





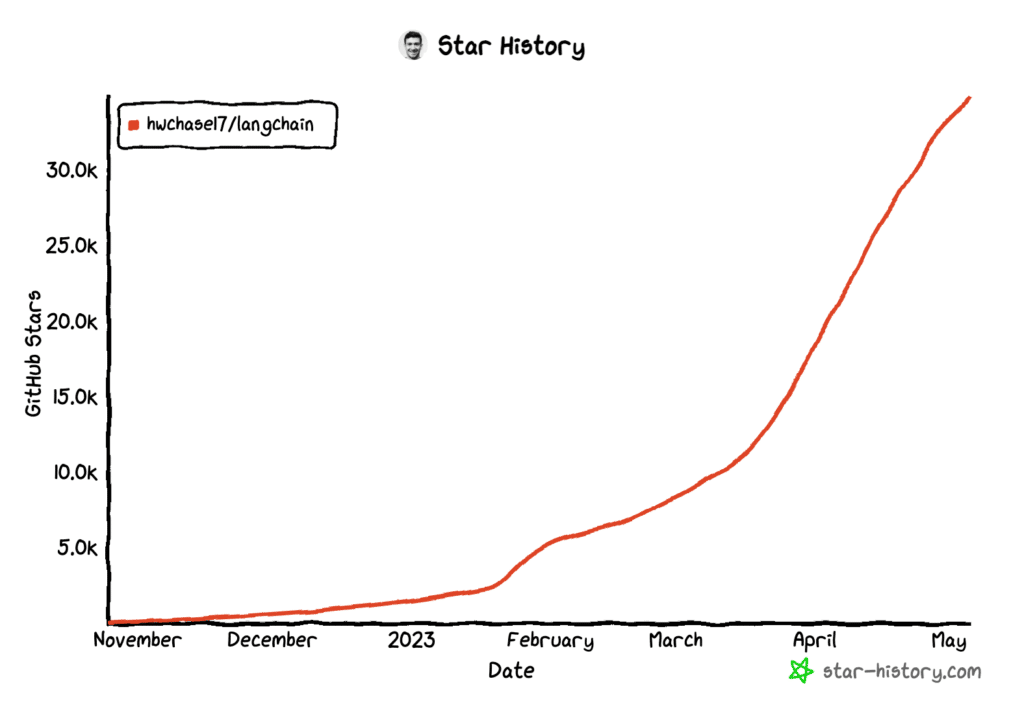
In October 2022, a machine learning engineer named Harrison Chase pushed a side project to GitHub. He'd been solving the same frustrating problem at work, connecting large language models to external data and tools required writing the same boilerplate code, over and over, for every new application. His solution: a composable Python library that turned LLM pipelines into chains of modular, reusable components.
He called it LangChain.
Within eight weeks, it was the fastest-growing repository on all of GitHub. Within six months, it had raised $35 million from Sequoia and Benchmark. Within a year, it had become the de facto standard for building AI applications, and the foundation on which an entire ecosystem of agent frameworks (LangGraph, CrewAI, AutoGen, Mastra, LlamaIndex) would grow.
This is the complete story, from that first GitHub commit to the multi-agent era of 2026, every pivot, every funding round, every framework that emerged from LangChain's shadow, and what it all means for teams building AI-powered products today.
TL;DR: LangChain (Oct 2022) is the open-source Python/JS framework that turned LLM application development into composable pipelines, popularized RAG, and sparked the AI agent framework ecosystem. After explosive growth, 95K+ GitHub stars, $35M raised from Sequoia and Benchmark, the team pivoted to LangGraph (stateful multi-agent graphs) and LangSmith (commercial observability). The framework's evolution from chains → agents → graphs maps perfectly to how AI system design has matured: from deterministic pipelines to adaptive workflows to production-grade orchestration. Taskade Genesis is the no-code path to the same multi-agent patterns, without installing a single package.
LangChain at a Glance (2026)
| Fact | Detail |
|---|---|
| Founded | October 2022, San Francisco, CA |
| Founder | Harrison Chase (formerly ML engineer at Robust Intelligence) |
| Company | LangChain Inc |
| Open-source license | MIT |
| Languages | Python (primary), JavaScript/TypeScript |
| GitHub stars | 95,000+ (mid-2026) |
| Total funding | ~$35M (Seed + Series A) |
| Investors | Benchmark (seed), Sequoia Capital (Series A) |
| Valuation | ~$200M (Series A, May 2023) |
| Commercial product | LangSmith (observability & tracing) |
| Key sub-project | LangGraph (stateful multi-agent framework) |
| Monthly PyPI downloads | 10M+ |
| Enterprise users | Elastic, GitLab, Rakuten, Morningstar |
What Is LangChain?
LangChain is an open-source framework for building applications powered by large language models. Its core idea: LLMs are most useful when connected to the outside world, to your documents, your databases, your APIs, your tools. LangChain provides the connective tissue.
Before LangChain, building an LLM application that could answer questions about your company's internal documents required writing custom code to:
- Load the documents from S3, Notion, or a database
- Split them into chunks that fit in the model's context window
- Embed those chunks as vectors and store them in a vector database
- When a user asks a question, embed the question, retrieve the most relevant chunks
- Inject those chunks into the prompt alongside the question
- Call the LLM API with the formatted prompt
- Parse and return the response
Every team was writing this same seven-step pipeline from scratch. LangChain turned each step into a composable building block, document loaders, text splitters, embedding models, vector stores, retrievers, prompt templates, LLM wrappers, output parsers, and let you connect them with a few lines of code.
This pattern, Retrieval-Augmented Generation, or RAG, became the dominant enterprise AI architecture of 2023. LangChain didn't invent RAG, but it made RAG accessible to every developer with a Python interpreter. For a complete picture of how agents use external knowledge, see our AI agents guide and the Taskade agent tools reference.
Harrison Chase: The Founding Story
Harrison Chase studied mathematics and computer science at Harvard. After graduating, he joined Robust Intelligence, an AI security startup that tested machine learning models for adversarial vulnerabilities, data poisoning attacks, and bias failures. It was painstaking, important work, and it gave Chase a front-row seat to how fragile LLM-powered systems could be when not properly structured.
Chase kept running into the same problem: connecting a language model to external data was tedious, repetitive work. There was no standard way to load documents, no clean interface for vector stores, no composable pattern for combining retrieval with generation. Every project started from scratch. This problem, building reliable agentic workflows that connected LLMs to real data, would define the next two years of AI infrastructure development.
In the fall of 2022, Chase started building a library to fix this for himself. He shared it on GitHub in October 2022 with a simple README and a handful of integrations.
The timing was extraordinary.
Six weeks later, OpenAI launched ChatGPT on November 30, 2022, and the world's developer community collectively discovered they needed exactly what LangChain had just shipped.
The GitHub Explosion: Zero to 50,000 Stars in Record Time
When ChatGPT launched, millions of developers immediately started asking: How do I build something like this on my own data? LangChain was the answer sitting at the top of a Google search.
The growth was unlike anything the open-source community had seen:
| Milestone | Approximate Date |
|---|---|
| 1,000 GitHub stars | November 2022 |
| 10,000 GitHub stars | January 2023 |
| #1 trending repo on all of GitHub | January 2023 |
| 25,000 GitHub stars | February 2023 |
| $10M seed round closed (Benchmark) | February 2023 |
| 50,000 GitHub stars | March 2023 |
| $25M Series A closed (Sequoia) | May 2023 |
| 65,000 GitHub stars | June 2023 |
| 80,000 GitHub stars | December 2023 |
| LangGraph v0.1 released | January 2024 |
| 90,000+ GitHub stars | Mid-2024 |
| 95,000+ GitHub stars | Mid-2026 |
LangChain reached 50,000 GitHub stars faster than any Python library before it, faster than TensorFlow, faster than PyTorch, faster than FastAPI. By February 2023, it had over 800 contributors. By March, it was being downloaded more than 500,000 times a month from PyPI.
The community wasn't just starring it. They were building with it. The LangChain Discord went from zero to tens of thousands of members in a matter of weeks. Hundreds of tutorials, YouTube videos, and blog posts appeared daily. Enterprise teams at Fortune 500 companies were integrating it into production systems.
The pull requests kept coming faster than the small team could review them.
The Funding Rounds: From Side Project to $200M Company in Seven Months
Seed Round: February 2023
The seed round was a reflection of how fast things were moving. Benchmark, one of Silicon Valley's most storied venture firms (backers of Twitter, Uber, Dropbox, and Discord), led a $10 million seed round in February 2023.
At this point, LangChain had no product, no revenue, and no company, just an open-source library that had gone viral. Benchmark partner Peter Fenton later noted that the conviction came from watching how developers were already using it in production and building businesses on top of it.
Series A: May 2023
Three months after the seed, Sequoia Capital led a $25 million Series A at a reported valuation of approximately $200 million.
The round closed in May 2023, just seven months after Harrison Chase had pushed the first commit to GitHub. Total funding: ~$35 million.
The Series A thesis was clear: LangChain had established itself as the infrastructure layer for LLM applications. If the LLM application market was going to be enormous (and it was), the foundational tooling layer would capture enormous value. This was the "picks and shovels" bet in the AI gold rush.
| Round | Date | Amount | Lead Investor | Valuation |
|---|---|---|---|---|
| Seed | Feb 2023 | $10M | Benchmark | Undisclosed |
| Series A | May 2023 | $25M | Sequoia Capital | ~$200M |
| Total | ~$35M |
The Chain Era: What LangChain Originally Was
Understanding LangChain's evolution requires understanding what the "chain" abstraction actually was, and why it both worked brilliantly and eventually hit its limits.
A chain in early LangChain was a sequence of operations connected by their inputs and outputs:
Step 1: Load documents → Step 2: Split into chunks → Step 3: Embed chunks
→ Step 4: Store in vector DB → Step 5: Retrieve relevant chunks
→ Step 6: Format prompt → Step 7: Call LLM → Step 8: Parse output
Each step's output became the next step's input. The whole thing could be serialized to JSON, loaded from a config file, and run repeatedly. It was elegant for the RAG use case.
LangChain shipped over a dozen chain types for common patterns:
- LLMChain, the simplest: prompt template + LLM + output parser
- SequentialChain, chain multiple LLMs together in sequence
- RetrievalQA, the canonical RAG chain: retrieve + generate
- ConversationalChain, add memory to an LLM conversation
- MapReduceChain, split a large document, summarize each part, reduce to one answer
- RouterChain, route to different sub-chains based on input
The library also shipped hundreds of integrations, connections to OpenAI, Anthropic, Cohere, Google, 50+ vector stores (Pinecone, Chroma, Weaviate, pgvector), dozens of document loaders (PDF, Notion, Google Drive, GitHub, Confluence), and output parsers for JSON, CSV, and custom schemas.
This breadth of integrations was a key competitive moat. Building your RAG pipeline meant choosing your pieces (OpenAI for embeddings, Pinecone for storage, Anthropic for generation), LangChain connected all of them with a consistent interface.
The Limits of Chains: Why Agents Needed Something New
Chains worked beautifully for predictable pipelines. They broke down when you needed AI that could decide what to do next.
Consider a research assistant agent. You ask it: "Compare the revenue growth of Apple and Microsoft for the last three years and tell me which is a better investment."
A chain can't handle this. The agent needs to:
- Search for Apple's revenue data (tool use)
- Search for Microsoft's revenue data (tool use)
- Decide if it has enough data or needs to search more
- Calculate growth rates (tool use or reasoning)
- Synthesize a recommendation
- Maybe search for analyst opinions to support it
- Return a final answer
The number of steps isn't known at build time. The agent might need to loop, decide to search again if the first result was irrelevant. It needs state, what has it already found? It needs error handling, what if a search fails?
LangChain's original AgentExecutor tried to handle this but had critical weaknesses. Understanding these limitations is why agentic engineering emerged as a discipline rather than just a collection of libraries:
- No persistent state: state was squeezed into the conversation history, causing context pollution
- No cycle control: a runaway agent could loop indefinitely
- No partial execution: if step 4 of 7 failed, you started over from scratch
- No human-in-the-loop: you couldn't pause execution for human approval and resume
- No sub-agent coordination: one agent doing everything was the only pattern
These weren't bugs in LangChain. They were architectural limits of the chain/agent paradigm. The real question was whether the right fix was a better AgentExecutor or a different abstraction entirely.
The answer turned out to be a graph.
LangGraph: The Stateful Multi-Agent Pivot
In January 2024, the LangChain team released LangGraph, a library for building stateful, cyclic, multi-actor applications with LLMs.
The core insight was simple: instead of a linear chain, use a directed graph.
- Nodes are units of work (call an LLM, run a tool, check a condition)
- Edges define routing (always go to node B after node A, or conditionally route to B or C based on A's output)
- State is a typed Python TypedDict that flows through the graph, every node reads from state and writes back to state
- Cycles are explicitly supported. You can loop back to an earlier node when needed
This might look like the same loop as AgentExecutor. What's different is state:
Every call to the Agent node reads from and writes to a shared State object, a typed Python dict with explicit fields like messages, documents_found, current_plan, tool_results. Nothing is hidden in conversation history. Every node knows exactly what state the graph is in. Debugging means reading the state snapshot, not reconstructing conversation flow.
LangGraph also added checkpointing, save the graph's state to disk (SQLite or Redis by default) and resume from any checkpoint. A long-running research agent that crashes halfway through can resume from the last saved state. Human-in-the-loop becomes straightforward: pause the graph, surface the state for human review, resume with updated state.
LangGraph's Multi-Agent Architecture
For multi-agent systems, LangGraph introduced the Supervisor pattern, a design that maps directly to how Taskade's AI teams coordinate across tasks:
A Supervisor node (powered by an LLM) decides which specialist agent to delegate to. Each agent is itself a node in the graph. It can have its own tools, its own memory, its own state writes. Agents communicate via the shared graph state, not by calling each other directly. The Supervisor routes based on what each agent returns.
This pattern maps onto real organizational structures: a project manager (Supervisor) delegates to specialists (Researcher, Writer, Coder, QA) based on what work remains, reviews their output, and routes to the next step. The graph is the org chart made executable.
LangSmith: The Commercial Product
While LangChain and LangGraph were always open-source, LangChain Inc needed a commercial product to build a sustainable business. That product is LangSmith.
LangSmith launched in closed beta in June 2023 and reached general availability by late 2023. It provides:
- Tracing: every LLM call, every tool invocation, every node execution is logged with full input/output and timing
- Evaluation: run automated evals against your chains and agents to measure accuracy, coherence, and task completion
- Dataset management: collect production traces and curate them into evaluation datasets
- Production monitoring: track latency, error rates, and cost trends over time
- Prompt versioning: version-control your prompts alongside your code
The business model is pure developer infrastructure: LangSmith is free for small volumes (useful for getting started), and paid plans scale with usage. Enterprise contracts include SSO, VPC deployment, and SLA guarantees.
LangSmith fills the observability gap that makes the difference between "I built a demo that works in my dev environment" and "I have a production system I can trust and debug when it fails." This gap is real, most teams that built LangChain pipelines in 2023 discovered quickly that production LLM systems fail in unexpected ways, and you can't fix what you can't observe. The same principle applies to Taskade Genesis automation workflows: visibility into every step is what separates demos from production systems.
The AI Agent Framework Ecosystem
LangChain's success created a generation of frameworks built in its shadow, some on top of it, some in reaction to its limitations, and some targeting entirely different developer audiences.
LlamaIndex (November 2022)
Released just weeks after LangChain, LlamaIndex (originally GPT Index) was built by Jerry Liu specifically for the RAG use case, ingesting, indexing, and querying data with LLMs. While LangChain went broad (agents, tools, chains, memory), LlamaIndex went deep on data, specialized loaders for 100+ data sources, advanced retrieval strategies (hybrid search, reranking, parent-child chunking), and query engine abstractions. The two frameworks are often used together rather than competitively.
AutoGen: Microsoft (September 2023)
Microsoft Research released AutoGen in September 2023 as a framework for multi-agent conversation. The core concept: agents are conversational entities that exchange messages to solve problems. A UserProxy agent talks to an AssistantAgent; the AssistantAgent might spawn SubAgents. Code is executed, results flow back as messages, and the conversation continues until a task is complete. AutoGen's message-passing model is intuitive but can make complex state management difficult, something LangGraph's typed state solves more explicitly.
CrewAI (January 2024)
João Moura, a Brazilian software engineer, released CrewAI in January 2024. Built on top of LangGraph, CrewAI introduced a higher-level abstraction: instead of defining nodes and edges, you define Crew members with roles, goals, and backstories. The crew mental model, multiple specialized agents collaborating on tasks, proved immediately intuitive for developers. A crew might have a Researcher agent, a Writer agent, and an Editor agent, each with a specific role and the tools appropriate to that role. The Crew orchestrates them through tasks, handling the LangGraph routing automatically.
CrewAI's opinionated structure made it dramatically easier to get started with multi-agent systems. It became one of the fastest-growing AI frameworks in GitHub history, reaching 30,000+ stars within months of launch.
Mastra (TypeScript, 2024–2025)
As the LangChain ecosystem matured in Python, a gap remained in the TypeScript world. While langchain.js existed, TypeScript teams found it felt like a port rather than a native design.
Mastra emerged as a TypeScript-first alternative. Its distinguishing features, demonstrated concretely in Damian Brady's 2026 tutorial, include:
- Typed workflow steps using Zod schemas for both input and output
- Multi-model decomposition: different models for different steps (a small local model for classification, a larger model for scoring)
- Built-in evals attached to individual steps, not bolted on at the end
setState/getStepResultfor state management without threading context through function arguments- Mastra Studio, a local dev UI for visualizing workflow DAGs, running fixtures, and inspecting step-by-step execution
The Mastra pattern explicitly forces a decision at every step: should this be a model call or deterministic code? That discipline, separating what the LLM needs to do from what code can do reliably, produces systems that are cheaper, faster, and more debuggable than single-agent solutions. For teams who want this discipline without framework overhead, Taskade's automation triggers and agent tools apply the same separation through a visual interface.
LangChain vs The Framework Field: A Full Comparison
| Framework | Language | Released | GitHub Stars | Core Paradigm | Best For | LangChain Relationship |
|---|---|---|---|---|---|---|
| LangChain | Python/JS | Oct 2022 | 95K+ | Chains + tools + RAG | Building on established ecosystem | Foundation |
| LangGraph | Python/JS | Jan 2024 | 10K+ | Stateful directed graphs | Production multi-agent with cycles | Built by LangChain team |
| LlamaIndex | Python/TS | Nov 2022 | 37K+ | Data indexing + RAG | Data-heavy retrieval applications | Complementary |
| AutoGen | Python | Sept 2023 | 40K+ | Multi-agent conversations | Conversational agent teams (Microsoft) | Independent |
| CrewAI | Python | Jan 2024 | 30K+ | Role-based crews | High-level multi-agent orchestration | Built on LangGraph |
| Haystack | Python | 2020 | 18K+ | NLP pipelines | Enterprise search + NLP | Independent (deepset) |
| Mastra | TypeScript | 2024-25 | Growing | Typed workflow steps | TypeScript/Node.js production agents | Independent |
| OpenAI Agents SDK | Python | 2024 | N/A | Lightweight agent loops | OpenAI-committed teams | Independent |
The Criticisms: When "Just Use LangChain" Wasn't Enough
No technology grows this fast without accumulating critics. By mid-2023, a counter-narrative was forming: LangChain is too complex, too abstract, and too hard to debug.
The criticisms were real and came from experienced engineers:
1. The Abstraction Rot Problem
LangChain's chain abstraction hid too much. When an LLMChain failed, the error might be in the prompt template, the model API call, the output parser, or the data flowing between them. But the abstraction gave you a cryptic error from a layer you didn't fully understand. Debugging required reading LangChain source code, not just your own.
This was the classic trade-off of good abstractions: they accelerate the common case but make the edge cases harder. For RAG on well-structured documents, LangChain was excellent. For complex, multi-step agents with error recovery, the abstraction became an obstacle.
2. Too Many Dependencies, Too Many Imports
Early LangChain required installing the entire library to use any feature. The pip install langchain was enormous, pulling in dozens of dependencies even if you only needed one integration. The library split into langchain-core, langchain-community, and provider-specific packages (like langchain-openai, langchain-anthropic) in 2024, largely solving this. But the damage to the library's reputation for bloat was already done.
3. API Instability in 2023
In 2023, LangChain was shipping changes so fast that tutorials became outdated within weeks. Developers investing in LangChain would find their code broken by a minor version update. This is an inherent tension in early open-source projects, move fast to capture community, or move carefully to protect early adopters, and the LangChain team initially prioritized speed.
LangChain v0.1, released in January 2024 alongside the LangGraph stable release, represented a deliberate shift: a stable public API with deprecation warnings before breaking changes.
4. The "Just Use the SDK" Critique
By 2024, a legitimate alternative emerged: just call the LLM provider's API directly with structured outputs and tool calls. OpenAI's function calling (June 2023) and Anthropic's tool use API gave developers native ways to build agents without an abstraction layer. Many engineers concluded that for simple agents, the overhead of learning LangChain's abstractions wasn't worth it. You'd end up with less code and better debuggability by working directly with the SDK.
The LangChain team's response was pragmatic: LangGraph was explicitly designed for cases where the direct SDK approach breaks down, complex multi-agent workflows with cycles, state, and coordination. Use the raw SDK for simple cases. Use LangGraph when you need the graph.
The Chain → Agent → Graph Evolution: A Systems Design Lesson
LangChain's evolution from chains to agents to graphs is not just company history. It's a design lesson that applies to every AI system.
The pattern maps onto the same insight Damian Brady articulated in his 2026 Mastra tutorial: stop giving one agent the whole job.
| Era | Abstraction | Strength | Failure Mode |
|---|---|---|---|
| Chains (2022–2023) | Linear pipeline of steps | Predictable, fast, debuggable | Can't handle cycles or dynamic routing |
| Agents (2023) | LLM decides next step at runtime | Flexible, can handle novel situations | Unpredictable cost, loops, hard to debug |
| Graphs (2024–) | Explicit typed state + nodes + routing | Predictable structure + agent flexibility | More setup required upfront |
The same tension exists in every complex software system:
- Deterministic pipelines are fast and predictable but rigid. They can't adapt to unexpected inputs
- Pure LLM agents are flexible but expensive and opaque. You can't reason about what they'll do
- Typed workflow graphs are the synthesis: explicit structure where structure is known, LLM judgment where it's needed, typed state that makes the whole system inspectable
This is why Mastra's step-by-step approach, LangGraph's node/edge architecture, and the Anthropic Agent SDK's harness design all converge on the same pattern: be explicit about which parts should be model calls, which parts should be deterministic, and how the whole thing fits together.
The TypeScript Path: Mastra, LangChain.js, and the Node.js Ecosystem
The Python LangChain ecosystem had a JavaScript/TypeScript counterpart from early on, langchain.js. But the TypeScript AI framework story developed in a different direction.
langchain.js followed the Python conventions and was maintained by the same team, but TypeScript developers often found it felt like a translation rather than a native design. Type safety was inconsistent, and patterns like document loading and vector store connections often required workarounds for the Node.js environment.
The gap opened space for framework alternatives:
Mastra (released publicly in 2024-2025) takes a significantly different approach. Rather than adapting LangChain's chain/agent metaphor to TypeScript, Mastra starts from TypeScript's type system and asks: what would an AI workflow framework look like if designed natively for TypeScript from the ground up?
The answer is a workflow system where every step has a Zod-validated input schema, a Zod-validated output schema, and optionally a state schema, making the entire workflow type-safe end to end. Different models run at different steps (a small local model for cheap classification, a larger model for complex reasoning), and evals can be attached to individual steps rather than bolted on after the fact.
For teams building production TypeScript agents, this matters because:
- Cost control: use Ministral 3.8B for email classification (milliseconds, pennies), Qwen 35B for scoring (seconds, more expensive), each in the right place
- Testability: extract deterministic functions from steps, write unit tests against them before building the LLM wrapper
- Observability: Mastra Studio renders the workflow DAG locally, shows step-by-step input/output, and records eval scores alongside traces
This TypeScript-native approach is part of a broader shift: as AI agent frameworks mature, the emphasis is moving from "connect everything to an LLM" toward "be explicit about what the LLM needs to do versus what deterministic code can do."
LangChain and the RAG Revolution
Before addressing what LangChain is today, it's worth documenting what it made possible in 2023: the RAG revolution that changed how enterprises deploy AI.
Before LangChain-style RAG, enterprise AI deployments had two options:
- Fine-tuning: expensive, slow, requires ML expertise, and the model's knowledge was frozen at fine-tuning time
- Prompt stuffing: putting all relevant text directly in the prompt, limited by context window size and expensive at scale
RAG offered a third path: index your documents once, retrieve the relevant ones at query time, and inject only the relevant context into the prompt. With LangChain providing the standard toolkit for this, the pattern spread rapidly.
Companies built internal knowledge bases where employees could query the company's Confluence, Notion, and email archives in natural language. Law firms built contract analysis tools. Healthcare companies built clinical decision support systems. Financial services firms built document review pipelines.
The key LangChain components that powered this:
| Component | What It Does | Common Choices |
|---|---|---|
| Document Loaders | Ingest documents from any source | PDF, Notion, Confluence, S3, GitHub |
| Text Splitters | Chunk documents to fit in context | RecursiveCharacterTextSplitter, MarkdownHeaderSplitter |
| Embedding Models | Convert text to vector representations | OpenAI, Cohere, HuggingFace, local models |
| Vector Stores | Index and retrieve by semantic similarity | Pinecone, Chroma, Weaviate, pgvector, FAISS |
| Retrievers | Search the vector store for relevant chunks | Basic retriever, MMR, Hybrid search |
| Prompt Templates | Format retrieved context + user question | ChatPromptTemplate, FewShotPromptTemplate |
| LLM Wrappers | Call any model with a consistent interface | OpenAI, Anthropic, Google, Ollama (local) |
| Output Parsers | Parse model output into structured data | JSON, Pydantic, Comma-separated |
This standardization was the key contribution: a developer who learned LangChain's interfaces could swap out any component, switch from OpenAI embeddings to Cohere, from Pinecone to pgvector, from GPT-4 to Claude, without changing their application logic.
LangChain in 2025–2026: The Maturity Phase
By 2025, LangChain had moved from growth-mode to maturity-mode. The explosive early growth plateaued, but the ecosystem had become deeply embedded in enterprise infrastructure.
Key developments in this phase:
LangGraph Cloud, a managed deployment platform for LangGraph applications, launched in 2025. Rather than self-hosting the state management infrastructure (checkpointing databases, task queues), teams could deploy directly to LangChain Inc's cloud.
LangGraph Studio, a desktop application for visually editing and debugging LangGraph workflows. Similar to Mastra Studio's local dev experience, but targeting Python teams.
LangChain Hub, a marketplace for sharing prompts, chains, and agents. Community-contributed LangChain components that teams can fork and adapt.
Model stability, as of 2026, LangChain maintains first-class integrations with OpenAI (GPT-4o, o1, o3), Anthropic (Claude Opus 4, Sonnet 4, Haiku), Google (Gemini 2.0 series), and dozens of open-weight providers via Ollama and HuggingFace. The model-agnostic layer that was LangChain's original value proposition remains its core advantage.
From LangChain to No-Code: The Taskade Genesis Path
LangChain made multi-agent AI accessible to Python developers. LangGraph made stateful workflows accessible to experienced ML engineers. Mastra made typed agent workflows accessible to TypeScript teams.
The next step in that accessibility progression, AI agent orchestration for everyone, without writing any framework code, is where platforms like Taskade Genesis enter the picture. This is the end of the vibe coding continuum: where natural language is the entire programming interface.
The parallel between LangGraph's design and Taskade's Workspace DNA architecture is not coincidental. Both emerged from the same insight: that the most powerful AI systems combine three distinct capabilities:
| LangGraph Concept | Taskade Genesis Equivalent | What It Provides |
|---|---|---|
| Graph State (TypedDict) | Projects (persistent databases) | Memory — what has been learned and stored |
| Agent Nodes (LLM + tools) | AI Agents (34 built-in tools) | Intelligence — autonomous task execution |
| Edge Routing + Tool Calls | Automations (100+ integrations) | Execution — triggers and actions in the real world |
In Workspace DNA terms: Memory feeds Intelligence, Intelligence triggers Execution, Execution creates Memory. ▲ ■ ●
The difference is accessibility. Building a LangGraph application requires:
- Installing Python 3.9+, LangGraph, LangChain Core, and provider packages
- Understanding TypedDict state schemas
- Writing node functions and routing logic
- Setting up a vector store for memory
- Managing API keys for each model and integration
- Deploying the graph to a server
Building the equivalent in Taskade Genesis requires:
- Describing what you want in a prompt
- Connecting integrations through a visual interface
- Triggering automations through events (Slack message, form submission, schedule)
- Publishing your agent, done
See the Genesis complete guide for a full walkthrough of setting up multi-agent workflows, persistent memory, and 100+ integrations without code. For team-based orchestration, the AI teams guide covers coordinating multiple agents on complex tasks.
Both approaches use the same underlying pattern, stateful agents with tools, connected by routing logic, with persistent memory. The code path and the no-code path arrive at the same architecture.
What LangChain Got Right (And Why It Matters for Every AI Builder)
Whether you use LangChain directly or not, the framework's influence on how we think about AI system design is profound. Several patterns that LangChain established are now considered standard practice:
1. Model-agnostic interfaces. The idea that your application logic shouldn't be coupled to a specific model provider is now foundational. Swap OpenAI for Anthropic without rewriting your application. This is table stakes for any modern AI framework.
2. Retrieval as a first-class primitive. Before LangChain, RAG was a research technique. After LangChain, it's the standard pattern for enterprise AI. The document loader → splitter → embedder → vector store → retriever pipeline is now how most knowledge-intensive AI applications work.
3. Composable tool use. The idea that agents should have access to a well-defined set of tools, search, calculator, code interpreter, API calls, and that tools should have consistent schemas for how the model calls them, is now the basis for OpenAI's function calling, Anthropic's tool use, and every major agent framework. See how Taskade's 33 built-in agent tools implement this same composable pattern without code.
4. Observability is not optional. LangSmith's existence and success made it clear that LLM applications need the same observability tooling as any production system, tracing, metrics, evaluation, and alerting. You can't run an AI product in production without seeing what's happening inside it.
5. State management requires explicit design. LangGraph's success with typed state made explicit what many teams learned the hard way: state that lives in a conversation history is hard to inspect, hard to test, and hard to recover from. Explicit, typed, checkpointed state is the production-grade solution.
These five insights should inform how you design AI systems, regardless of which framework (or no framework) you use.
Conclusion: The Framework That Changed Everything
Harrison Chase's October 2022 GitHub commit changed how an industry builds software. The chain abstraction he popularized wasn't perfect. It couldn't survive contact with production-scale multi-agent requirements. But it established the vocabulary, the integrations, and the community that made the AI agent era possible.
LangGraph is the mature answer to LangChain's early limitations. LangSmith is the commercial layer that will sustain LangChain Inc. CrewAI, AutoGen, and Mastra are the ecosystem that flourished in LangChain's wake.
And the no-code path, Taskade Genesis, with its 150,000+ apps built from prompts, represents the next step in accessibility: multi-agent AI for everyone, not just developers who know Python. Whether you're building AI agents faster with code or building them without code through Taskade Genesis, the destination is the same: AI systems that remember, reason, and execute on your behalf. Explore the Community Gallery or browse AI agent templates to see what others have built.
The chain that Chase started in October 2022 hasn't ended. It's become a graph. ▲ ■ ●
Frequently Asked Questions
What is LangChain used for?
LangChain is used to build applications that combine large language models with external data and tools. The most common use cases: RAG systems that answer questions about company documents, AI agents that can use web search and APIs, chatbots with persistent memory, document processing pipelines, and multi-agent workflows that coordinate several AI models to complete complex tasks. See our full AI agents guide and agentic workspaces overview for deeper coverage of agent patterns.
Is LangChain free?
LangChain (the open-source library) and LangGraph are free and MIT-licensed. LangSmith, LangChain Inc's observability product, has a free tier for low volumes and paid plans for higher usage. You still pay separately for any LLM API calls (OpenAI, Anthropic, etc.), LangChain provides the framework, not the compute.
What is the difference between LangChain 0.1 and earlier versions?
LangChain v0.1, released in January 2024, introduced a stable public API with proper deprecation cycles and semantic versioning. Earlier versions (0.0.x) changed APIs frequently between minor releases, breaking downstream code. v0.1 also reorganized the package structure, langchain-core (stable interfaces), langchain-community (third-party integrations), and provider packages like langchain-openai, reducing the dependency footprint significantly.
Can LangChain and LlamaIndex be used together?
Yes, and many production systems do use both. LlamaIndex excels at data indexing and complex retrieval, advanced chunking strategies, hybrid search, reranking, multi-document synthesis. LangChain excels at agent orchestration, tool use, and multi-step pipelines. A common pattern: use LlamaIndex for the retrieval layer and LangChain/LangGraph for the agent orchestration around it.
What is LangGraph's checkpointing and why does it matter?
LangGraph's checkpointing saves the full graph state to a persistence layer (SQLite for local development, Redis or PostgreSQL for production) at each step. This enables three critical capabilities. First, fault tolerance: if a long-running agent fails at step 7 of 12, you can resume from step 7 rather than starting over. Second, human-in-the-loop: pause the graph at any node, surface the current state for human review or approval, and resume with updated state. Third, debugging: replay any graph execution from a checkpoint to diagnose failures.
How does LangChain handle memory?
LangChain provides several memory types: ConversationBufferMemory (stores the full conversation), ConversationSummaryMemory (summarizes old turns to save context), VectorStoreRetrieverMemory (semantically retrieves relevant past interactions), and EntityMemory (tracks named entities across a conversation). In LangGraph, memory is more explicit. It's the typed state object that flows through the graph, plus optional external storage for long-term persistence across sessions.
What is the best alternative to LangChain for TypeScript?
For TypeScript/Node.js teams, the main options are langchain.js (the official JS port), Mastra (opinionated TypeScript-first framework with typed steps and built-in evals), and building directly on provider SDKs like @anthropic-ai/sdk or openai. Mastra is the most compelling alternative for teams that want LangGraph-style workflow structure with a TypeScript-native developer experience including typed Zod schemas at every step.
How does LangChain relate to MCP (Model Context Protocol)?
MCP, Anthropic's open standard for connecting AI models to tools and data sources, and LangChain's tool/integration system solve overlapping problems but at different layers. LangChain tool integrations are Python/JS code that runs in your process. MCP servers are separate processes that expose tools over a standard protocol, any MCP-compatible client (Claude Code, Mastra, custom agents) can use any MCP server without language-specific bindings. As of 2025-2026, LangChain began adding MCP support so LangGraph agents can call MCP servers as tools. See our MCP servers guide for a full breakdown.
What is the future of LangChain in 2026?
LangChain's future is LangGraph and LangSmith. The core Python library (langchain) has reached relative maturity, integrations get updated, but the fundamental architecture is stable. LangGraph continues to evolve rapidly, with LangGraph Cloud (managed deployment), LangGraph Studio (visual editor), and improved multi-agent coordination patterns. LangSmith is the commercial priority, enterprise contracts for tracing and evaluation are the revenue engine. The broader trend: LangChain is consolidating from a sprawling toolbox into a focused platform for production LLM applications.
How do I get started with LangChain?
The fastest path to understanding LangChain is to build a simple RAG application: load a PDF with PyPDFLoader, split it with RecursiveCharacterTextSplitter, embed with OpenAIEmbeddings, store in Chroma, retrieve with RetrievalQA. The LangChain documentation covers this in a 15-minute quickstart. For multi-agent workflows, start with LangGraph's documentation after you understand the basic RAG pattern. If you want multi-agent capabilities without writing code, Taskade Genesis provides the same agent + automation + memory architecture through a visual interface, starting free.
Updated June 2026. LangChain is a fast-moving project, check the LangChain changelog and LangGraph releases for the latest. For Taskade Genesis, see the Genesis complete guide, the best AI app builders comparison, and the community gallery. Related reading: best multi-agent platforms · agentic engineering history · MCP servers guide · AI agents hub · automate with Taskade.