






Self-improving AI agents are systems that critique and revise their own output before delivering it, and in 2026 the pattern that makes this work is Reflection: a closed generate → critique → revise loop. Instead of trusting the first draft, the agent generates an answer, judges it against concrete criteria, fixes what failed, and repeats until the output passes or hits a limit. The pattern separates producing an answer from judging it, and that separation is what lets an agent catch mistakes it would otherwise ship.
But there is a catch the tutorials skip: an agent grading its own homework usually agrees with itself. The single most important idea in this guide is the line between self-critique that fails (intrinsic, the coherence trap) and grounding that works (tests, execution, retrieval, separate critics). Get that line right and reflection turns a one-shot generator into a reliable system. Get it wrong and you pay 2-3x the cost to ship the same mistakes more confidently.
TL;DR: Self-improving agents use the Reflection pattern, a generate → critique → revise loop, to catch mistakes before delivery. Naive self-critique fails (the coherence trap); grounded critique wins (tests/execution/retrieval). Reflexion hit 91% HumanEval pass@1. Most gains land in pass 1-2, so cap iterations. Build a self-checking agent free →
What Is the Reflection Pattern in AI Agents?
Reflection is a closed feedback loop where an AI agent evaluates its own output against quality criteria and revises until the output passes or an iteration limit is reached. Andrew Ng named it one of the four agentic design patterns (alongside Planning, Tool-use, and Multi-agent) in 2024, and it is now standard in production stacks. The mechanism has three roles: a generator that drafts, a critic that scores against a rubric or test, and a reviser that fixes each flagged issue.
The core insight is that generation and critique are different cognitive tasks. Ask a model to "write a great function" and it optimizes for plausibility. Ask the same model to "find every bug in this function" and it switches into an adversarial mode, surfacing problems it would never have avoided while writing. Reflection exploits that mode switch deliberately, and the broader reflection pattern is one node in a wider family of agentic design patterns.
The loop never runs forever. Two guardrails keep it bounded: an iteration cap (stop after N revisions) and an early exit (stop when the critic reports no actionable issues). When the loop hits the cap without converging, the system falls back to the best version it produced rather than the last one. That discipline, borrowed from how an agentic learning loop bounds itself, is the difference between reflection and a runaway agent.
How Does a Self-Improving Agent Catch Its Own Mistakes?
A self-improving agent catches mistakes by making the critique step concrete and testable rather than subjective. A vague "review your answer and improve it" prompt produces vague improvements, the model agrees with itself and ships the same flaws. A precise rubric ("does the code pass these unit tests? does each claim cite a source? are all five required sections present?") gives the critic something it can actually fail. The difference between a working loop and theater is whether the critic can return no on a draft that deserves it.
The strongest reflection systems do not ask the model whether its work is good. They run real checks. A code agent executes the tests. A research agent re-queries its sources. A data agent recomputes the numbers. The model's opinion of its own work is the weakest signal; an external check is the strongest. This is why tool access separates a reflection loop that works from one that just feels productive.
Here is the worked critique trail for drafting a technical document, each pass produces specific, named feedback, and each revision addresses a named issue:
Draft 1 → Critic: "Section 3 contradicts Section 1 on pricing.
Code example on line 42 will not compile.
Missing the required 'limitations' section."
Draft 2 → Critic: "Pricing now consistent. Code compiles.
Limitations section added but two sentences too vague."
Draft 3 → Critic: "No actionable issues." → EXIT, deliver Draft 3
That specificity is the difference between an agent that converges on a correct answer and one that drifts sideways through equally-wrong variants. Vague feedback ("make it better") moves the draft randomly; named feedback ("line 42 won't compile") moves it toward correct. The same discipline underpins agent evaluation more broadly, and it pairs directly with reducing hallucinations, a grounded critic catches a fabricated citation that an opinion-based critic waves through.
Why Naive Self-Critique Fails: The Coherence Trap
Naive self-critique fails because of the coherence trap: when one model both writes and judges, the generator and the evaluator share the same blind spots, so an error invisible during writing stays invisible during review. The model that confidently wrote a wrong line of reasoning is the same model now asked to find the flaw in it, and it tends to rate its own coherent-sounding output as correct. The 2023 paper "Large Language Models Cannot Self-Correct Reasoning Yet" (Huang et al.) found that without an external signal, intrinsic self-correction can lower accuracy on reasoning tasks rather than raise it. The model isn't checking against truth. It's checking against its own prior.
There is a second, sneakier failure: the sycophancy / FlipFlop effect. Challenge an LLM's answer, even a correct one, and it will often capitulate and "correct" itself into a worse answer. A self-critique prompt that says "are you sure? find the mistakes" can talk a model out of a right answer it should have kept. This is why "challenging the model harder" is not a fix; it is the bug.
The takeaway is blunt: intrinsic reflection is a confidence-laundering machine unless you ground it. The fix is not a better prompt. It is an external truth signal the model cannot argue with. That is the next section.
Grounded vs Intrinsic Self-Correction: Where the Real Gains Live
The real gains live in grounded self-correction, wiring the critic into an external truth source so its feedback reflects reality rather than the model's opinion. Intrinsic correction asks "does this look right to me?" Grounded correction asks "did the test pass? does the retrieved source agree? does the calculator confirm the number?" The first is fragile; the second is durable. CRITIC (Gou et al., 2024) made this the whole thesis: LLMs self-correct reliably only when they verify against tools.
There are four practical grounding signals, ordered roughly by strength:
GROUNDING SIGNAL WHAT IT CHECKS AGAINST STRENGTH
------------------------ ------------------------------- --------
Execution / tests Compiler + unit test results strongest
Retrieval (RAG/Self-RAG) Live source documents strong
Tool / calculator output Deterministic computation strong
Separate-model critic A different model's blind spots moderate
Intrinsic self-critique The same model's own opinion weakest
Notice that even a separate model critic is "moderate," not "strong", swapping the model breaks shared blind spots but still grades against opinion, not truth. The strongest reliability lever in the whole pattern is an objective check: code that runs, a source that confirms, a number that recomputes.
| Approach | How the critic gets its signal | Reliability | Relative cost | Example |
|---|---|---|---|---|
| Intrinsic | Same model judges itself | Low | 2x | "Re-read and improve" |
| Separate critic | Different model, own rubric | Medium | 2-3x | Critic agent reviews draft |
| Retrieval-grounded | Re-query source documents | High | 2-3x | Self-RAG verifies each claim |
| Tool-grounded | Calculator / API / search | High | 2-3x | CRITIC checks a fact via search |
| Execution-grounded | Run the code, read results | Highest | 2-3x | Reflexion runs the unit tests |
| PRM-graded | Process reward model scores steps | Highest | 3x+ | AgentPRM rewards each reasoning step |
The 2026 frontier of grounding is the process reward model (PRM), a model trained to score each step of a reasoning trace, not just the final answer, giving the critic a dense, learned truth signal. The honest builder's rule: if you can run a test, run the test. Save intrinsic critique for the soft, subjective polish that no test can capture, and even then, hold it on a short leash.
Self-Reflection vs a Separate Critic Agent: Which Is Better?
Neither is universally better, the choice trades cost against blind-spot coverage. Self-reflection uses one model for both drafting and critique. It is cheaper, faster, and simpler to wire up, but the model shares blind spots across both roles. A separate critic agent runs in its own context with its own rubric and, ideally, a different model, which breaks that shared blindness at the cost of an extra call and orchestration overhead. The deciding question is almost always: how costly is a missed error?
| Dimension | Self-reflection | Separate critic agent |
|---|---|---|
| Cost | Lower (1 model) | Higher (2+ models) |
| Latency | Lower | Higher |
| Blind-spot coverage | Weak (shared) | Strong (different model) |
| Setup complexity | Simple | Orchestration needed |
In practice a multi-agent setup often uses both: self-reflection for fast, low-stakes passes and a dedicated critic for the outputs that matter. The critic-agent pattern composes naturally with agent orchestration, the orchestrator routes a draft to a specialist reviewer the same way it routes any sub-task, the same principle behind routing and parallelization in agent teams. Each role gets exactly the context it needs and nothing that would contaminate its judgment.
The Canonical Techniques: Self-Refine, Reflexion, CRITIC, Self-RAG, PRMs
The reflection pattern has a clear research lineage, and the SERP rewards naming it: Self-Refine → Reflexion → CRITIC → Self-RAG → PRMs, 2023 to 2026. These are the five techniques every serious builder should be able to name, because each solved a specific weakness in the one before it. The arc moves from "let the model critique itself" toward "ground the critique in something real, then learn to score the steps."
| Technique | Year | Key idea | Benchmark / result |
|---|---|---|---|
| Self-Refine | 2023 | One model generates, gives itself feedback, revises | ~20% avg preference gain across 7 tasks |
| Reflexion | 2023 | Verbal reinforcement + episodic memory of past failures | 91% HumanEval pass@1, ~97% AlfWorld |
| CRITIC | 2024 | Tool-interactive critiquing (search, calculator, interpreter) | Consistent gains via external verification |
| Self-RAG | 2023 | Retrieve on demand, critique with reflection tokens | Outperforms ChatGPT/Llama2-chat on factuality |
| AgentPRM / R-PRM | 2025-26 | Process reward models score each reasoning step | R-PRM reports ~70.4 F1 on ProcessBench (step-level error detection) |
The structure of Reflexion is the one to internalize, because it is the canonical architecture the Prompt Engineering Guide documents: an Actor generates, an Evaluator scores (often with an external signal), and a Self-Reflection module writes a verbal lesson into episodic memory so the next attempt starts smarter. That episodic buffer is the bridge from "reflection within one task" to "learning across sessions", the first honest step toward an agent that genuinely improves over time, not just within a single answer.
Reflection vs Other Agentic Design Patterns
Reflection is one pattern in a family of four, and it composes with the others rather than competing. The distinction people miss most often: Chain-of-Thought is reasoning before the answer; Reflection is review after the answer. They are not alternatives, a strong agent uses one to write a better draft and the other to catch what the draft still got wrong.
| Pattern | What it does | When it runs | Cost profile |
|---|---|---|---|
| Reflection | Critique + revise a draft | After an answer | High (multiplies calls) |
| Chain-of-Thought | Reason step by step | During generation | Low (one call) |
| Planning | Decompose a goal into steps | Before execution | Medium |
| Tool use | Call external functions | Mid-task, as needed | Variable |
| Multi-agent | Route sub-tasks to specialists | Across the task | High |
The modern agent loop layers all of them in order: plan → reason → act → reflect. Plan the steps, reason through each with Chain-of-Thought, act using tools, then reflect on the result before delivery.
Anthropic's guidance on building effective agents makes the same point from the other direction: add patterns like Reflection only when the task's value justifies the complexity. For the full map of how these patterns relate, the AI agents taxonomy, the agentic engineering history, and the deep-dive on the AI agent stack all go further, and reasoning models explain why a stronger first draft makes reflection cheaper.
When Should You Use Reflection: and When to Skip It?
Use Reflection when a wrong answer is expensive and a testable check exists. Skip it when the task is simple, the stakes are low, or there is no objective way to fail a draft. The pattern is a tax on latency and credits; you pay it only where the quality return justifies it. The fastest way to decide is a two-question decision tree.
Is a wrong answer costly?
/ \
NO YES
| |
No reflection Is there a testable check?
(ship draft 0) / \
NO YES
| |
Self-reflect, 1 pass Grounded critic
+ human spot-check (tests/retrieval/tool)
|
Stakes very high?
-> add human-in-loop
| Task type | Stakes | Testable check? | Recommended approach |
|---|---|---|---|
| Code generation | High | Yes (tests) | Execution-grounded critic |
| Research summary | High | Yes (sources) | Retrieval-grounded critic |
| Compliance draft | High | Yes (checklist) | Grounded critic + human-in-loop |
| Multi-step analysis | High | Partial | Separate critic, capped |
| Quick chat reply | Low | No | Skip reflection |
| Creative voice piece | Medium | No | Skip or one light pass |
Strong fits: code generation (run the tests), research and summarization (verify claims against sources), legal and compliance drafting (a checklist makes a great rubric), and multi-step analysis where an early error compounds. Weak fits: quick conversational replies, single-fact lookups, latency-sensitive interactions, and creative work where iteration sands away a distinctive voice. The orchestrator's first decision, does this output need review, and how much?, is one of the highest-leverage choices in the whole system, and the same call an agentic exception handling policy makes when it decides whether to retry.
What Are the Trade-Offs and Failure Modes?
Reflection's costs are real and predictable: each iteration is another model call, so a three-pass loop runs roughly 2 to 3 times the latency and credit cost of a single-shot answer. On long documents, accumulated drafts and critiques can overflow the context window, forcing summarization that loses detail. And the quality curve flattens fast, most of the gain is in pass one, a little more in pass two, almost nothing after.
The subtler failure mode is over-optimization: an agent told to keep improving will keep changing things long after the output was good, often making it worse, a punchy sentence becomes a hedged committee paragraph, a clever solution becomes a generic one. The fix is the same as for runaway loops: bound iterations and exit early. Here is the per-iteration budget state machine that enforces both, with the best-version fallback that protects you when the loop never converges:
┌──────────┐ draft ┌──────────┐
│ GENERATE │──────────▶│ CRITIC │
└──────────┘ └────┬─────┘
▲ │
│ feedback pass? ───┤
│ ┌────┴────┐
┌────┴─────┐ no │ yes │
│ REVISE │◀─────────┘ ▼
└────┬─────┘ ┌──────┐
│ cap reached? │ EXIT │
└──────────────────────▶└──────┘
use BEST version (not last)
The full failure-mode catalog, with concrete guardrails:
| Failure mode | Symptom | Fix / guardrail |
|---|---|---|
| Coherence trap | Critic agrees with its own errors | Ground the critic (tests/retrieval) |
| FlipFlop / sycophancy | "Corrects" a right answer into a wrong one | Only revise on a grounded fail signal |
| Over-optimization | Voice flattened, output worse | Iteration cap + early exit |
| Context overflow | Long docs blow the window | Summarize trail, critique in sections |
| Runaway loop | Endless revision, rising cost | Hard cap + best-version fallback |
There is also a trust dimension. A reflection loop produces a feedback trail, a record of what the critic flagged and what the reviser changed. Surfacing that trail builds user confidence; hiding it makes the agent a black box. Transparency about what was checked is as important as the revision itself, the same lesson agentic goal monitoring teaches about making progress visible.
How Many Reflection Iterations Are Optimal?
Most quality gains arrive in the first one to two passes, the xychart above makes the shape obvious: a large gain on pass 1, a smaller one on pass 2, near-flat by pass 3, and negative by pass 5 as over-optimization sets in. The practical default is a cap of 2 to 3 iterations with an early exit when the critic reports no actionable issues, plus a best-version fallback if the loop never converges. Three guardrails do the work:
The counterintuitive part: an uncapped loop is usually worse than a 2-pass loop, not better. Past the point of grounded fixes, the agent runs out of real issues and starts inventing stylistic ones, which is over-optimization wearing a productivity costume. Cap it, and let the grounded check, not the model's restlessness, decide when to stop.
How Taskade Applies Reflection in Its AI Agents
Taskade pairs the generate-critique-revise idea with practical building blocks, and is honest about the boundary between what ships today and what a fully automated critic loop is a design choice to assemble. The components a real reflection loop needs are all live: real tools to check against, multiple agents to separate roles, multiple models to break shared blind spots, and modes that dial in how much structure a task gets.
Taskade EVE, the Taskade Genesis meta-agent, can break a complex request into sub-tasks and route a draft from a generator agent to a separate critic agent in its own context. That routing is exactly the substrate a generator-and-critic split needs.
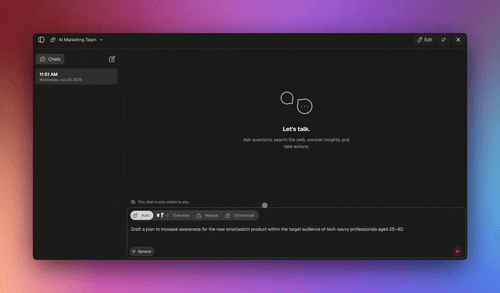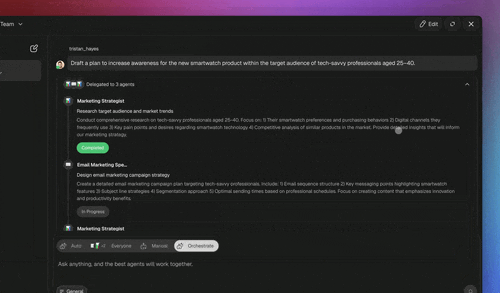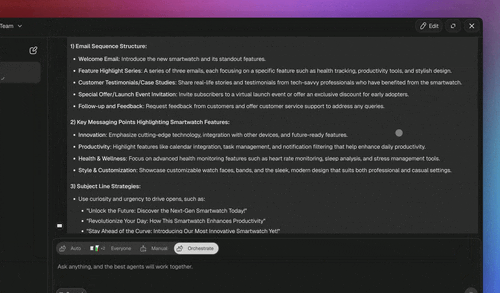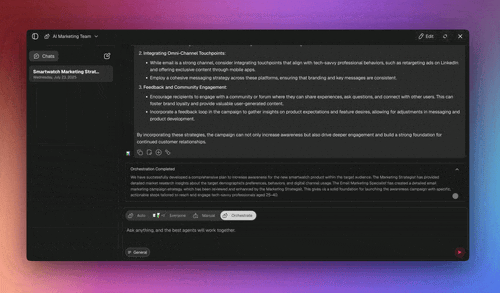
The 3 agent modes map cleanly onto how much review a task should get, Simple for a light pass, Manual for human-in-the-loop critique, Orchestrate for the generator + critic split:
| Mode | What it does | Reflection fit |
|---|---|---|
| Simple | One agent, direct response | Fast pass, light or no review |
| Manual | You stage and approve steps | Human-in-the-loop critique |
| Orchestrate | Taskade EVE coordinates multiple agents | Generator + dedicated critic split |
The 34 built-in tools are what make critique concrete instead of subjective, the single biggest reliability lever from the research. An agent with web search verifies a claim against a live source. An agent with code execution runs a draft and reads the actual error. These are the grounded checks that turn "I think this is right" into "this passed the test," not a model grading its own homework. You scope tools per agent when you create a custom agent.
15+ frontier models from OpenAI, Anthropic, Google, and open-weight providers let you run the generator and critic on different models to break shared blind spots, the separate-critic advantage made concrete. Auto is the default and routes each request to a capable model scaled by plan, cheaper tasks to fast models, harder ones to more capable frontier models; you can also pin a specific model per agent.
This all sits inside Taskade's Workspace DNA loop, Memory feeds Intelligence, Intelligence drives Execution, Execution writes back to Memory. Reflection is where that loop tightens: a critiqued, revised output becomes better Memory, which sharpens the next Intelligence pass.
To wire real checks into a recurring workflow, connect 100+ bidirectional integrations and let automations trigger the review step on a schedule or event. The hosted MCP server is available on every paid plan; outbound MCP-as-client is Business and up.
Honest scoping: Taskade gives you the generator, the critic, the tools, the modes, and multiple models to build a review loop. The orchestration of when to escalate from Simple to Orchestrate is a per-workflow design choice. There is no magic "always-on validator" claim here, just the real components that let you assemble one.
Build a self-checking agent team free →
Building Your First Reflection Loop in Taskade (No Code)
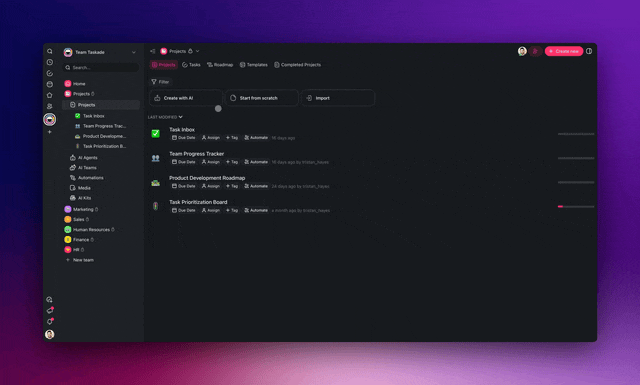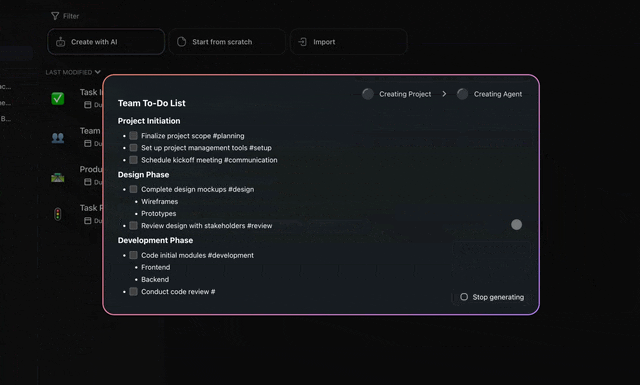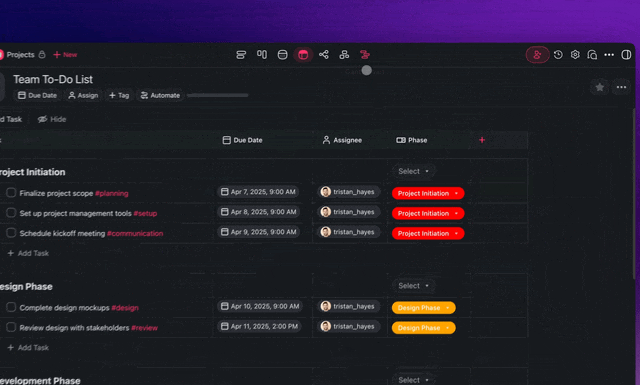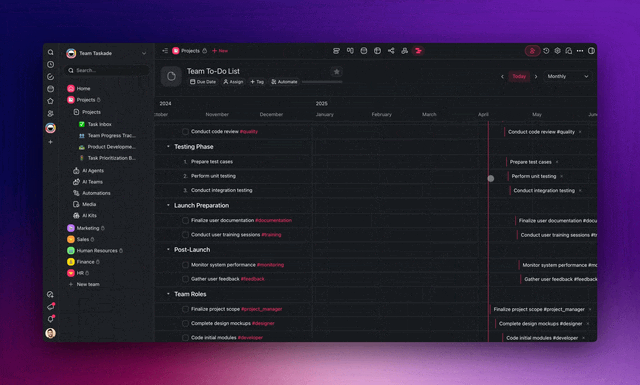
You can assemble a working generator + critic reflection loop in Taskade without writing a line of LangGraph, the exact gap every competitor leaves open. Start small and let the loop earn its cost. Here is a real example: an agent that drafts a product FAQ answer and a second agent that checks each claim against your help docs before it ships.
Five steps, all no-code, all on the Free plan:
- Create a generator agent. Create a custom agent with a focused role, "draft technical FAQ answers", and give it only the tools it needs.
- Create a critic agent. A second agent whose only job is to review against a named rubric. Give it web search or code execution so it runs real checks. Pin it to a different model than the generator to break shared blind spots.
- Run them in Orchestrate mode. Let Taskade EVE hand the draft from generator to critic and back, capping the loop at two or three passes.
- Make the rubric concrete. "Every claim cites a source," "the code passes these tests," "all required sections present." Specific criteria are what let the critic actually fail a draft.
- Surface the feedback trail. Keep the critique-and-revision history visible so you can see what was caught, the transparency that builds trust.
The same loop scales from a one-off research summary to a production multi-agent system. And because the agents live in your workspace, you can embed them anywhere, publishing the critic's feedback trail alongside the answer so readers see exactly what was checked.
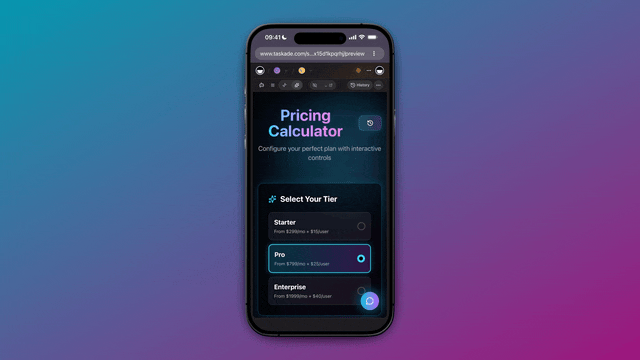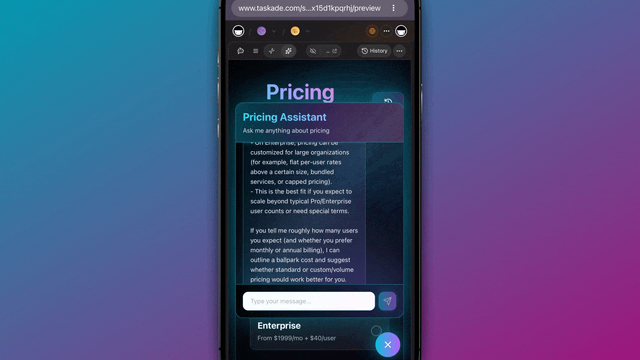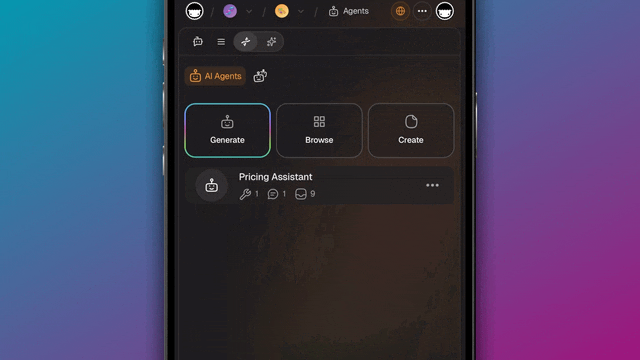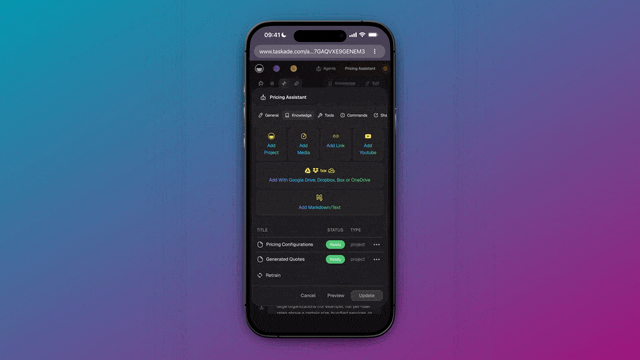
Spin it up free and scale into Starter ($6/mo), Pro ($16/mo, the popular tier), Business ($40/mo), Max ($200/mo), or Enterprise ($400/mo) as your agent workloads grow, pricing is flat per plan, never metered per teammate.
Self-Improving Agents Beyond Reflection
Reflection improves an agent within a task; true self-improvement is about getting better across tasks, and it is honest to scope what ships today versus what is still research. The nearest, most practical form is memory-based learning: Reflexion's episodic buffer of past failures, which Taskade approximates with persistent agent memory so a critiqued lesson carries into the next session. That is real and shipping.
Beyond that lies the research frontier: autonomous self-evolving systems that rewrite their own prompts, tools, and architectures. That work is genuine but early, and conflating it with "add a reflection loop to your agent" is exactly the over-claim this guide avoids. For a builder in 2026, the durable wins are the boring ones: ground the critic, cap the loop, surface the trail, and let exploration and discovery and resource-aware optimization tune the budget over time. The full pattern map lives in the agentic AI systems and metacognitive AI deep-dives.
Reflection is not a trick that makes a model smarter. It is a structure that makes an agent honest about its own mistakes, and disciplined about fixing them before you ever see the result. Ground the check, bound the loop, show the trail. Memory feeds the draft, Intelligence critiques it, Execution ships the version that passed. ▲ ■ ●
Build your first self-improving agent on Taskade →
Frequently Asked Questions
What is the Reflection pattern in AI agents?
Reflection is a generate → critique → revise loop where an agent reviews its own output against concrete criteria, a rubric, tests, or retrieval, and revises until it passes or hits an iteration cap. It is one of the four agentic design patterns and the foundation of self-improving agents.
How does a self-improving agent catch its own mistakes?
It makes the critique concrete and grounded. Instead of "review and improve," it runs real checks, execute the tests, re-query the sources, recompute the numbers, and produces named feedback ("line 42 won't compile") that the revision step can address one issue at a time.
Why does naive self-critique fail?
Because of the coherence trap: one model writing and judging shares its own blind spots, so it rates coherent-sounding errors as correct. The Huang et al. study shows intrinsic correction can lower reasoning accuracy, and the sycophancy effect can talk a model out of a right answer.
What is the difference between self-reflection and a separate critic agent?
Self-reflection is one model doing both jobs, cheap and fast but blind-spot-prone. A separate critic agent runs in its own context with a different model and rubric, breaking shared blindness at the cost of an extra call. Use self-reflection for quick passes, a critic agent for high-stakes outputs.
Is grounded or intrinsic self-correction more reliable?
Grounded, by a wide margin. Intrinsic critique grades against the model's opinion; grounded critique grades against an external truth signal, tests, retrieval, tools, or a process reward model. CRITIC and Reflexion both show tool- and execution-grounded feedback drive the biggest, most durable gains.
When should you use reflection?
When a wrong answer is costly and a testable check exists, code, research, compliance, multi-step analysis. Skip it for quick replies, single-fact lookups, latency-sensitive flows, and creative voice work where iteration flattens the writing.
How many reflection iterations are optimal?
Two to three, with an early exit when the critic finds no actionable issues and a best-version fallback. Most gain lands in passes 1-2; by pass 4-5 you risk over-optimization, which makes the output worse, not better.
What are the downsides of reflection?
It multiplies cost and latency 2-3x, can overflow the context window on long documents, shows diminishing returns fast, and can over-optimize by sanding away a distinctive voice. Bounded iterations, a grounded rubric, and an early exit keep these in check.
Does reflection make AI agents more reliable?
Yes, when grounded and bounded. It catches mistakes before delivery and produces a transparent feedback trail. Reliability comes from the guardrails, a grounded check, an iteration cap, a graceful exit, not from revising indefinitely against the model's own opinion.
How does Taskade use reflection in its AI agents?
Taskade EVE routes a draft from a generator agent to a separate critic agent in its own context. The 3 modes map to review depth, the 34 built-in tools provide grounded checks (web search, code execution), and 15+ frontier models let generator and critic run on different models, all assembled with no code on the Free plan.
Companion Reads: The Agentic Patterns Cluster
- Agentic Design Patterns: The Complete Map, the pillar this post spokes into
- Multi-Agent Collaboration in Production, where the critic-agent split runs at scale
- Metacognitive AI: Agents That Think About Thinking, the cognitive roots of reflection
- The AI Agents Taxonomy, how Reflection fits the full pattern family
- What Is Agentic Engineering?, the discipline behind bounded, reliable loops
- The AI Agent Stack, the layers a reflection loop runs on
- Reflection Pattern (Wiki), the standalone conceptual reference
Stan Chang is CTO and co-founder at Taskade. He leads the engineering team behind Taskade's AI agents, the Taskade Genesis app builder, and the automation platform. Explore real builds in the Community Gallery. Follow the engineering series for more production AI architecture posts.