





AI agents fail. Not occasionally — constantly. Every external API call can time out. Every tool can return malformed data. Every model response can be incomplete or hallucinated. In a polished demo, none of this shows, because the demo runs once under controlled conditions. In production, an agent might make hundreds of tool calls across a single task, and the question is never if something fails. It is what the agent does when it does.
The difference between a fragile agent and a reliable one is not a better model. It is the exception handling and recovery layer wrapped around every action the agent takes — the unglamorous engineering that turns a clever prototype into software people trust with real work. This guide builds the complete recovery ladder, rung by rung: classify the failure, retry with backoff and jitter, trip the circuit breaker, fall back gracefully, checkpoint and resume, escalate cleanly, and learn from every error. It covers both infrastructure-level healing and reasoning-level self-correction, single agents and orchestrated teams — and an honest no-code path to build the whole loop.
TL;DR: AI agents recover from errors by classifying each failure — transient, permanent, or critical — then retrying with backoff, tripping a circuit breaker, falling back gracefully, or escalating cleanly to a human. Research finds multi-agent systems fail 41–86 percent of the time without this discipline. Self-healing agents fail well instead of crashing. Build a reliable agent free →
How Do AI Agents Recover From Errors?
AI agents recover from errors by wrapping every action in a try-catch loop, classifying the failure that occurs, and routing it to the right recovery action. A transient error (timeout, rate limit) is retried with backoff. A permanent error (bad input, missing resource) triggers a fallback plan. A critical error (budget overrun, destructive side effect) saves state and escalates to a human. The agent never simply crashes — it makes a decision.
This pattern is borrowed directly from decades of distributed-systems engineering. Payment processors retry failed transactions and fall back to alternate gateways. Content delivery networks serve stale content when an origin is down. AI agents face the same reliability problem, amplified: an autonomous agent running an agentic loop compounds a single unhandled error across every subsequent step.
The full recovery loop has a recognizable shape. The agent attempts an action, checks whether it worked, and on failure branches into one of three handling paths — each with its own ladder back toward "continue working."
The single most important node in that diagram is the diamond in the middle: What kind of error is this? Everything downstream depends on classifying the failure correctly. Get the classification wrong and you retry an error that will never clear, or you give up on one that would have resolved in 200 milliseconds. This is the load-bearing decision the rest of this guide unpacks — and it is exactly the discipline the wiki covers as agentic exception handling.
Why Do AI Agents Fail So Often in Production?
Multi-agent AI systems fail between 41 percent and 86.7 percent of the time on real tasks, according to the MAST study (Why Do Multi-Agent LLM Systems Fail?, NeurIPS 2025), which hand-annotated 150+ execution traces to derive its failure taxonomy (validated across a larger 1,600+ trace dataset). The researchers found that failures are not random — they cluster into 14 distinct modes across three root categories: specification issues (42 percent), inter-agent coordination breakdowns (37 percent), and weak verification (21 percent). This is the data wedge most reliability advice skips: agents do not fail in infinite unique ways, so recovery can be systematic.
Failure also compounds. Each step in an agentic task carries its own probability of going wrong, and those probabilities multiply across the chain. An agent that is 99 percent reliable per step is not 99 percent reliable per task.
PER-STEP RELIABILITY → TASK SUCCESS RATE (compounding) 99% per step ^ 7 steps = ~93% ( 1 in 14 tasks fails )
99% per step ^ 20 steps = ~82% ( 1 in 5 tasks fails )
95% per step ^ 20 steps = ~36% ( 2 in 3 tasks fail )
95% per step ^ 7 steps = ~70% ( ~1 in 3 tasks fails )
The lesson: long agent chains amplify small per-step error
rates. Recovery is not a nice-to-have — it is the only thing
standing between a 99% tool and a coin-flip task.
The MAST taxonomy is diagnostic, not prescriptive — it tells you why agents fail but stops short of what to do about it. That synthesis gap is what this guide fills. Each root cause maps cleanly to a recovery pattern.
Here is the explicit bridge from each MAST root cause to the recovery pattern that addresses it — the map no competitor draws:
| Root Cause (share) | Representative Failure Mode | Matching Recovery Pattern |
|---|---|---|
| Specification (42%) | Agent loses task scope, ignores a constraint | Scoped tools + goal monitoring |
| Coordination (37%) | Specialists drop context, duplicate work | Orchestration + per-branch failure isolation |
| Coordination (37%) | One agent stalls and blocks the team | Circuit breaker + bulkhead isolation |
| Verification (21%) | Wrong output accepted as final | Reflection + output validation |
| Verification (21%) | No check before a destructive action | Human-in-the-loop escalation |
Anthropic's engineering team reaches a complementary conclusion in Building Effective Agents: the most reliable systems favor simplicity — the fewest moving parts that solve the problem — and add orchestration only where it earns its keep. Fewer components means fewer failure modes. We will return to that lesson repeatedly.
What Are the Three Types of Agent Errors?
Agent errors fall into three classes, and each demands a different response. Treating all errors the same way is the most common reliability mistake — it leads to retrying unrecoverable failures and abandoning recoverable ones. The classifier that sorts raw failures into these buckets is the foundation of every reliable agent.
| Error Class | Examples | Will Retry Help? | Right Response |
|---|---|---|---|
| Transient | Timeout, rate limit, network blip, brief 5xx | Yes — usually clears on its own | Retry with exponential backoff + jitter |
| Permanent | Invalid input, 404 missing resource, malformed data, auth rejected | No — same result every time | Fall back: simpler method, cached data, default, or human |
| Critical | Budget overrun, destructive side effect, safety violation, scope breach | No — and retrying is dangerous | Save state, alert a human, possibly emergency stop |
Transient errors are temporary. The service was briefly overloaded, the network dropped a packet, you hit a per-minute rate cap. These clear on their own, so the correct move is to wait and try again. The whole art is in how you wait.
Permanent errors will not change on retry. If you sent malformed input, sending it again produces the same rejection. If a resource does not exist, asking for it ten more times will not conjure it. Retrying a permanent error is pure waste — wasted time, wasted budget, and a worse user experience. Permanent errors need a fallback.
Critical errors are the ones where continuing is itself the risk. An agent about to delete the wrong records, blow past a spending limit, or take an action outside its scoped permissions should not retry or quietly fall back. It should stop, preserve everything, and bring a human in. This connects directly to agentic goal monitoring and resource-aware optimization — the systems that watch for limit breaches before they become damage.
In practice, classification often starts with the error signal itself. HTTP status codes and provider error types map predictably to these classes, which is why a good classifier can ship with sensible defaults before you encode any domain knowledge. Microsoft's Azure retry-pattern guidance makes the same distinction the cornerstone of resilient cloud design.
| Signal | Class | Action |
|---|---|---|
429 Too Many Requests |
Transient | Retry with backoff (honor Retry-After) |
503 / 502 / timeout |
Transient | Retry with backoff, then circuit-break |
400 Bad Request / 422 |
Permanent | Skip retry → fallback |
404 Not Found |
Permanent | Fallback or escalate (missing dependency) |
401 / 403 auth |
Permanent | Escalate — credentials need a human |
| Budget / quota exceeded | Critical | Stop, save state, alert a human |
Domain knowledge layers on top: your system knows that a 429 is transient, a 400 is permanent, and a "delete 10,000 rows" tool call against an unexpected target is critical regardless of the status code that comes back.
Idempotency: The Foundation That Makes Retries Safe
Idempotency is the property that running an action twice produces the same result as running it once — and it is the precondition that makes every retry pattern in this guide safe. Without it, a retry is not recovery; it is a second charge on a credit card, a duplicate email, a doubled database row. You cannot safely retry an action you cannot safely repeat.
The standard mechanism is an idempotency key: a unique identifier attached to each operation. Before performing the action, the system checks whether that key has already been processed. If it has, it returns the original result instead of doing the work again. This is how payment APIs let clients retry a charge after a network timeout without fear of double-billing.
For agents, idempotency-first design means writing tools so that re-running them is harmless. A "create record if not exists" tool is safe to retry; a blind "create record" tool is not. Design the safe version first, and the entire recovery ladder above it becomes trustworthy. Skip it, and every retry is a gamble.
Why Do Retries Need Backoff and Jitter?
Retries handle transient failures, but naive retries make things worse. Hammering a rate-limited API the instant it rejects you guarantees another rejection — and if thousands of agents retry in lockstep, they create a thundering herd that keeps the service down. The fix, formalized in the AWS Builders' Library guidance on timeouts, retries, and backoff with jitter, is exponential backoff with randomized jitter: wait longer after each failure, and randomize the wait so retries spread out.
The pattern is simple. After the first failure, wait one second. After the second, two seconds. Then four, then eight — doubling each time. Add a random offset (jitter) so two agents that failed simultaneously do not retry simultaneously. And cap the total attempts, because some "transient" errors are permanent in disguise.
The retry cap is non-negotiable. Without it, an agent that hits a genuinely permanent error spins forever, burning budget and blocking the user. The cap is the boundary where the agent admits "this is not going to clear" and crosses into fallback territory. This is closely related to the broader problem of agentic loops — runaway repetition that produces no progress. A retry without a cap is just a loop with extra steps.
Taskade's automation builder shows this guardrail in product form: loops have explicit bounds, so a recovery path can repeat safely without spinning out.
There is a subtler decision hidden here, too. Some failures should not be retried even once. A 400 Bad Request is the service telling you the input is wrong; retrying it is pointless. A well-designed classifier sends those straight to fallback, skipping the retry ladder entirely. Retrying is only ever the right call for genuinely transient errors.
Circuit Breakers: When to Stop Retrying Entirely
A circuit breaker stops an agent from retrying a service that is clearly down — it is the proactive cutoff that retries and fallbacks (both reactive) cannot provide. The pattern, defined canonically in Martin Fowler's CircuitBreaker article, wraps a call path in a small state machine with three states: closed (calls flow normally), open (calls fail fast without even trying), and half-open (a single probe call tests whether the service has recovered).
The trigger is a failure threshold. When failures cross a limit — say, five failures in a row — the breaker trips open and the agent stops calling the dead service entirely. After a cooldown, it moves to half-open and lets one probe through. If the probe succeeds, the breaker closes and normal traffic resumes. If it fails, the breaker re-opens and waits again.
The payoff is twofold. First, the breaker prevents a cascading failure: one dead dependency does not drag every dependent task down with it. Second — and this is unique to AI agents — it prevents runaway token spend. A retry loop against a down model endpoint can burn real money fast. The breaker caps that exposure by refusing to call a path it knows is failing. Portkey's resilience framework frames this cleanly as reactive-versus-proactive: retries and fallbacks react to a failure that already happened; the circuit breaker proactively refuses to make a call it expects to fail.
What Is a Fallback Plan and How Does It Work?
A fallback plan is the agent's answer to a permanent failure: a degraded-but-useful path that delivers partial value when the ideal one is unavailable. This is the principle of graceful degradation — a smaller problem beats a total failure. The user gets something useful rather than a blank error screen.
There are four common fallback strategies, in rough order of preference:
- Use a simpler method. If the sophisticated approach fails — a complex query, a specialized tool — fall back to a simpler one more likely to succeed. A failed structured extraction can fall back to returning the raw text.
- Use saved or cached data. If a live source is unavailable, serve the last known good value. A weather agent whose API is down can return the cached forecast with a clear "as of" timestamp. Stale data with a caveat usually beats no data.
- Use a sensible default. When no real answer is available, a well-chosen default keeps the workflow moving. A pricing lookup that fails can fall back to a standard rate flagged for review.
- Get a human. When automation genuinely cannot proceed, route to a person. This is not a failure of the agent — it is the agent knowing its limits, which is a feature.
One caution from distributed-systems practice: fallbacks that share a failure domain with the primary are not real fallbacks. If your fallback model lives behind the same gateway that just failed, it fails too. Good fallback chains route to independent paths — a different provider, a local cache, a precomputed default — so a single outage cannot take the whole ladder down.
Notice the bottom of the diagram: every recovery path ends in logging and pattern tracking. This is what separates a self-healing agent from one that merely survives. An agent that records its failures — which tool failed, what fallback it used, how often — produces the data that lets engineers fix root causes. Recovery without observability is just forgetting in slow motion. The discipline of capturing this is agent observability.
Retry vs Fallback vs Circuit Breaker: Which When?
The four core recovery patterns are not interchangeable — each triggers on a different failure shape, and using the wrong one is its own failure mode. This is the unified decision framework no single competitor provides: a clean map of which pattern, when, and what it costs if you misuse it.
| Pattern | Triggers On | Reactive / Proactive | Cost If Misused |
|---|---|---|---|
| Retry + backoff | Transient errors | Reactive | Token burn + thundering herd if uncapped |
| Circuit breaker | Repeated failures to one service | Proactive | Blocks a recovered service if cooldown too long |
| Fallback chain | Permanent failure on primary | Reactive | Silent quality drop if degradation hidden |
| Escalate to human | Critical / irrecoverable | Reactive | Alert fatigue if over-triggered |
The patterns also compose. A single failure can travel the full ladder: retry it a few times, trip the breaker if the service stays down, fall back to a degraded path, and escalate only if even the fallback fails. The decision tree below shows that composition as an aligned-column flow — the kind of branching that reads more clearly as ASCII than as a diagram.
ERROR CAUGHT
│
├─ transient? ───── yes ──► RETRY LADDER (backoff + jitter)
│ │
│ ├─ success ──────────► CONTINUE
│ └─ cap hit ──┐
│ ▼
│ repeated fails to service?
│ │
│ └─ yes ─► TRIP CIRCUIT BREAKER
│ (fail fast, cool down)
│
├─ permanent? ──── yes ──► FALLBACK AVAILABLE?
│ │
│ ├─ yes ─► DEGRADE (simpler / cached / default)
│ └─ no ──► ESCALATE
│
└─ critical? ───── yes ──► SAVE STATE + ESCALATE (never retry)
Read it top to bottom: classification gates everything, retries handle the temporary, the breaker handles the persistently broken, fallbacks handle the permanent-but-recoverable, and escalation handles the rest. The patterns layer; they do not compete.
What Makes an AI Agent Self-Healing?
A self-healing AI agent detects and recovers from transient failures automatically, preserves state to resume after interruptions, and learns from every failure. Self-healing is not magic — it is the combination of three concrete capabilities, each of which breaks something specific if absent.
| Capability | What It Means | What Breaks Without It |
|---|---|---|
| Automatic recovery | Retry, breaker, and fallback run unattended | Every transient blip needs a human |
| State preservation | Checkpoint progress; resume, don't restart | Crash at step 9,000 throws away 9,000 steps |
| Learning from failure | Log + analyze recoveries over time | Same failure recurs forever, never improves |
Automatic recovery means the retry-and-fallback loop runs without anyone watching. The agent hits a rate limit, backs off, retries, and continues — the user never notices the hiccup. This is the baseline.
State preservation means the agent checkpoints progress so an interruption does not discard completed work. A pipeline that processes 10,000 records and fails at 9,000 should resume from 9,000, not restart from zero. For agents, the equivalent is preserving agent memory — working context, intermediate results, decisions made — so the agent picks up where it left off. The checkpoint/resume handoff looks like this:
Learning from failure closes the loop. By tracking error patterns over time, the system spots that a particular tool fails 30 percent of the time, or that a specific input format always triggers a fallback. That signal feeds better classification, smarter retry policies, and — through agent evaluation — measurable improvement release over release. This is the agentic learning loop in action.
The honest caveat: self-healing has limits, and pretending otherwise is how you build systems that fail silently. A self-healing agent should heal what it can — transient errors, recoverable interruptions — and escalate loudly what it cannot. The worst outcome is an agent that "recovers" from a critical error by quietly producing wrong output. Silent success on a failed task destroys trust faster than any visible error. The bio-inspired framing in Self-Healing Software Systems (arXiv 2025) makes the same point: natural systems heal locally and signal globally — they do not mask damage.
Reflexion and Self-Correction: Reliability at the Reasoning Layer
Not every agent failure is an infrastructure failure. Some are reasoning failures — a wrong answer, a flawed plan, a hallucinated fact — and no amount of retrying the same call fixes a bad chain of thought. This is the second half of reliability that infrastructure patterns alone cannot reach: in-flight self-correction at the reasoning layer.
The canonical mechanism is Reflexion, introduced in Reflexion: Language Agents with Verbal Reinforcement Learning (Shinn et al.). Instead of just retrying, the agent generates a verbal self-critique of its failed attempt, stores that reflection in memory, and retries conditioned on the prior error. The result: Reflexion reached 91 percent pass@1 on HumanEval, compared with roughly 80 percent for the GPT-4 baseline it was built on — a double-digit gain from reasoning-level healing alone. Follow-up work in Self-Reflection in LLM Agents (arXiv 2024) corroborates that structured self-reflection measurably lifts problem-solving performance.
The two layers complement each other. Infrastructure recovery heals the call; reflection heals the reasoning. A production agent needs both — and the distinction maps cleanly:
| Layer | Heals What | Mechanism | Example |
|---|---|---|---|
| Infrastructure | Failed calls, dead services | Retry, breaker, fallback, checkpoint | A 429 clears after backoff |
| Reasoning | Wrong answers, flawed plans | Reflexion, self-critique, validation | A buggy function gets rewritten after self-review |
The reflection pattern is the reusable building block here. Pair it with infrastructure recovery and you cover both halves of the reliability problem — the network and the thinking.
Isolating Failure in Multi-Agent and Parallel Workflows
In an orchestrated multi-agent system, the core reliability question is isolation: when one specialist fails, does the rest of the task keep going? The pattern that guarantees yes is the bulkhead — borrowed from ship design, where watertight compartments stop one breach from sinking the whole vessel. Applied to agents, each parallel branch runs in its own compartment, so one failure floods only its own cell.
This directly addresses MAST's 37-percent coordination-failure share. Without isolation, a single stalled or crashed specialist blocks every sibling and the orchestrator hangs. With it, the failed branch is contained, the healthy branches complete, and the orchestrator merges partial results.
This is where good routing and parallelization earn their reliability dividend: route work to independent specialists, run them in parallel, and isolate failure per branch. Combined with agent task prioritization, the orchestrator can even decide that a non-critical branch's failure is acceptable and ship the rest — partial output beating no output, at the team level. For the full production playbook, see our multi-agent collaboration lessons and the broader agentic design patterns reference.
When Should an Agent Escalate to a Human?
An agent should escalate to a human when a failure is critical, irrecoverable, or exceeds its scoped permissions. The decision is not about capability — it is about safety and trust. An agent that knows when to stop is more valuable than one that plows ahead and causes damage.
The escalation triggers are specific:
- Retries exhausted on a path with no fallback. The agent tried, backed off, tried again, and no degraded option delivers acceptable value.
- A destructive or irreversible side effect is detected. Deleting data, sending external communications, spending money — anything where being wrong cannot be undone.
- A budget or resource limit is crossed. The task is consuming far more than expected, a signal something went wrong. This ties back to resource-aware optimization.
- A decision exceeds the agent's scoped authority. A well-designed agent has explicit limits. Hitting one is a feature — the human-in-the-loop boundary working as designed.
Good escalation has a craft to it, and it is missing from almost every guide. It is not throwing a stack trace. The agent should save the current work, attach full context — what it was doing, what failed, what it already accomplished — and hand off cleanly. The difference between escalation that helps a human and escalation that dumps work on them is the summary-exit discipline below.
A clean handoff that says "I completed steps 1 through 4, hit this specific wall on step 5, and here is everything I have" is worth far more than a raw error dump. Constraining an agent this way makes it more reliable, not less capable — the same lesson that holds across agent orchestration. An agent with clear failure boundaries is one you can actually deploy.
The Learning Loop: Turning Failures Into Reliability
The learning loop is what turns a logging habit into measurable, release-over-release reliability gains — and it is the pattern almost no competitor names. The premise is simple: every recovery event is data. Capture it, find the patterns, and feed them back into smarter classification and retry policy. An agent that recovers but never learns will recover from the same failure forever.
Concretely, the loop produces decisions: a tool that fails 30 percent of the time gets a wrapper, a fallback, or replacement. An input format that always triggers degradation gets pre-validated. A model that times out under load gets a circuit breaker tuned to its real failure rate. None of these improvements are possible without the log — which is why agent observability and the agentic learning loop are the same investment viewed from two angles. Reliability is not a one-time build; it is a flywheel.
Cost and Budget Circuit-Breaking
Retry storms and runaway loops do not just waste time — they burn real money and tokens, which is why budget itself belongs in the critical-error class. A circuit breaker that only watches HTTP status codes misses the most expensive failure mode in agentic systems: an agent that technically succeeds on every call while looping uselessly and spending unboundedly.
The fix is a budget circuit breaker: a hard cap on tokens, tool calls, or wall-clock time per task. Cross it, and the breaker trips to the critical path — save state, stop, escalate — regardless of whether any individual call "failed." This is the same loop-protection discipline from the retry-cap section, applied to spend instead of attempts. Resource-aware optimization and agentic goal monitoring are the systems that watch these meters in real time and trip the breaker before the bill, not after.
BUDGET GOVERNORS (any breach → critical path) token budget ▸ 50K tokens / task → trip → save + escalate
tool-call cap ▸ 40 calls / task → trip → save + escalate
wall-clock ▸ 5 min / task → trip → save + escalate
loop guard ▸ same step ×3 → trip → break the loop
A task can "succeed" on every call and still be a failure
if it never converges. Cost caps catch what status codes miss.
The honest framing: a runaway agent that burns a month of budget in an hour is a worse production incident than one that crashes cleanly. Caps make the failure visible and bounded instead of silent and unbounded.
Observability: Recovery Without Logging Is Forgetting in Slow Motion
Observability is the precondition for every improvement in this guide — you cannot fix, tune, or trust what you cannot see. A recovery system that heals failures but records nothing is a black box: it might be saving you, or it might be silently masking a systemic problem that gets worse every release.
The minimum to capture on every recovery event: which tool or service failed, which class the error was assigned, which recovery path fired (retry, breaker, fallback, escalate), how many attempts it took, and whether the outcome was full, partial, or escalated. With those five fields, you can answer the questions that drive reliability work — which tool is your weakest link, which fallback fires most, whether your circuit-breaker thresholds match reality. This is the data backbone of agent observability, and it is what makes the learning loop above possible at all.
A Complete Reliability Stack
The seven patterns in this guide are not a menu to pick from — they are layers that stack, each resting on the one below. Idempotency makes retries safe; retries and breakers handle the call; fallbacks and checkpoints preserve the work; escalation, observability, and the learning loop govern the whole system. This is the master architecture no single competitor assembles end to end.
┌─────────────────────────────────────────────────────────┐
│ GOVERNANCE Escalate · Observe · Learn │
├─────────────────────────────────────────────────────────┤
│ RESILIENCE Checkpoint/Resume · Failure Isolation │
├─────────────────────────────────────────────────────────┤
│ RECOVERY Retry+Jitter · Circuit Breaker · Fallback │
├─────────────────────────────────────────────────────────┤
│ FOUNDATION Idempotency (safe-to-retry actions) │
└─────────────────────────────────────────────────────────┘
every layer above depends on the one below it
Rendered as a dependency graph, the same stack shows why you build bottom-up: skip idempotency and the recovery layer is unsafe; skip observability and the governance layer is blind.
How Does Taskade Build This Into AI Agents?
Taskade gives you the no-code path to the same reliability ladder engineers otherwise hand-roll — orchestration, transparency, and an integration surface that turns recovery into action. The coordinator is Taskade EVE, the Taskade Genesis meta-agent that plans how work gets done and surfaces what happened along the way, honestly, including when something fails.
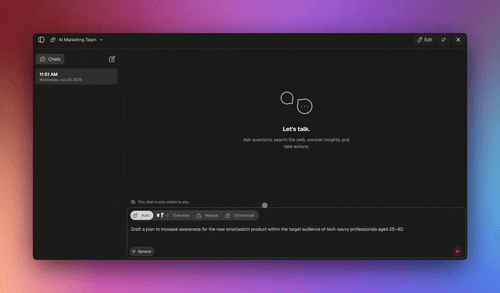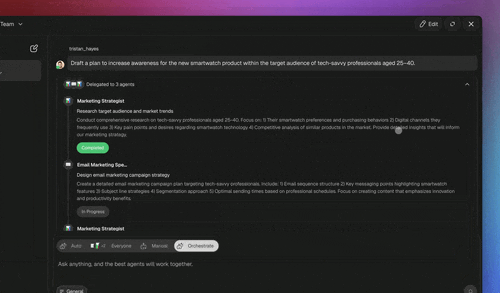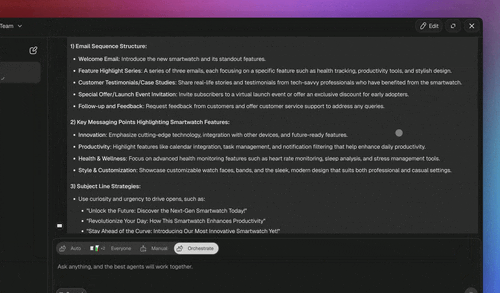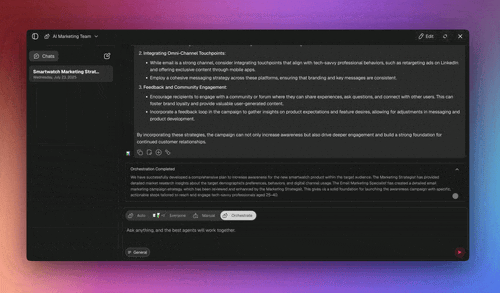
Agents operate in three modes, each with a distinct reliability posture — and Orchestrate mode delivers the parallel-branch failure isolation from the multi-agent section without writing a line of bulkhead code:
| Mode | What It Does | Reliability Role |
|---|---|---|
| Simple | One agent answers directly | Lowest surface area — fewest places to fail |
| Manual | You direct each step | Human-in-the-loop by design — built-in escalation |
| Orchestrate | Taskade EVE coordinates specialists | Failures isolate per specialist; the rest continues |
Under the hood, agents draw on 15+ frontier models from OpenAI, Anthropic, Google, and open-weight providers, with Auto as the default — which is a built-in model-level fallback. A degraded or unavailable model does not block the work; Auto routes each request to a capable model scaled by your plan — cheaper work to fast models, harder work to more capable frontier models — without you pinning a single version. Each agent's 34 built-in tools are a scoped, well-chosen set — and the loop-protection lesson applies: fewer tools, fewer failure modes.
When something does fail, Taskade's approach is transparency over silence. The user sees a summary of completed work rather than a dead end — the graceful summary-exit pattern, productized. And because Taskade connects to 100+ bidirectional integrations, escalation becomes action: a failure can trigger an automation that notifies a team, opens a ticket, or kicks off a follow-up.
This is the Workspace DNA loop applied to reliability, mapped to the recovery ladder above:
WORKSPACE DNA → RECOVERY LADDER Memory ▸ preserves the state an agent resumes from (checkpoint)
Intelligence ▸ classifies the failure, picks the path (classify)
Execution ▸ carries escalation through an integration (escalate→action)
An honest scoping note: Taskade provides the orchestration, transparency, and integration surface to build resilient workflows. The recovery policies — which errors retry, which fall back, where the human boundary sits — are yours to design for your domain. Taskade does not auto-write your retry policy, and there are no unshipped validators implied here. What it removes is the wiring: you express the recovery shape, the platform runs it.
How to Build This in Taskade (No Code)
Here is a concrete recovery pattern built without writing a wrapper. The goal: an agent that researches a topic, and if a step fails, notifies a human and resumes from where it stopped — the escalation-as-action and checkpoint patterns combined.
- Describe the workflow in one prompt. In Taskade Genesis, ask for "a research agent that summarizes a topic, and an automation that messages me on Slack if it gets stuck." Taskade Genesis generates the agent plus the automation scaffold together.
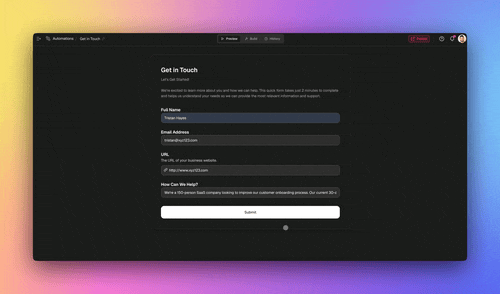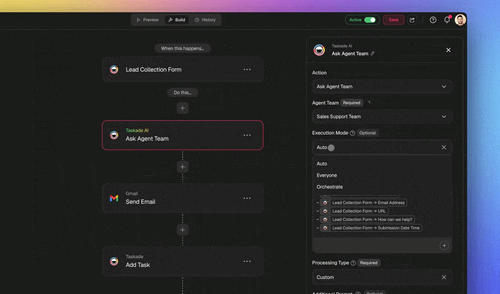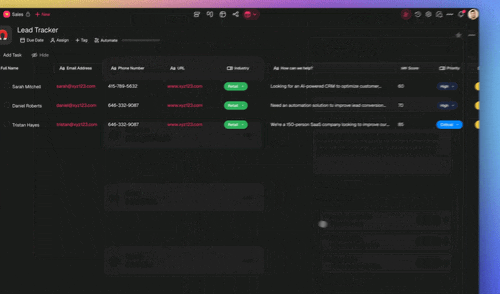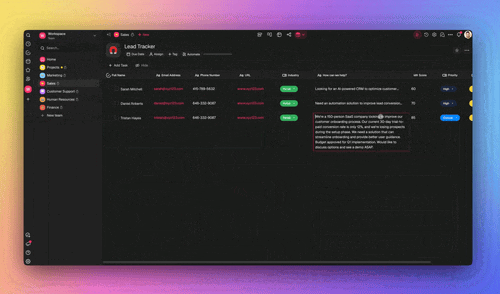
- Pick the execution mode. Use Orchestrate so research and summarization run as isolated specialists — one stalling does not sink the other.
- Wire the escalation. Connect a Slack or email integration so a stuck step triggers a real notification with the work completed so far attached, not a silent failure.
- Let Auto handle model fallback. Leave the model on Auto so a degraded provider routes to a healthy one automatically.
The result is the recovery loop from this guide — isolated execution, model fallback, clean escalation, work preserved — assembled from a prompt rather than hand-coded. You still own the policy; Taskade owns the plumbing. Explore real builds in the Community Gallery, then start with your first agent.
The Core Lesson: Reliability Is a Design Choice
The gap between a demo agent and a production agent is not intelligence. It is the boring, deliberate engineering of what happens when things go wrong. Classify the failure. Retry the transient ones with backoff and jitter. Trip the breaker on dead services. Fall back gracefully on the permanent ones. Checkpoint so a crash costs steps, not the whole task. Escalate the critical ones cleanly. Log everything so the system gets better. None of this is glamorous, and all of it is what makes an agent trustworthy.
The agents people actually rely on are not the ones that never fail — those do not exist. They are the ones that fail well: predictably, transparently, and with the user's work preserved. Build the recovery layer first, and the intelligence on top has somewhere safe to stand.
For adjacent reliability work, pair this with keeping AI agents safe and on-policy and the context-engineering field guide — what goes into the prompt window shapes how often the agent fails in the first place. For how reasoning quality interacts with reliability, see AI reasoning models explained and the agentic engineering discipline behind it all.
▲ ■ ● Memory preserves the state. Intelligence chooses the recovery. Execution carries it through.
Frequently Asked Questions
How do AI agents recover from errors?
AI agents recover by classifying each failure, then choosing a response: transient errors get retried with backoff and jitter, permanent errors trigger a fallback, and critical errors save state and escalate. The recovery loop wraps every tool call so one failure never crashes the task.
What are the three types of agent errors?
Transient errors (timeouts, rate limits) are temporary and should be retried. Permanent errors (bad input, missing resource) will not change on retry and need a fallback. Critical errors (budget overruns, destructive side effects) require saving state and escalating to a human.
Why do AI agents fail so often in production?
The MAST study traces failures to three root causes — specification (42%), coordination (37%), verification (21%) — across 14 modes. Failure also compounds: at 99% per-step reliability, a 20-step task succeeds only ~82% of the time.
Why do retries need backoff and jitter?
Backoff waits longer after each failure so you do not hammer a struggling service; jitter randomizes the wait so many agents do not retry in lockstep and cause a thundering herd. A retry cap then prevents infinite loops by switching to a fallback.
What is a circuit breaker for an AI agent?
A circuit breaker has three states — closed, open, half-open — and trips open after a failure threshold so the agent stops calling a dead service. It prevents cascading failures and runaway token spend by failing fast instead of retrying a doomed path.
How does a fallback plan work for AI agents?
A fallback gives a degraded but useful path: a simpler method, cached data, a sensible default, or a human handoff. Graceful degradation means partial output beats no output — but a real fallback must route to an independent path, not one sharing the primary's failure domain.
What is the difference between retrying and falling back?
Retrying repeats the same action and only helps transient errors that may clear on their own. Falling back changes the approach entirely — a simpler method, cached data, or a human handoff — and is the right move for permanent errors that will never change.
What makes an AI agent self-healing?
Three capabilities: automatic recovery (retry, breaker, fallback unattended), state preservation (checkpoint and resume, not restart), and learning from failure (log and analyze recoveries to improve). Crucially, it heals what it can and escalates loudly what it cannot.
When should an AI agent escalate to a human?
When a failure is critical or irrecoverable: retries exhausted with no fallback, a destructive side effect, a budget or safety limit crossed, or a decision beyond its scoped permissions. Good escalation saves state, attaches context, and hands off cleanly.
How does Taskade make AI agents reliable?
Through Taskade EVE coordinating Simple, Manual, and Orchestrate modes, where Orchestrate isolates failures per specialist. Agents use 34 built-in tools and Auto model routing as built-in fallback, surface failures transparently, and let 100+ integrations turn escalation into real follow-up action.
Companion Reads — The Reliability Cluster
- Agentic Design Patterns — the full pattern catalog this recovery ladder sits within.
- Multi-Agent Collaboration in Production — loop protection, context isolation, and the guardrails-make-agents-better thesis.
- AI Guardrails Explained — the policy layer that sits alongside exception handling.
- The Context Engineering Field Guide — fewer failures start with better context.
- What Is Agentic Engineering? — the discipline behind agents that hold up in production.
- AI Agents Taxonomy — where recovery-capable agents sit in the broader landscape.
- AI Reasoning Models Explained — how reasoning quality interacts with reliability.
For the conceptual deep-dives, see the wiki on agentic exception handling, the agentic learning loop, and exploration and discovery.
Stan Chang is CTO and co-founder at Taskade. He leads the engineering team behind Taskade's AI agents, Taskade Genesis, and the automation platform, and writes the engineering series on building production AI systems.