax abab is purpose-built for high-throughput, low-cost workloads. Classification, routing, sentiment, extraction. The kind of work where you run 100,000 generations a month and want to ignore the credit meter.
What it is great at
✓ Classification and routing at scale
✓ Sentiment and intent extraction across large support inboxes
✓ First-pass labelling before sending to a heavier model
✓ Bulk pre-processing steps inside an automation
Where it is not the best pick
- Final-answer generation that ships to customers (use something stronger)
- Creative or nuanced writing
Inside Taskade Genesis
MiniMax shines as the first stage of a multi-step automation. Triage and label with MiniMax, hand off the interesting items to a stronger model. Standard cost-saving pattern.
7. Meta Llama 4 Scout: The Community Fine-Tune Standard
Maker: Meta. License: Llama 4 Community License (commercial use permitted under the 700M MAU cap). Context: 10 million tokens on Scout, 256K on Llama 4 base.
The Llama family is the most-forked open-source LLM line, and Llama 4 keeps the tradition. Not always the absolute strongest on a benchmark, but the largest ecosystem of fine-tunes, the broadest tool support, and the most well-documented behavior for function calling. The Scout variant ships an industry-leading 10M token context window.
What it is great at
✓ Tool calling and function execution inside AI agents
✓ Tasks where a specialised community fine-tune already exists
✓ Workflows where predictability matters more than peak performance
Where it is not the best pick
- Pushing the open-source frontier on a single benchmark
- Hardest reasoning tasks (still trails GLM-5.2 and premium frontier)
Inside Taskade Genesis
Llama 4 is the safest default for agents that call lots of the 34 built-in tools reliably. Tool calling behavior is mature, well documented, and stable across the open ecosystem.
8. Mistral Large 3: The European Flagship
Maker: Mistral AI. Released: December 2, 2025 (still the 2026 flagship). License: Apache 2.0 (full commercial use, no Research-vs-Commercial split. the older MRL/MNPL story is dead with Large 3). Architecture: MoE, 675B total / 41B active. Context: 128K tokens.
Benchmark snapshot: MMLU-Pro 73.11% · MATH-500 93.60% · Multilingual MMLU ~85.5% · LMSYS Arena Elo ~1418 (#2 open non-reasoning model).
Mistral became the European reference for open-weight models thanks to clear licensing, strong European language performance, and a focus on enterprise-ready releases. Mistral Large 3 is the cleanest commercial-use story of any 2026 European flagship: pure Apache 2.0, no MAU cap, no revenue gate.
What it is great at
✓ French, German, Italian, Spanish, Portuguese content
✓ Compliance-sensitive workflows where European jurisdiction matters
✓ Mixed enterprise use where Apache 2.0 license clarity is non-negotiable
✓ Tool calling with clean structured outputs
Where it is not the best pick
- Asian languages (use Qwen)
- Pure cost optimisation (GLM and MiniMax are cheaper)
- Agentic coding workloads (Kimi K2.7 Code leads)
Inside Taskade Genesis
Set Mistral Large 3 as the default model on any agent that speaks to European customers. Use it as a fallback in regions where data jurisdiction matters.
9. Cohere Command R+: The Retrieval and RAG Specialist
Maker: Cohere. License: CC-BY-NC 4.0 for weights, commercial use via Cohere API or partners. Context: 128K tokens.
Cohere built its reputation on retrieval-augmented generation. Command R+ is purpose-engineered for grounded answers, citation support, and tool use against external knowledge bases.
What it is great at
✓ Question answering grounded in your own knowledge base
✓ Citations and source attribution in responses
✓ Customer support agents tied to a documentation index
✓ Internal knowledge bots
Where it is not the best pick
- Open-ended creative writing
- Latency-critical tiny prompts
Inside Taskade Genesis
Pair Command R+ with the Memory Layer for support and knowledge agents. The combination of grounded responses and Workspace DNA Memory makes for very citable, traceable answers.
10. Microsoft Phi-4: The Small Model That Punches Above Its Weight
Maker: Microsoft. License: MIT for the open releases. Context: 16K tokens.
Phi-4 is the smallest model on this list and the cheapest. Microsoft tuned the Phi line for surprising performance from a much smaller parameter count, which makes Phi-4 a great fit for narrow, well-bounded tasks.
What it is great at
✓ Inline summarisation steps inside a longer pipeline
✓ Small classification jobs with limited input length
✓ Low-latency tool selection or quick formatting
✓ Fallback when other models are saturated
Where it is not the best pick
- Anything that needs long context
- Tasks needing broad world knowledge
Inside Taskade Genesis
Phi-4 is a clever pick for the small steps inside a larger automation. Extract a single field. Classify a message into 3 buckets. Rewrite a string before passing it to a heavier model. Done.
▲ ■ ● Workspace DNA: Where Open-Source Earns Its Keep
Every open-source LLM choice lives inside the same three-layer Workspace DNA that makes Taskade Genesis a real product, not a model picker.
Projects remember. Agents learn. Automations move.
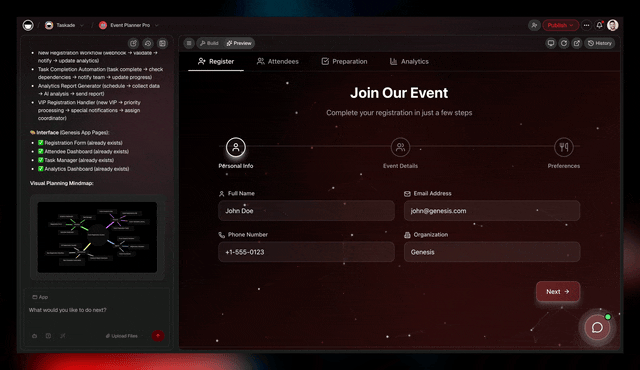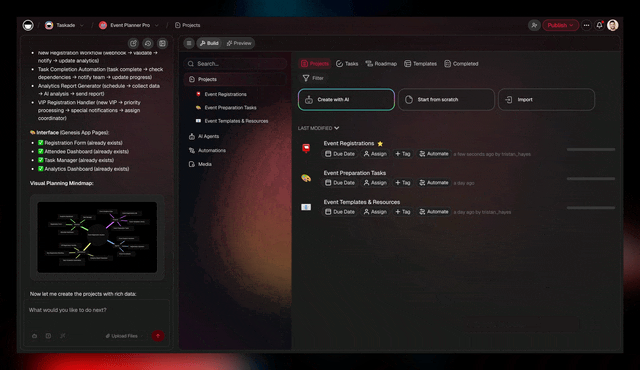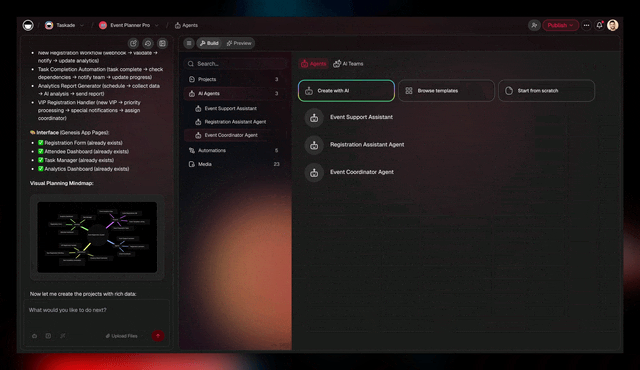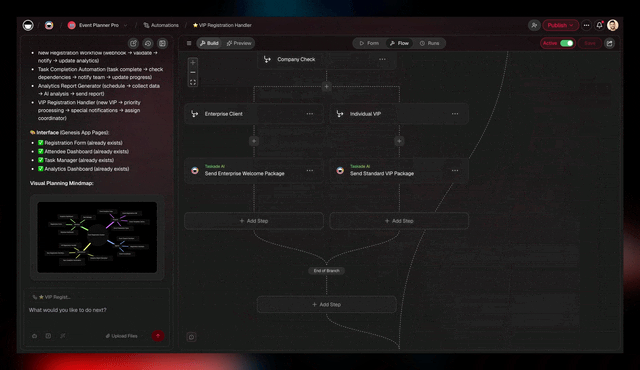
▲ Memory
Memory is the knowledge-graph foundation. Projects, documents, transcripts, customer records. Every relationship mapped. Every update linked. Open-source long-context models like Kimi and MiniMax M3 read from Memory at scale and write summaries back into the same graph.
■ Intelligence
Intelligence is where the agents live. Each one tuned for a role. Each one running on the best frontier model for its task. Auto mode routes between open-source and premium models per step. You can override on any step.
● Execution
Execution is where the work ships. Triggers pull events in. Actions push data out. The 100+ bidirectional integrations wire your tools together. Cheap open-source models route the bulk. Premium models handle the final delivery.
Memory feeds Intelligence. Intelligence triggers Execution. Execution creates Memory. The loop closes itself. Open-source LLMs slot into every layer at once.
The Four-Tier Memory Pyramid
Open-source LLMs handle short-term reasoning. Taskade Genesis handles the rest of the memory stack so the same conversation a year from now still knows what you sold to whom.
| Memory tier | What it holds | Taskade primitive |
|---|---|---|
| Working | The active prompt context (current turn) | The LLM's own context window |
| Episodic | Past chats, session logs, decisions | Chat history + project timeline |
| Semantic | Structured facts, relationships, definitions | Projects + Knowledge Connections |
| Procedural | "How we do things here" | Automations + saved workflows |
The open-source LLM you pick handles the Working tier. Taskade Genesis handles the rest. That is the moat.
How to Choose: A Practical Decision Tree
In practice you do not pick once and stick with it. You pick per task. The strongest pattern across teams shipping in 2026 is a heavier model for the final answer and a lighter open-source model for everything that leads up to it.
Five Patterns That Work Right Now
Real workflow shapes that combine open-source and premium models inside Taskade Genesis. Steal them.
Pattern 1: Triage with MiniMax, Answer with Claude
A support automation classifies incoming tickets with MiniMax abab for almost no credit cost. The interesting ones route to a stronger model for the actual response. The simple ones auto-close with a template.
Pattern 2: Research with Kimi, Draft with Qwen
A market research agent ingests 30 long PDFs in a single Kimi K2.7 Code pass to extract themes. The structured themes hand off to Qwen 3.6 for a publishable draft. The whole pipeline runs at a fraction of the cost of routing the same job through a premium frontier model alone.
Pattern 3: Code Review with DeepSeek, Ship with Taskade EVE
When editing a Taskade Genesis app through the MCP Server, code-review and code-suggestion steps route through DeepSeek V4 Pro for accurate suggestions. Taskade EVE orchestrates the rest of the build.
Pattern 4: Multilingual Customer Support
Set the per-agent language preference. French agent on Mistral. Chinese agent on Qwen. German agent on Mistral. English agent on Llama. Same workspace. Same memory. Different brains.
┌──────────────────────────────────────────────────┐
│ Customer message in 🇫🇷 → Mistral Large 3 │
│ Customer message in 🇨🇳 → Qwen 3.6 │
│ Customer message in 🇩🇪 → Mistral Large 3 │
│ Customer message in 🇬🇧 → Meta Llama 4 │
│ Customer message in 🇯🇵 → Qwen 3.6 │
│ Customer message in 🇪🇸 → Mistral Large 3 │
│ ────────────────────────────────────────────── │
│ All routed through one inbox. One memory. │
│ One workspace. Different brains. │
└──────────────────────────────────────────────────┘
Pattern 5: Cost-Optimised Scheduled Automation
Any automation that runs on a schedule benefits from defaulting to GLM-5 or MiniMax. Reserve the premium picks for the final actions that ship to customers.
What Open-Source LLMs Cannot Do Yet
Open-source is closing the gap but it has not closed it everywhere.
| Frontier still leads | Open-source has caught up | Why it matters |
|---|---|---|
| Absolute peak reasoning | Routine reasoning | Hard puzzles still favor premium |
| Frontier multimodal (text + image + audio + video) | Single-mode multimodal | Premium leads on combined understanding |
| Real-time voice agents | Text agents | Voice latency is still a closed-model edge |
| Latest tools and browsing | Standard tool calling | Premium has deeper integrations |
The right framing is not "which is better." It is which mix is best for the work. Taskade Genesis lets you mix without committing.
Open Source vs Open Weight vs Restricted: A Quick Reference
A common source of confusion. Here is the practical answer.
| Term | What is shared | Examples in this guide |
|---|---|---|
| Open source | Weights + training data + training code + tokenizer | OLMo, Pythia (research) |
| Open weight | Trained weights with a commercial-use license | Qwen 3.6, DeepSeek, Llama, Mistral, GLM, Kimi, MiniMax, Phi |
| Restricted weight | Weights with restrictions (research-only, non-commercial) | Some Command R variants |
| Closed | API only, no weights | GPT, Claude, Gemini, Qwen 3.7 Max |
For practical purposes, "open source" in marketing copy usually means open-weight. Check the specific license before redistributing fine-tunes or hosting them in a third-party product.
Pricing Inside Taskade Genesis
Open-source models run on the same credit system as premium models in Taskade Genesis, just at lower credit costs per generation. Hover any model in the picker and the exact credit cost appears in the tooltip. The same number lands on your usage page.
The Taskade pricing plans:
| Plan | Monthly cost | AI credits per month | Best for |
|---|---|---|---|
| Free | $0 | 1,000 | Trying every open-source model |
| Starter | $6/mo | 10,000 | Solo builder mostly on open-source |
| Pro | $16/mo | 50,000 | Small team running mixed workloads |
| Business | $40/mo | 150,000 | Multi-agent workflows, custom domains, white-label, API |
| Max | $200/mo | 400,000 per seat | Genesis-heavy workloads, unlimited seats |
| Enterprise | $400/mo | Custom | SLA, dedicated support, priority infrastructure |
Bring-Your-Own-Key is available on Enterprise. Teams can point Taskade at their own provider account for specific premium or open-source models. The model picker behaves the same way. The credits land on the team's own bill.
A Buyer's Note on Hype Cycles
A reminder for anyone reading this in six months.
- New frontier-class open-source models will appear. This list is the snapshot of July 2026. The shape of the list is more durable than the names.
- Benchmarks lie. Run the model on your own work. The numbers in the model card tell you what the lab tested. The numbers from your own prompts tell you what you actually get.
- Cost-to-quality moves. Today's premium model becomes tomorrow's mid-tier. Today's open-source champion becomes tomorrow's commodity. Build for the architecture (Memory → Intelligence → Execution) not for the specific model.
Taskade Genesis is built to absorb that drift. New models join the catalog automatically. Auto mode adapts. Your prompts keep working. And because every app you build is owned and versioned, the output stays accountable, not AI slop.
Frequently Asked Questions
Which open-source LLM should I try first inside Taskade Genesis?
Start with GLM-5.2 as your default open-source pick. It handles general reasoning well, ships under a clean MIT license, and gives you a clear baseline to compare against. Then add DeepSeek V4 Pro or Kimi K2.7 Code for code tasks and MiniMax M3 for very long or multimodal context. Switch using the model picker on any agent or automation.
Do open-source LLMs work for production workloads?
Yes. Inside Taskade Genesis the same managed gateway, audit logging, and 7-tier role-based access apply to every model regardless of provider. Many teams ship production Taskade Genesis apps running primarily on open-source models with premium models reserved for the highest-value steps.
Can I use open-source LLMs through the Taskade MCP Server?
Yes. The Taskade MCP Server connects external AI clients like Claude Desktop, Cursor, and any MCP-compatible tool to your Taskade workspace. The model your external client uses (Claude, GPT, or any other) drives the conversation. Actions inside Taskade route through whichever Taskade Genesis model you have configured per agent or automation. Mix and match.
Are these the same models as on Hugging Face?
Mostly yes. The model weights for Qwen 3.6, DeepSeek, Kimi, GLM, MiniMax, Llama, Mistral, Command R+, and Phi are all available on Hugging Face. The one to watch is Qwen 3.7 Max, which launched API-only on May 19, 2026 with no weights published. The version Taskade serves through the picker is the latest production-ready release from the provider, running on a managed gateway so you do not have to operate your own GPU infrastructure.
What about open-source vision and image-generation models?
This guide focuses on text LLMs. For image generation, Taskade Genesis has a separate image-generation action that routes to multiple providers. For vision (image understanding inside a prompt), MiniMax M3 supports multimodal input natively on the open-weight side, alongside several premium frontier models.
Will open-source LLMs replace GPT and Claude?
For some workloads, already yes. For the hardest reasoning, not yet. The realistic 2026 outcome is a mixed ecosystem where open-source handles a growing share of routine work and premium models keep their lead on the hardest tasks. Taskade Genesis is designed for that mixed reality from day one.
Can I switch the default model on an existing agent or automation?
Yes. Open the agent settings or the automation step. Pick the new model from the dropdown. Save. The change takes effect on the next run. No retraining, no redeployment.
Where do new open-source models show up in Taskade?
Automatically. New frontier models, including open-source releases, are added to the catalog as they ship from each provider. The next time you open the model picker, the new option is there. See Multi-Model AI Access for the current provider list.
Can I see the cost of a generation before I run it?
Yes. Hover any model in the picker and the credit cost appears in the tooltip. The same number lands on your usage page. See Model Credits for plan quotas and credit-cost detail.
Do I need to be technical to use open-source LLMs in Taskade?
No. The hard parts (deployment, scaling, version management, infrastructure) are handled by the managed gateway. Pick a model from a dropdown. Run a prompt. The same as you would with any other Taskade Genesis model. The only difference is the credit cost in the tooltip.
What workloads should I keep on premium frontier models?
Keep premium frontier models for the parts of a workflow that need absolute peak reasoning, real-time voice, frontier multimodal, or the deepest tool integrations. For everything else, the open-source picks here are competitive on quality and dramatically cheaper.
Can I run an entire team on open-source models?
Yes, and it makes sense for many teams. A small team can run mostly on GLM-5.2 + DeepSeek + Kimi and reach for premium models only when the work genuinely calls for it. The Taskade pricing Free and Starter plans are sized for exactly this workload.
What to Try This Week
Five small experiments. Each takes under 10 minutes inside Taskade Genesis.
- ✓ Open Taskade Genesis and switch one agent to GLM-5.2. Run a normal task. Compare the output.
- ✓ Run one automation on GLM-5 or MiniMax. Note the credit cost difference on your usage page.
- ✓ If you code, pair Taskade EVE with DeepSeek V4 Pro on a code-editing step through the Taskade MCP Server.
- ✓ Set up a support agent on Cohere Command R+ tied to your Memory Layer and watch the citations show up.
- ✓ Try a long-document analysis on MiniMax M3 with a 500-page PDF (1M-token window). Notice retrieval is no longer the bottleneck.
Build an app with any of these models →
▲ ■ ● Final Word
Open-source AI LLMs in 2026 are not the future. They are the present.
Between April and June 2026, five flagship open-weight releases reset this ranking: DeepSeek V4 Pro (Apr 24, MIT, 1M context, SWE-bench Verified 80.6%), Kimi K2.6 (Apr 20, the first open model to lead every premium frontier model on SWE-bench Pro), Kimi K2.7 Code (June 12, +21.8% over K2.6 on Kimi Code Bench v2), GLM-5.2 (June 13, MIT weights, GPQA Diamond 91.2%), and MiniMax M3 (June, SWE-bench Pro 59.0% — the open-weight top as of July 2026). Qwen 3.7 Max (May 19) went the other way: API-only, not open-weight. The open Qwen family still crossed 700 million Hugging Face downloads in January. The frontier moved while everyone was reading benchmark hot-takes.
The ten picks above ship real work today inside Taskade Genesis. Mix them. Use the heavier picks where they earn their cost. Use the lighter picks for everything in between. Let Workspace DNA handle the memory the model cannot.
Apps used to run your business. Now your business builds the apps. Projects remember. Agents learn. Automations move. One workspace. One memory. One credit system. Ten open-source brains and six premium ones in the same picker. The right model for every step.
This is the origin of living software. 🌱
Related reading
- Multi-Model AI Access. Pick the right model for every task in Taskade Genesis.
- Model Credits. Per-model credit costs and plan quotas.
- Tools for AI Agents. The 34 built-in tools every agent can call.
- Taskade MCP Server. Plug Claude Desktop, Cursor, and other MCP clients into your workspace.
- Multi-Agent Workspace: Memory, Agents, Workflows. The three-layer Workspace DNA in depth.
- Your Taskade Welcome Series. What lands in your inbox over your first week.
- Automatic User Provisioning with SCIM. Sync users from Okta or Azure AD.
- Custom AI Agents. Per-agent model selection and tool loadouts.
- Multi-Agent Teams. Specialised agents collaborating with different model picks.
- Top Open-Source Autonomous Agents. The agent-framework landscape that pairs with these models.
- Best AI Coding Tools 2026. Where open-source LLMs are reshaping the developer toolchain.
- History of Mermaid Diagrams as Code. The diagram engine powering every visual in this post.
Build an app with any of these models →