






In 1979, a Stanford psychologist named John H. Flavell published a 6-page paper that quietly reshaped how the human race thinks about thinking. The paper coined a word: metacognition — cognition about cognition. Awareness of your own mind. Knowing what you know, what you don't, and what to do about the gap.
Forty-four years later, in 2023, a team at Northeastern published Reflexion — a framework where AI agents write verbal self-reflections after every failure, store them in episodic memory, and retry with the reflection in context. On HumanEval, the metacognitive agents hit 91% pass-rate, near the human ceiling.
Different fields. Different decades. Same idea: a system that models its own thinking outperforms a system that just thinks.
This is the story of how 50 years of cognitive science quietly became the design pattern for the next generation of AI agents — and why Taskade Genesis is built around it from the ground up.
TL;DR: Metacognition — thinking about thinking — traveled from a 1979 Flavell paper to today's design pattern for AI agents that monitor uncertainty, replan when stuck, and store reflections as memory. Reflexion hit 91% on HumanEval (near the human ceiling) by writing self-reflections after every failure. Taskade Genesis ships the same loop as Memory + Intelligence + Execution. Try Genesis free →
🧠 What Is Metacognition? The Answer the Snippet Is Looking For
Metacognition is thinking about thinking — the awareness and regulation of your own mental processes. Coined by psychologist John Flavell in 1979, it has two parts: metacognitive knowledge (what you know about how you think) and metacognitive regulation (planning, monitoring, and evaluating tasks). Strong metacognition predicts better learning, decision-making, and self-correction in both humans and AI systems.
A simpler way to feel it:
Cognition: "The capital of France is Paris."
Metacognition: "Wait — am I sure about that, or guessing?
Let me check. Yes, I'm confident. Move on."
The first sentence is the answer. The second is the model of the answer — confidence, source, decision to act. That second sentence is metacognition.
Most humans do this thousands of times a day without naming it. Most AI systems, until very recently, did not do it at all.
🗺️ The 50-Year Arc — A Map
The arc from Flavell's 1979 metacognition paper to today's self-reflective AI agents spans five decades and four distinct fields. Cognitive psychology defined the term, control theory formalized the architecture, neuroscience built the measurement, clinical psychology turned it into a therapy, and AI research finally implemented it in code. The single-page map below traces that lineage from 1979 to Taskade Genesis in 2026.
What follows is that timeline, expanded into detail you can use.
📜 Part I — The Cog-Sci Genesis (1979–2010)
The cognitive-science foundation of metacognition was built across three decades and four sub-fields. John Flavell named it in 1979, Nelson and Narens formalized its two-level architecture in 1990, Hampton's macaques showed it was not uniquely human in 2001, Wells turned it into a clinical therapy in 2009, and Fleming et al. measured it in the brain in 2010. Each step is below.
🟢 Flavell, 1979 — The Founding Paper
"Metacognition refers to one's knowledge concerning one's own cognitive processes and products… the active monitoring and consequent regulation and orchestration of these processes."
— John H. Flavell, American Psychologist, 1979
Flavell's paper was a developmental psychologist's frustration in print. He had spent the 1960s and 70s noticing that 3-year-olds confidently claim they can remember 10 items and then recall 3 or 4 (Flavell, Friedrichs & Hoyt, 1970). The kids did not know what they did not know.
His four-component model:
| Component | What it is | Modern AI parallel |
|---|---|---|
| Metacognitive knowledge | Beliefs about persons, tasks, strategies | System prompt + agent profile |
| Metacognitive experiences | The conscious "this is hard" feel | Confidence scores, calibration signals |
| Goals | What you're trying to do | Planner output, OKRs, todo |
| Actions / Strategies | What you do to reach goals | Tool calls, retries, replans |
Flavell's warning, often forgotten: more metacognition is not automatically better. Rumination is metacognition gone wrong. Hold that thought — it returns when we look at agentic loop failures.
🟢 Nelson & Narens, 1990 — The Architecture Diagram
If Flavell named the thing, Thomas Nelson and Louis Narens drew it. Their 1990 chapter in The Psychology of Learning and Motivation gave the field a control-systems formalism that is still the most-reproduced figure 35 years later:
Two flows. Monitoring sends information up from object to meta — "how is the task going?" Control sends commands down from meta to object — "keep going / stop / try a different strategy."
A counterintuitive Nelson finding worth saving: delayed judgments of learning are dramatically more accurate than immediate ones. Wait a few minutes after studying before predicting recall, and your calibration jumps. The same trick works for LLM judges. Free intervention.
🟢 Adrian Wells, 1996–2009 — Metacognition Goes Clinical
By the mid-90s, the educational and developmental wings of metacognition research were thriving. The clinical wing arrived later — and harder. Adrian Wells' Self-Regulatory Executive Function (S-REF) model (Wells & Matthews, 1996) made the move that changed therapy:
Mental illness is not maintained by the content of negative thoughts. It is maintained by the process — perseverative worry, rumination, threat-monitoring — driven by metacognitive beliefs.
The Cognitive Attentional Syndrome (CAS) is Wells' name for that process: a sufferer who believes "worrying keeps me safe" cannot stop worrying, because stopping feels dangerous. CBT modifies the content of thoughts. Metacognitive Therapy (MCT) modifies the relationship to thinking itself.
The CAS Loop
┌───────────────────────────────┐
│ │
▼ │
┌─────────────────────────┐ │
│ Trigger thought │ │
│ ("what if X goes │ │
│ wrong?") │ │
└────────────┬────────────┘ │
│ │
▼ │
┌─────────────────────────┐ │
│ Metacog belief fires │ │
│ ("I must keep │ │
│ monitoring this") │ │
└────────────┬────────────┘ │
│ │
▼ │
┌─────────────────────────┐ │
│ Worry / rumination / │ │
│ threat-monitoring │ │
└────────────┬────────────┘ │
│ More disturbing thoughts │
└───────────────────────────────┘
If that diagram looks like an LLM agent stuck in a tool-call loop, it is exactly the same shape. We will return to this.
🟢 Stephen Fleming, 2010s — Metacognition Becomes a Number
Until 2010, "good" metacognition meant whatever your particular self-report scale said it meant. Stephen Fleming's UCL lab changed that with Fleming et al., 2010, Science and the meta-d′ framework (Maniscalco & Lau, 2012).
META-d' EXPLAINED — IN ONE BLOCK Type-1 d' How well your decisions track the truth
(first-order task accuracy)
Type-2 d' How well your CONFIDENCE tracks
(meta-d') your accuracy
M-ratio meta-d' / d' — the fraction of
available evidence you actually use
to inform confidence
Three findings that ought to humble every LLM benchmark practitioner:
- Metacognitive sensitivity is only weakly correlated with IQ or task performance. You can be a great performer with terrible self-knowledge, or vice versa. (Fleming et al., 2014.)
- Right anterior prefrontal cortex (BA 10) grey-matter volume correlates with metacognitive accuracy independent of objective performance. Lesion patients lose self-knowledge while keeping perception intact.
- Meditation training improves meta-d′ on perceptual tasks (Baird et al., 2014, Psychological Science). Metacognition is trainable.
That last one matters. If metacognition is trainable in humans, it should be trainable in LLMs. The 2023–2026 wave of agent reflection research is, in effect, the empirical test of that hypothesis.
🟢 Animal Metacognition — Even Macaques Know What They Don't Know
Hampton's 2001 PNAS paper showed rhesus macaques opt out of memory tests on trials they would have failed, even when the experimenter cannot predict difficulty. Dolphins do it. Some great apes do it. Pigeons fail it. The skeptical reading (Carruthers, 2008) is associative learning. The strong reading is genuine self-monitoring. The argument is unsettled — but the practical takeaway is settled: metacognition is not uniquely human. It does not require language. It does not require consciousness in any heavy sense. It is, mechanistically, a model of the agent's own performance.
That is exactly the kind of thing an LLM can have.
🤖 Part II — Metacognition Meets the Machine (2022–2026)
LLM metacognition crystallized across four 2022–2024 papers. Kadavath (Anthropic, 2022) showed larger models track their own correctness in their logits. Reflexion, Self-Refine, and Tree of Thoughts (2023) turned that signal into generate-critique-revise loops. Farquhar et al. (Nature, 2024) introduced semantic entropy for hallucination detection. OpenAI's o1 (2024) then productized test-time deliberation. Each maps directly onto a Nelson-Narens primitive.
🟢 Kadavath, 2022 — "Language Models (Mostly) Know What They Know"
The opening shot of the LLM-metacognition era was Kadavath et al. (Anthropic) in July 2022. They asked: when an LLM produces an answer, does its own internal probability track whether the answer is correct?
It does, increasingly well, with scale. A larger model knows when it's right and when it's bluffing — if you ask it the right way.
This is the LLM equivalent of human feeling-of-knowing. The string-attached-to-deep-memory the Meta-Think lectures describe ("you know this, you know this") has a measurable analogue in the model's logits. From the moment Kadavath's paper landed, the obvious next move was to use that signal to make the model think harder when it was uncertain — and not waste compute when it was confident.
That is what the next two years of research delivered.
🟢 The Reflection Revolution — 2023's Big Three
In 2023, three papers redefined what an LLM agent could be:
| Paper | Authors | Move | Headline result |
|---|---|---|---|
| Self-Refine (arxiv 2303.17651) | Madaan et al. | One model: generate → critique → revise | ~20% gain across 7 tasks, no external supervision |
| Reflexion (arxiv 2303.11366) | Shinn, Cassano et al. | Verbal self-reflection stored in episodic memory after failures | 91% on HumanEval coding |
| Tree of Thoughts (arxiv 2305.10601) | Yao et al. | Search tree over reasoning paths with self-evaluation at each node | 74% on Game of 24 (vs. 4% chain-of-thought) |
Look at those moves through the Nelson-Narens lens:
Every pink node is a meta-level operation. Self-Refine is monitoring + control inside a single call. Reflexion is monitoring + control + persistent memory — the closest computational analogue to a human after-action review. Tree of Thoughts is monitoring with branching control — search where the heuristic is the model's own self-evaluation.
This is the moment the cog-sci diagrams stop being analogies and start being architectures.
🟢 The Skeptical Counter — Huang et al., 2023
Important footnote. Huang et al. (DeepMind, 2023) — "Large Language Models Cannot Self-Correct Reasoning Yet" — showed that without ground-truth feedback, intrinsic self-correction often degrades performance. Models second-guess correct answers into wrong ones.
The lesson is the same one Wells warned about for humans: more metacognition is not automatically better. Rumination is metacognition gone wrong. A naive "always self-critique" prompt is the LLM version of CAS — perseverative re-evaluation that drifts away from the truth. Production reflection systems need a reason to reflect (a failure signal, a low-confidence flag, a verifier disagreement) — not a default to do it on every turn.
This is one reason Taskade's agentic loop protection detects repeated tool calls and similar outputs and either injects corrective instructions or gracefully exits. It is, structurally, an MCT intervention for agents.
🟢 Semantic Entropy — Calibration Done Right (Farquhar, Nature 2024)
Token entropy is a bad metric. "Paris" and "the city of Paris" are the same answer dressed differently — high token entropy, zero semantic disagreement.
Kuhn, Gal & Farquhar (ICLR 2023) introduced semantic entropy: cluster generated answers by meaning first, then measure entropy across the clusters. Farquhar et al. (Nature 2024) brought it to the Nature cover with a definitive empirical demonstration: high semantic entropy reliably flags hallucinations, low semantic entropy reliably flags grounded answers.
This is the LLM analogue of the tip-of-the-tongue feeling-of-knowing — the system has a reliable signal that it does not know, separate from the answer itself. The Jeopardy buzzer, ported to silicon. Production hallucination detection (SelfCheckGPT, LM-Polygraph, UQ-NLG) is built on top of this idea.
🟢 Test-Time Compute — o1, R1, and the End of "One-Shot Answers"
In September 2024, OpenAI released o1. In January 2025, DeepSeek-R1 open-sourced the recipe. The headline was the same: an RL-trained internal chain of thought, where the model learns when to keep deliberating. This is metacognitive control at the compute level.
Snell et al. (DeepMind, 2024) made the empirical case: with smart test-time deliberation, a small model can match a 14× larger one on hard tasks. Think longer, not bigger.
This maps cleanly onto a paradox the cog-sci field already knew about: flow. Csikszentmihalyi's flow state and Dietrich's "transient hypofrontality" hypothesis (Dietrich, 2003) describe peak performance as reduced metacognitive monitoring — the executive layer steps out of the way during execution, after doing all its work in preparation. Coaches who say "stop thinking and play" are giving sound metacognitive advice.
The frontier-model insight is the same: deliberate hard on the hard problems, run single-pass on the easy ones. Bimodal use of metacognition. Production systems like Taskade's thinking modes (Standard / Thinking / Reasoning / Auto) surface this directly as a UI choice — let the user, or the agent, decide when to think harder.
🟢 Metacognitive Prompting — Wells Meets Wang & Zhao (2024)
Of all the 2023–2024 papers, the one that wears its cog-sci heritage on its sleeve is Wang & Zhao, 2024 — "Metacognitive Prompting Improves Understanding in LLMs". Their five-stage scaffold is literally Flavell's framework, ported:
1. Clarify the question
2. Form a preliminary judgment
3. Critically evaluate it
4. Make the final decision
5. Rate confidence
If you have ever sat through Adrian Wells' Attention Training Technique or Detached Mindfulness scripts — phase 1 select, phase 2 switch, phase 3 divide — the similarity is uncanny. Wells trained patients out of CAS by training metacognitive flexibility. Wang & Zhao trained LLMs into better calibration with the same shape.
🟢 The 2026 Frontier — Intrinsic Metacognitive Learning
The 2026 position paper Truly Self-Improving Agents Require Intrinsic Metacognitive Learning sets the next horizon: agents that learn to calibrate their own confidence over time, not just agents that reflect once and forget. The April 2025 Meta-Thinking via Multi-Agent RL survey tracks the same trajectory in the multi-agent setting.
This is where the field is going. And — speaking from where Taskade sits — this is exactly what a workspace gives you for free.
🧬 Part III — Workspace DNA Is the Architecture
For the last decade, agent designers have been wrestling with one structural problem: where does the metacognition live?
A single LLM call is amnesic. A reflection without a memory to write it into evaporates the moment the context window closes. A monitoring signal with nothing to monitor (no goal, no plan, no execution surface) is just an opinion.
This is the deepest structural insight of Workspace DNA:
Compare to Nelson & Narens (1990):
| Nelson & Narens | Workspace DNA | What it does |
|---|---|---|
| Object level | Execution (Automations) | Acts on the world |
| Meta level | Intelligence (Agents + EVE) | Models the action |
| Monitoring | Read from Memory + observe Execution | State flows up |
| Control | Plan → trigger Execution | Commands flow down |
| (missing in NN) | Memory (Projects) | Persistent substrate |
Nelson & Narens' diagram is missing one box: persistent memory. Their 1990 model was about a single task, in a single head, in a single sitting. They didn't need it. An agent does.
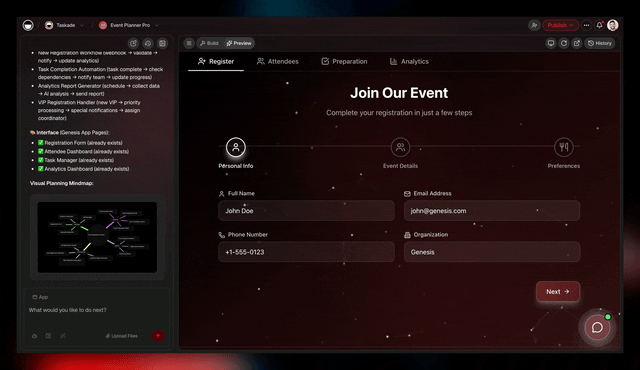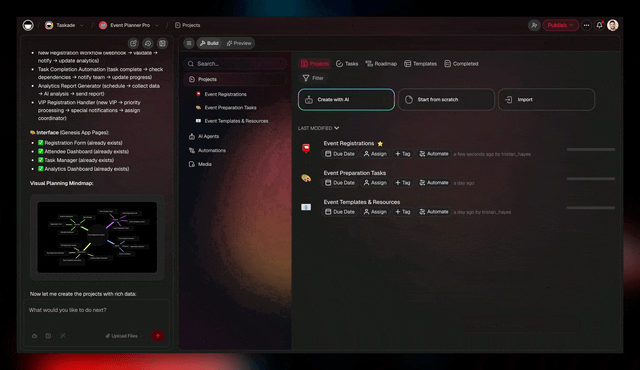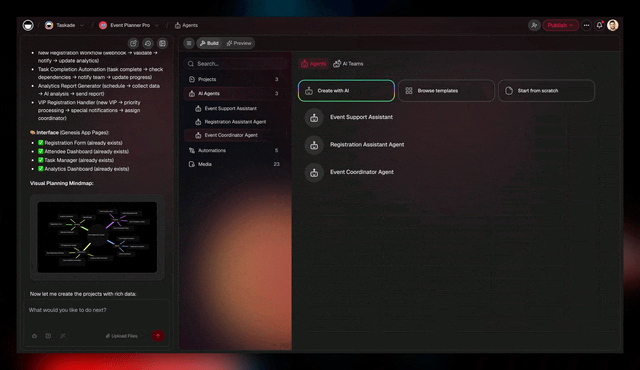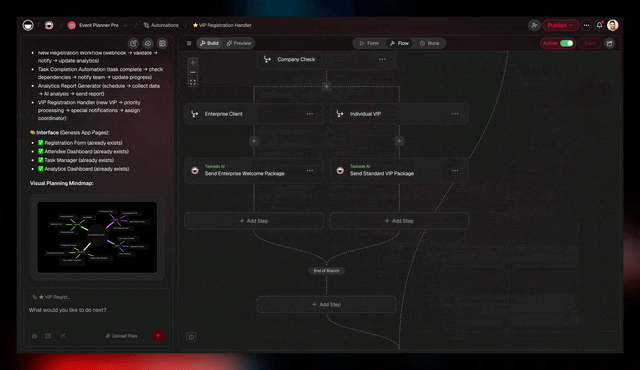
Every loop in modern agent research — Reflexion's episodic memory, Tree of Thoughts' search state, o1's deliberation traces — is reaching for the same missing box. A workspace gives it to you natively. Projects are the memory. Agents are the intelligence. Automations are the execution. The loop closes by default.
EVE Eats Her Own Dogfood
EVE — the Genesis meta-agent, public name Entity of Vision & Execution — does the cleanest possible demonstration of this. EVE's own metacognitive state — her plans, her reflections, her "what I learned this run" — is stored as Taskade Projects in a projects/memories folder.
This is not a metaphor. It is the same mechanism users get. Every reflection EVE writes is queryable, editable, and visible — the way a human's after-action review would be if they kept a decision journal. The platform eats its own dogfood at the metacognitive layer.

The /memory Knowledge Graph
In v6.153, Taskade shipped the /memory workspace DNA knowledge graph — a workspace-scoped graph surface visualizing how Memory, Intelligence, and Execution interconnect. The team graph that ships next door (the team-knowledge-graph newsletter feature in April 2026) does the same trick at the team level.
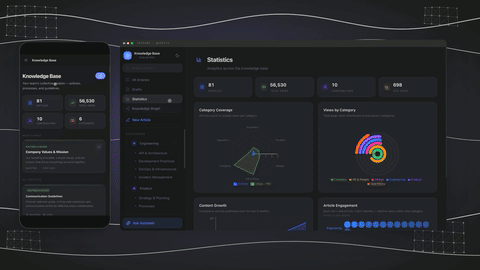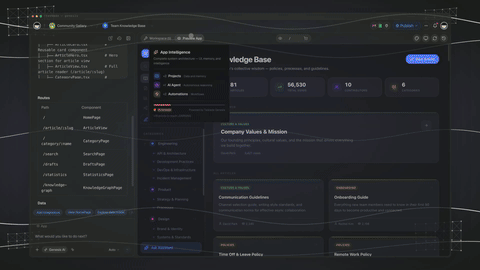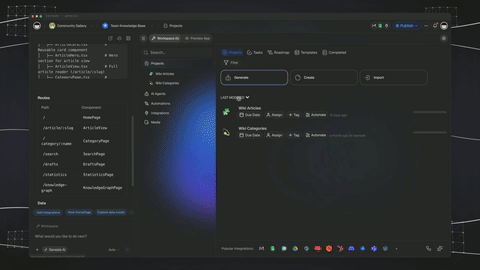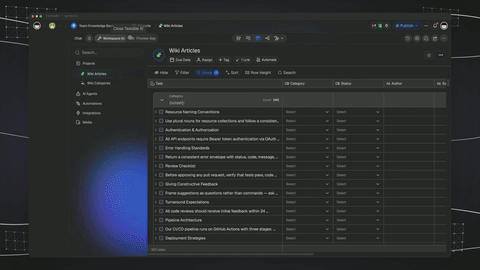
This is what Fleming et al.'s 2010 Science finding looks like productized. Right anterior PFC builds a model of the rest of cognition. The knowledge graph builds a model of the rest of the workspace. Same shape. Different substrate.
🎛️ Part IV — Three Loops, Mapped
Every metacognitive agent runs three loops in parallel: monitoring (does it know what it knows?), control (when to think harder, retry, or stop?), and evaluation (what gets remembered for next time?). Nelson-Narens (1990) named them, the 2022–2024 LLM research operationalized them, and Taskade Genesis ships all three pre-wired. The table below maps academic vocabulary to agent-engineering vocabulary, one loop per row.
┌─────────────────────────────────────────────────────────────────────┐
│ COG-SCI │ LLM RESEARCH │ TASKADE GENESIS │
├──────────────────────┼────────────────────────┼──────────────────────┤
│ Monitoring │ Confidence / │ Agent confidence │
│ (Nelson-Narens) │ semantic entropy / │ signals, evaluator │
│ │ P(true) calibration │ agents, loop │
│ │ (Kadavath, Farquhar) │ protection │
├──────────────────────┼────────────────────────┼──────────────────────┤
│ Control │ Replan / retry / │ Replanner step, │
│ (allocate effort, │ test-time compute │ Auto thinking mode, │
│ opt out, retry) │ (o1, R1, Snell) │ branching workflows │
├──────────────────────┼────────────────────────┼──────────────────────┤
│ Evaluation │ Verbal reflection / │ Project history, │
│ (after-action │ episodic memory │ Learning Memory, │
│ review) │ (Reflexion, Self- │ decision journal │
│ │ Refine) │ in the workspace │
└─────────────────────────────────────────────────────────────────────┘
Loop 1: Monitoring — Does the Agent Know What It Knows?
In humans: feeling-of-knowing. Tip-of-the-tongue. Confidence calibration.
In LLMs: token-level P(True), verbalized confidence ("90% sure"), semantic entropy.
In Taskade: agent confidence + evaluator agents + agentic loop protection.
A multi-agent Genesis run can include an evaluator agent whose only job is to read the executor agent's output and rate it against a rubric. That rating becomes the monitoring signal — the same signal a human's PFC produces about its own perceptions. When the rating drops below threshold, the system replans. When the same low rating repeats, agentic loop protection intervenes.
Loop 2: Control — When the Agent Decides to Think Harder
In humans: the decision to allocate study time, to opt out, to ask for a hint.
In LLMs: chain-of-thought, tree-of-thoughts, test-time compute scaling, o1-style RL on reasoning.
In Taskade: Thinking Modes — Standard, Thinking, Reasoning, Auto. Auto routes per task complexity. Reasoning unlocks deeper test-time compute on hard problems.
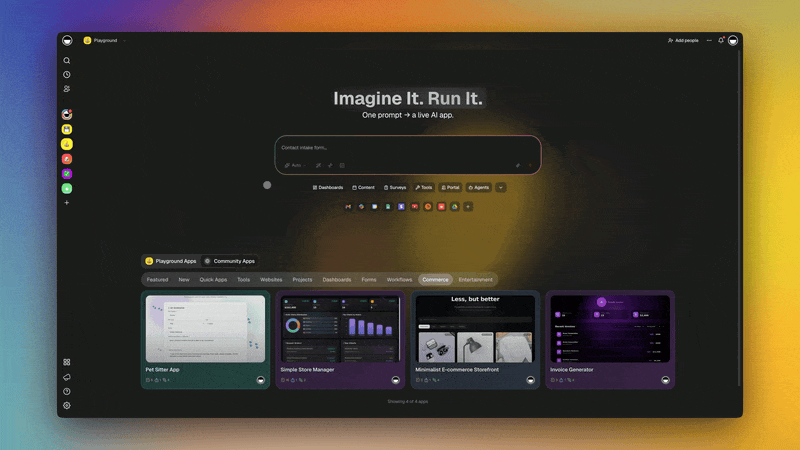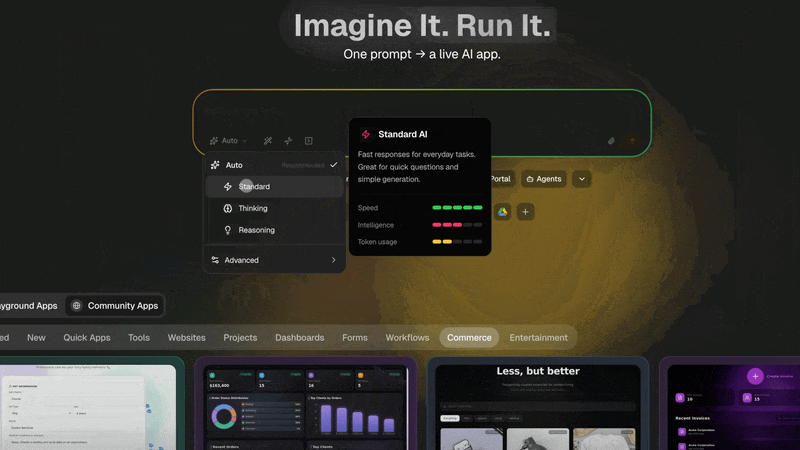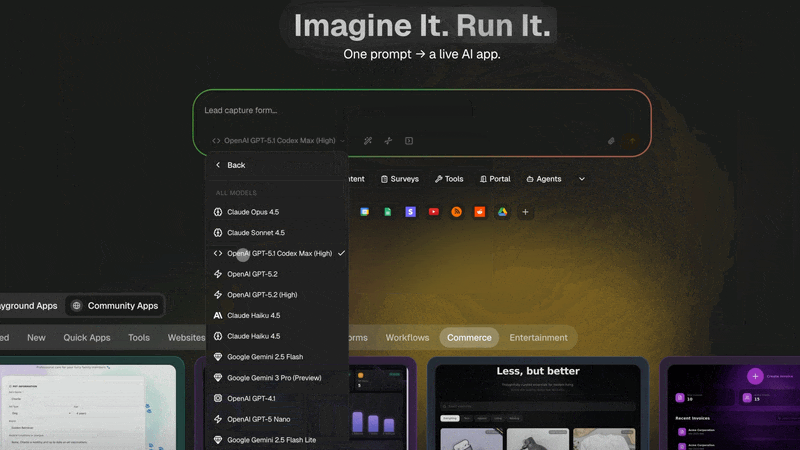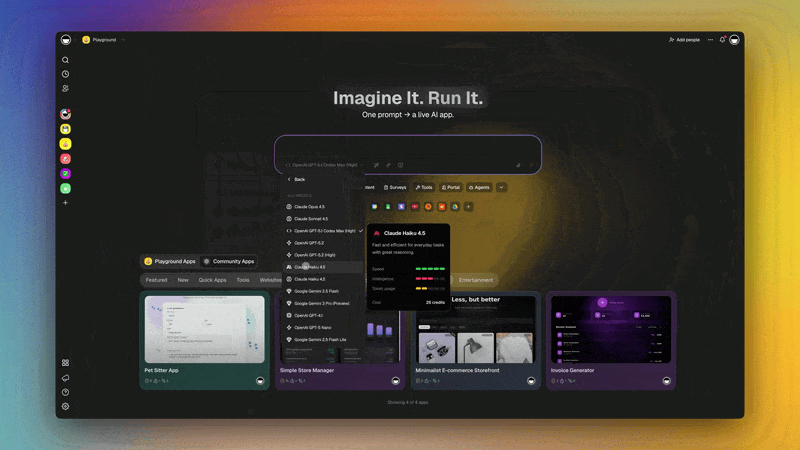
This is the UI surface for the meta level acting on the object level. Users — or the agent's planner — choose how much compute to burn per task. Same logic Snell et al. (2024) showed at the model layer.
Loop 3: Evaluation — Memory as the Substrate for Self-Improvement
In humans: decision journals (Annie Duke), expressive writing (Pennebaker), exam wrappers (Steve Orpurt's pedagogy).
In LLMs: Reflexion's episodic memory, vector memory, RAG over agent run logs.
In Taskade: Projects as the persistent substrate. Every Genesis run writes its trace, plan, and reflection into a Project. Future runs read it before starting.
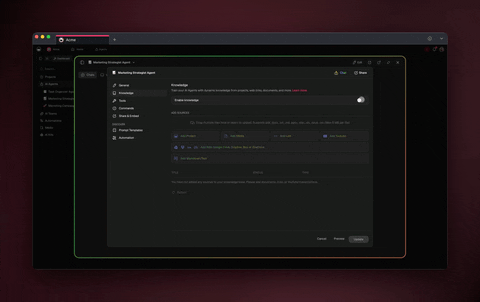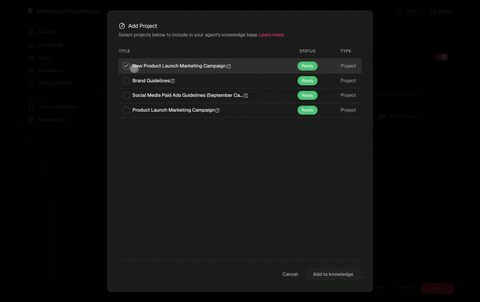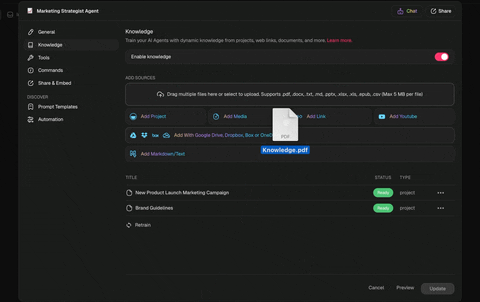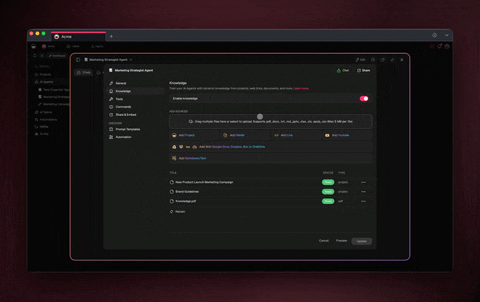
This is why Memory Reanimation Protocol matters. An agent that wakes up tomorrow with full context of yesterday's reflections is the engineering equivalent of a human who keeps a decision journal — exactly the practice Annie Duke advocates in Thinking in Bets for fighting hindsight bias.
🏥 Part V — When Metacognition Goes Wrong (Wells in Silicon)
Adrian Wells' deepest insight was that metacognition can fail in characteristic ways. The same patterns that produce GAD, OCD, and depression in humans produce specific failure modes in LLM agents. The diagnoses are the same. Only the substrate changes.
| Wells' clinical pattern | LLM agent failure mode | Production fix |
|---|---|---|
| Worry ("I must monitor for danger") | Threat-monitoring on every input ("safety check this benign request again") | Rule-based bypass for low-risk paths; calibrate the monitor |
| Rumination ("I must keep analyzing this") | Runaway tool-call loop, repeated self-critique | Agentic loop protection, max-step caps |
| Threat-monitoring | Over-defensive refusals; hallucinated risk | RLHF tuning; verifier agents on refusals |
| Unhelpful coping ("I'll just check one more time") | Excessive retries; over-verification of correct output | Confidence-gated retries; semantic-entropy thresholds |
| Metacognitive belief: "Worry helps" | System-prompted into perpetual self-doubt | Avoid "always second-guess" prompts; reflect on failure, not always |
| Detached mindfulness as MCT cure | Single-pass execution on confident answers; deliberation only on flagged ones | Thinking-mode auto-routing; bimodal compute |
The Huang et al. 2023 finding — naive self-correction degrades performance — is the LLM version of CAS. The fix is not "do more metacognition." It is calibrated metacognition: do it when it helps, don't when it doesn't, and have a way to tell the difference. That is exactly the move MCT made for human therapy. The therapeutic translation is direct.
🥊 Part VI — Genesis vs. The 2026 Field
Where does Taskade Genesis sit relative to the 2026 agent-builder landscape on the metacognition axis specifically? Honest, narrow comparison — just on this one capability:
| Platform | Persistent agent memory | Self-reflection loop | Loop protection | Multi-agent evaluator | Thinking-mode UI | Workspace-native |
|---|---|---|---|---|---|---|
| Taskade Genesis | Projects (5 memory types) | Reflexion-style verbal | Built-in | Yes | Standard / Thinking / Reasoning / Auto | Yes |
| ChatGPT Custom GPTs | Per-GPT memory (limited) | Manual | No | No | Reasoning toggle | No |
| Anthropic Claude Projects | Per-project knowledge | Manual | No | No | Extended thinking toggle | No |
| LangGraph (DIY) | Bring your own | DIY (Reflexion ref impl) | DIY | DIY | DIY | No |
| AutoGen / AG2 | Bring your own | Critic patterns | DIY | First-class | DIY | No |
| Cursor / Bolt / Lovable / V0 | Per-session | None | No | No | Per-IDE | No (code only) |
| Replit Agent | Per-repo | Limited | Limited | No | No | Code workspace |
| Manus AI | Sandbox memory | Some | Limited | No | No | Limited |
| Devin | Per-task | Some | Some | No | No | Code only |
| Notion AI | Page-level | None | No | No | No | Doc workspace |
| n8n / Make | Run history | None | Workflow-level | No | No | Automation only |
Two structural advantages worth naming:
- Workspace-native means metacognition compounds. Every agent run writes into the same Projects substrate the next agent reads. Multi-agent collaboration is multi-agent metacognition because they share the memory.
- Three loops, one product. Most platforms ship one of {memory, reasoning, automation}. Genesis ships all three, and they share state. The metacognitive triple is structurally complete.
The field is moving in this direction. Taskade got there first because Workspace DNA was the design before the LLM era — Memory + Intelligence + Execution is older than ChatGPT. The retrofit was always going to be hard for tools that started as documents, IDEs, or chat interfaces.
📊 Part VII — Calibration: The One Skill Every Team Should Train
If you only adopt one practice from this post, adopt calibration training.
The straight diagonal is perfect calibration — when you say "70% sure," you're right 70% of the time. The curve below it is overconfidence — what most untrained humans (and most untuned LLMs) produce. Tetlock's Good Judgment Project showed that one hour of calibration training improves Brier scores by ~10%. Douglas Hubbard's How to Measure Anything has the standard drill: 90% confidence intervals on trivia questions, scored against truth.
For LLM agents, the same exercise looks like this:
| Step | Human practice | Agent practice |
|---|---|---|
| 1 | Write decision + 90% CI | Generate answer + verbalized confidence |
| 2 | Lock in — no peeking | Save to memory before checking |
| 3 | Reveal truth | Run verifier / ground truth check |
| 4 | Score & adjust | Update Brier score / ECE per agent |
| 5 | Repeat | Use as RLHF / fine-tune signal |
A multi-agent Genesis setup that pairs a generator agent with a verifier agent and stores the calibration history in a Project becomes, structurally, the Good Judgment Project for a single team. After a few hundred runs, you have an empirical confidence curve for that agent on that domain — and you can bet accordingly.
⚠️ Part VIII — Limits, Honestly
Three things to keep in mind, because this post is long enough to need them:
1. Introspection is unreliable — for humans and models
Nisbett & Wilson, 1977 — Telling More Than We Can Know is the canonical finding. Humans confabulate plausible reasons for behavior they did not actually choose. The 2024–2025 mechanistic-interpretability work on LLMs increasingly suggests the same: chain-of-thought traces are sometimes post-hoc storytelling, not causal explanation. Self-reports are evidence, not proof. Production systems pair them with external verifiers.
(Related deep dive: Mechanistic Interpretability — Understanding AI.)
2. Metacognitive overconfidence is the default
Dunning-Kruger, critiques and all, holds in its core: poor performers often lack the metacognitive ability to recognize their poorness. The same applies to fine-tuned LLMs in narrow domains. The only known correctives are calibration training and external feedback loops — not more introspection.
3. More metacognition isn't always better
Flavell knew this in 1979. Wells built a whole therapy on it. Huang et al. proved it for LLMs in 2023. Rumination is metacognition gone wrong. The right level of self-monitoring is bimodal — heavy in preparation, suspended during confident execution. Production agents should not reflect by default. They should reflect on signal.
🧭 Part IX — A Practical Playbook for Teams Using AI Agents
Five practices, in order of leverage:
Practice 1 — Force articulation before action
Borrowed from the self-explanation effect (Chi et al., 1989). Require agents to write a structured plan — goals, sub-tasks, expected output — before tool calls run. The same forcing function that makes humans learn from worked examples makes LLMs commit fewer reasoning errors.
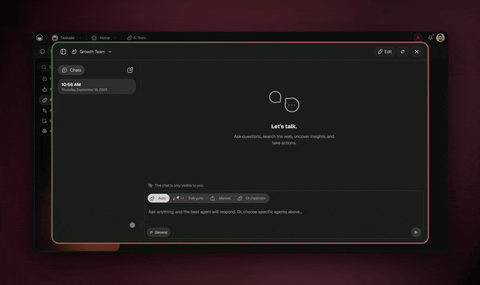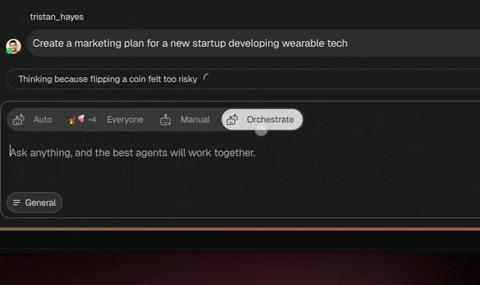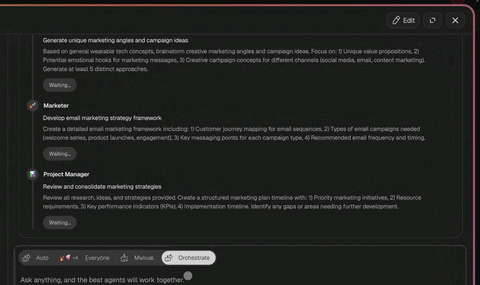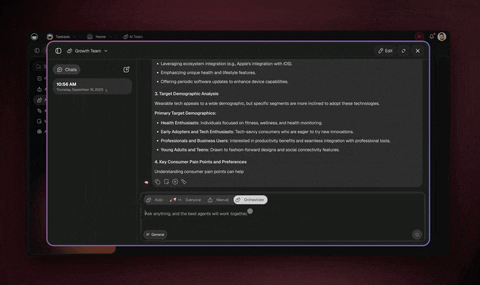
In Taskade Genesis, this is the planner step in any multi-agent flow.
Practice 2 — Verifier agents as the meta level
A second agent whose only job is to grade the first. Decoupled. No shared state inside the call. Constitutional AI–style. The verifier's signal becomes the monitoring loop, the same way a human PFC monitors a human task.
Practice 3 — Decision journals in the workspace
Borrowed from Annie Duke / Thinking in Bets. Every consequential agent decision logs: situation, alternatives considered, chosen option, predicted outcome, probability, actual reasoning, emotional state (proxy: confidence score), and — later — actual outcome. This separates decision quality from outcome quality. Resulting (judging a decision by its outcome) is what destroys learning.
A Taskade Project with one row per agent run is exactly this. Free.
Practice 4 — Premortems before consequential workflows
Klein, HBR 2007. Before triggering a complex automation, run an agent whose only job is to imagine the workflow has already failed catastrophically and write the autopsy. Surface failure modes that risk-listing misses. This is metacognitive control at its most leverage.
Practice 5 — Bimodal compute
Heavy deliberation on hard, ambiguous, or high-stakes tasks. Single-pass on easy, repeatable, low-stakes ones. Use Auto thinking mode where available; configure thresholds where it isn't. The flow paradox holds: peak performance is when the meta level steps out of the way because it has done its work.
🌊 Part X — The Living-App Implication
If you accept the argument so far, an interesting consequence falls out. A software system with all three loops — persistent memory, monitoring/control, execution — is no longer just software. It's a system that improves itself in response to use.
This is the Living-App movement thesis. It's also why we wrote Software Runs Itself. The same metacognitive triple that produces a calibrated forecaster, a recovering MCT patient, or a top-tier Olympic athlete also produces — when implemented in software — an app that learns from its users.
This is the loop. It is older than computers. It is what made Homo sapiens dominant. We are now putting it inside our software.
🧩 Part XI — Connect the Dots: Further Reading
This post sits inside a hub-and-spoke cluster on Taskade's blog. If you came here through one node, here is the rest of the graph:
Foundations
- What Is Intelligence? From Neurons to AI Agents — the philosophical setup.
- The Cognitive Turn — Why Modern AI Is Rooted in Psychology — external psychology applied to AI design.
- How Do Large Language Models Work? Transformers Explained — the substrate.
- What Is Mechanistic Interpretability — Understanding AI — the limits of self-report.
Agent design
- What Is Agentic Engineering? Complete History from Turing to Karpathy — the discipline.
- Context Engineering: Complete 2026 Field Guide — what agents see.
- Multi-Agent Collaboration in Production — 5 memory types, loop protection.
- What Are AI Agents? The Future of Workflow Automation — the broader field.
- What Are Multi-Agent Systems? — orchestrating specialists.
- What Is Agentic AI? Autonomous Agents & LLM Frameworks — market and frameworks.
Genesis-specific
- Ultimate Guide to Taskade Genesis (2026) — the product reference.
- Taskade EVE — The Workflow Agent: Complete Capabilities Guide — meet EVE.
- Genesis Compilation: Prompt → Deployed App — how the build engine works.
- Workspace DNA Architecture — the deep architecture post.
- Agentic Workspaces — The Next Era of Collaborative AI — workspace as substrate.
- AI-Native vs AI Bolted-On — why architecture matters.
- Memory Reanimation Protocol — restoring context across runs.
- Software Runs Itself — The Age of Living Applications — the consequence.
- Living-App Movement — the broader thesis.
- Community Profiles, AI Thinking Modes & Multi-Model Agents — thinking-mode UI.
Practitioner adjacent
- Cognitive Offloading — How AI Is Taking Over Our Mental Load — the human side.
- Agentic Engineering Without Code — practical no-code agents.
- History of Mermaid.js: Diagrams as Code — the diagram substrate.
- What Is Grokking AI — When Models Suddenly Learn — emergent reasoning.
🎯 The Bottom Line
The 50-year arc closes with one design lesson: agents win by knowing when to think harder, when to stop, and what to remember — not by thinking the most. Flavell named the capacity in 1979, Reflexion hit 91% on HumanEval in 2023, semantic entropy made it measurable in 2024, and Taskade Genesis ships it as Memory + Intelligence + Execution in 2026.
Forty-six years ago, John Flavell named a thing he had been observing in three-year-olds: the gap between cognition and the awareness of cognition. The kids who closed the gap learned faster. The kids who didn't, didn't.
Three years ago, Reflexion-augmented agents on HumanEval did the same trick.
Last year, semantic entropy in Nature gave us a way to measure when LLMs are bluffing.
This year, Taskade Genesis ships the architecture as a product: Memory remembers, Intelligence reflects, Execution acts, the loop closes by itself, and EVE — the meta-agent — keeps her own decision journal as a Taskade Project where any user can read it.
The rest of the field will get there. The path is well-marked. The question for any team building or buying agent software in 2026 is whether you want to wire all three loops yourself, or pick a substrate where they come pre-wired.
Either way, the next decade of AI will not be won by the systems that think the most. It will be won by the systems that know when to think harder, when to stop, and when to write down what they learned.
Metacognition. The same word Flavell coined for three-year-olds.
Try Taskade Genesis free → — and watch your agents reflect on themselves in real time.
Written by the Taskade Team. Edited with help from EVE. EVE's reflections on this post are stored in her projects/memories folder, where they'll inform the next version. That's the loop.
Frequently Asked Questions
What is metacognition?
Metacognition is thinking about thinking — the awareness and regulation of your own mental processes. Coined by psychologist John Flavell in 1979, it has two parts: metacognitive knowledge (what you know about how you think) and metacognitive regulation (planning, monitoring, and evaluating tasks). Strong metacognition predicts better learning, decision-making, and self-correction in both humans and AI systems.
What is metacognition in AI?
Metacognition in AI is a system's ability to monitor and regulate its own reasoning — assessing what it knows, detecting uncertainty, and revising its approach. In LLMs, this shows up as self-reflection (Reflexion, 2023), iterative self-critique (Self-Refine, 2023), and calibration techniques like semantic entropy (Farquhar et al., Nature 2024) that flag hallucinations before they reach the user.
How do AI agents use metacognition?
AI agents use metacognition through three loops: monitoring (tracking confidence and uncertainty in each step), control (replanning, retrying, or escalating when confidence drops), and evaluation (storing reflections in persistent memory to improve future runs). Frameworks like Reflexion, Tree of Thoughts, and metacognitive prompting operationalize this. In Taskade Genesis, every agent inherits monitoring, replanning, and a memory-backed reflection loop by default.
Who coined the term metacognition?
Stanford developmental psychologist John H. Flavell coined the term metacognition in his 1979 American Psychologist paper "Metacognition and cognitive monitoring." His original work studied children's metamemory — their ability to predict whether they would remember something. Thomas Nelson and Louis Narens formalized the architecture in 1990 with their two-level monitoring/control model that still anchors the field.
What is the difference between cognition and metacognition?
Cognition is the mental work itself — perceiving, reasoning, remembering, deciding. Metacognition is the layer above: awareness of that work, judgments about how well it's going, and control over what to do next. Cognition asks "what is the answer?" Metacognition asks "do I actually know this, and should I think harder?" Nelson and Narens (1990) modeled this as an object level (cognition) and a meta level (the model of the cognition) connected by monitoring and control.
What is Reflexion in AI?
Reflexion is a 2023 framework by Shinn et al. (NeurIPS) where language agents store verbal self-reflections in episodic memory after a failure, then retry with the reflection in context. On HumanEval coding, Reflexion-augmented agents reached 91% pass-rate — close to GPT-4's ceiling at the time. It is the closest computational analogue to a human after-action review.
What is Self-Refine for LLMs?
Self-Refine is a 2023 prompting technique by Madaan et al. where one LLM generates an answer, the same model critiques it, and the critique drives a revision. The loop runs until the critique stops finding improvements. It produced ~20% gains across 7 tasks without external supervision and is the canonical generate-critique-revise scaffold used in modern agent frameworks.
What is semantic entropy and why does it matter for AI?
Semantic entropy (Kuhn, Gal, Farquhar, ICLR 2023; Farquhar et al., Nature 2024) is a calibration technique that detects LLM hallucinations by sampling many answers and measuring meaning-level disagreement, not surface token disagreement. High semantic entropy signals genuine uncertainty. It is the closest LLM analogue to human feeling-of-knowing and is now used in production hallucination detection.
How does Taskade Genesis use metacognition?
Taskade Genesis builds metacognition into every agent by default. Memory (Projects) stores the agent's history and reflections, Intelligence (Agents) monitors confidence and replans, and Execution (Automations) closes the loop by acting on the world and writing the result back to Memory. EVE, the Genesis meta-agent, even stores its own metacognitive state as Taskade Projects in a projects/memories folder — the platform eats its own dogfood.
What is metacognitive prompting?
Metacognitive prompting (Wang & Zhao, 2024) is a five-stage prompt scaffold modeled on Flavell's framework: clarify the question, form a preliminary judgment, critically evaluate it, decide, and rate confidence. It improved understanding benchmarks across multiple LLMs. It is the cleanest direct import of Flavell's 1979 taxonomy into modern prompting.
What is the Cognitive Attentional Syndrome and how does it apply to AI?
The Cognitive Attentional Syndrome (CAS) is Adrian Wells' clinical model of perseverative worry, rumination, and threat monitoring driven by unhelpful metacognitive beliefs ("worrying keeps me safe"). In LLM agents, the same pattern shows up as runaway tool-call loops, hallucinated certainty, and threat-monitoring on every input. Taskade's agentic loop protection is the technical analogue of Wells' Metacognitive Therapy intervention.
Can AI agents really self-improve without human feedback?
Partially. Frameworks like Reflexion, Self-Refine, and o1-style test-time deliberation improve performance through verbal self-feedback, but Huang et al. (DeepMind, 2023) showed that intrinsic self-correction without ground-truth signal often degrades performance. The 2026 position paper "Truly Self-Improving Agents Require Intrinsic Metacognitive Learning" frames this as the next research frontier — agents that learn to calibrate their own confidence over time.
What are AI thinking modes and how are they metacognitive?
Thinking modes (Standard, Thinking, Reasoning, Auto) let users — or the agent itself — choose how much deliberation to apply per task. Standard answers immediately; Thinking shows step-by-step chain-of-thought; Reasoning runs deeper test-time compute; Auto routes per task complexity. This is metacognitive control surfaced as a UI: deciding when to think harder is exactly what Nelson and Narens called the meta level acting on the object level.
How can teams use metacognition to get better results from AI agents?
Treat agents like humans: monitor calibration (do their confidence claims match reality?), force articulation (require structured plans before execution), close the feedback loop (store reflections in persistent memory), and build in friction at high-stakes steps (require approval before destructive actions). Teams that pair Taskade Genesis agents with Workspace DNA — projects as memory, automations as execution — get all four loops by default.
Will metacognitive AI replace human judgment?
No. Metacognition is a force multiplier, not a substitute. The deepest finding in human metacognition research (Nisbett & Wilson, 1977) is that introspection is unreliable — people confabulate plausible reasons for behavior they did not actually choose. The same is increasingly true for LLMs. Metacognitive AI works best when paired with external feedback loops: reviews, decision journals, and humans-in-the-loop on consequential calls.