





When two AI agents need to work together, the first question is not "which model" or "which prompt." It is far more basic: how does one agent actually get a message to the other, and trust it when it arrives?
That question hides three separate decisions that people routinely collapse into one. There is the transport, how a message physically moves from sender to receiver. There is the protocol, the format and rules the message follows. And there is the topology, the shape of who is allowed to talk to whom. Get these three right and a multi-agent system feels effortless. Get them wrong and you ship something that loops forever, leaks context between agents, or silently drops half its messages under load.
This is the definitive 2026 field guide to inter-agent communication. We separate transport, protocol, and topology; decode the alphabet soup of emerging standards (A2A vs MCP vs ACP vs ANP); walk the three core topologies (orchestrated, peer-to-peer, message bus); and cover the production failure modes, loops, identity, expiry, context bleed. That almost no competitor explains. It builds on our multi-agent collaboration lessons from 500,000+ deployments and the orchestration patterns we ship today.
TL;DR: Inter-agent communication is three decisions, not one: transport (how a message moves), protocol (A2A, MCP, ACP, ANP), and topology (orchestrated, direct A2A, or message bus). A2A connects agents to each other; MCP connects agents to tools, most systems use both. Taskade orchestrates agent teams through Taskade EVE so the communication layer is solved before you start. Build your first agent team free →
What Is Inter-Agent Communication?
Inter-agent communication is how multiple AI agents exchange messages, delegate work, and share results so they can collaborate on tasks no single agent could finish alone. It is the connective tissue of every multi-agent system, the difference between a pile of isolated chatbots and an actual team. Industry surveys in 2026 put the field at an inflection point: the arXiv survey of agent interoperability protocols (Ehtesham et al.) maps four competing standards emerging in barely eighteen months, a sign of how fast this layer is forming.
A useful mental model: human teams do not collaborate by sharing one brain. They collaborate by passing messages, a Slack ping, a handoff document, a stand-up update. Each person keeps their own context and receives only what is relevant. Inter-agent communication is the same idea applied to AI agents: each agent has its own memory, and the system moves structured messages between them.
Every inter-agent message answers a few questions before it is trusted: Who sent it? What are they allowed to ask for? Is the message still valid, or has it expired? Where should the reply go? Those four primitives, identity, permission, expiry, and routing, stay constant no matter which transport, protocol, or topology you pick. The rest of this guide is about choosing the wrappers around them well.
Transport vs Protocol vs Topology: The Three Decisions People Collapse Into One
The single most common mistake in agent architecture is treating "how agents communicate" as one question. It is three. Transport is the physical pipe (HTTP, WebSocket, gRPC, an in-process queue). Protocol is the language and contract (A2A, MCP, ACP, a JSON envelope you invented). Topology is the wiring diagram of who may talk to whom (orchestrated, peer-to-peer, bus). You decide each one independently, and every competitor blog that ranks for this query picks one lens and ignores the other two.
Keeping them separate is what makes a system portable. You can swap transports (HTTP today, gRPC tomorrow) without touching topology. You can adopt a new protocol without rewiring who talks to whom. The table below pins down each axis with the question it answers and concrete choices.
| Axis | Question it answers | Example choices |
|---|---|---|
| Transport | How does a message physically move? | HTTP, Server-Sent Events, gRPC, WebSocket, in-process queue |
| Protocol | What is the format and contract? | A2A, MCP, ACP, ANP, custom JSON envelope |
| Topology | Who is allowed to talk to whom? | Orchestrated hub-and-spoke, direct peer-to-peer, message bus |
Read it top to bottom and the alphabet soup stops being scary. A2A is a protocol. A message bus is a topology. HTTP is a transport. They are not alternatives to each other. They are different slots you fill. The rest of this guide fills each slot, starting with the one most people get wrong: topology.
What Are the Three Communication Topologies?
There are three ways to wire agents together: orchestrated (hub-and-spoke), direct A2A (peer-to-peer), and message bus (publish/subscribe). Each trades latency, reliability, and complexity differently, and most mature systems mix them. The choice of topology drives more of your reliability than the choice of protocol, a poorly wired peer mesh fails the same way regardless of whether it speaks A2A or a homegrown format.
Orchestrated (hub-and-spoke)
A single coordinator, an orchestrator or lead agent, receives the request, splits it into sub-tasks, routes each to the right specialist, and aggregates the results. This is the pattern we run by default in Taskade through Taskade EVE, the Taskade Genesis meta-agent, and the one we recommend for most workflows. It makes context isolation natural, gives you one place to detect loops, and produces a single coherent output. The trade-off is one extra hop: Agent A talks to the orchestrator, the orchestrator talks to Agent B. For the routing logic underneath, see agent routing and parallelization.
Direct A2A (peer-to-peer)
Agents send messages straight to each other as equals, with no central router. This is what people usually mean by A2A, agent-to-agent communication. It removes the orchestrator hop, so it is faster and more flexible for tightly coupled pairs of agents. The cost is that every agent now needs to verify identity, check permissions, and protect against loops on its own, because there is no central referee. See the agent collaboration primitives for how peers negotiate work.
Message bus (publish/subscribe)
A central message system acts like a post office. Agents publish messages to named topics and subscribe to the topics they care about, never connecting to each other directly. This decouples agents completely. You can add or remove an agent without touching any other, and gives you durable, asynchronous delivery plus one audit log for the whole system. The cost is an extra component you must operate and an extra hop on every message. Buses shine when events arrive unpredictably and many agents react to them, which overlaps heavily with how automations and integration orchestration already work.
A2A vs MCP: What Is the Difference?
A2A connects agents to other agents; MCP connects agents to tools and data. They solve different problems, and the confusion between them is the single most common mix-up in agent architecture conversations in 2026. The protocols' own maintainers state the distinction plainly: the Model Context Protocol spec describes a tool-and-context layer, while Google's A2A announcement frames A2A as the layer between agents, explicitly complementary to MCP, not a replacement.
Think of it as two different cables. MCP (Model Context Protocol) is the cable from an agent to a capability, a web search, a database query, a file read. It answers "how does this agent use a tool." A2A is the cable between two agents, a delegation, a question, a handoff. It answers "how do these two agents talk." A research agent that searches the web is using MCP; that same agent handing its findings to a writer agent is using A2A.
Most real systems use both at once. Agents reach their tools over MCP and coordinate with each other over A2A or through an orchestrator. Taskade exposes a hosted MCP server so any MCP-compatible client can connect to Taskade, and every Taskade agent ships with 34 built-in tools plus custom slash commands. The two layers are complementary, not competing, and they stack with two more layers above them, which the next section unpacks.
The Agent Protocol Landscape: A2A, MCP, ACP, ANP
Four protocols dominate the 2026 interoperability conversation, and they layer rather than compete: MCP at the tool layer, A2A at the inter-agent layer, and ACP / ANP at the orchestration and discovery layers. The arXiv interoperability survey frames them as a phased adoption roadmap, MCP first for tools, A2A next for agent messaging, then ACP and ANP for broader networks, rather than a winner-take-all race.
A2A: agent cards and the task lifecycle
A2A, announced by Google in April 2025 and now governed by the Linux Foundation, lets independent agents discover and delegate to each other. Each agent publishes an agent card at /.well-known/agent-card describing its skills, endpoints, and auth requirements. A client agent reads the card, then sends a task that moves through a defined lifecycle. Transports include JSON-RPC 2.0, Server-Sent Events for streaming, and gRPC. The official A2A docs cover the wire format; the lifecycle states are worth memorizing because named primitives win citations.
MCP: the tool layer
MCP, originated by Anthropic, standardizes how an agent reaches a tool, a data source, or a file system. A client connects to an MCP server, discovers the tools it offers, and calls them over JSON-RPC (across stdio for local servers or HTTP for remote ones). MCP is about capabilities, not coordination. It never tells two agents how to talk to each other. Taskade ships a hosted MCP server on every paid plan and an outbound MCP client on Business and above.
ACP: REST-based multimodal messaging
ACP (Agent Communication Protocol), from IBM and the BeeAI community, is a RESTful protocol for multimodal agent messaging and lightweight orchestration. It leans on familiar HTTP semantics and supports multi-part messages (text, images, structured data), which makes it approachable for teams already comfortable with REST APIs.
ANP: decentralized agent networks
ANP (Agent Network Protocol) targets the open, decentralized end of the spectrum. It uses decentralized identifiers (DIDs) and JSON-LD so agents from different operators can find and trust each other without a central registry, the vision the Agentic Web paper sketches for inter-agent communication at web scale.
| Dimension | MCP | A2A | ACP | ANP |
|---|---|---|---|---|
| Connects | Agent to tools | Agent to agent | Agent to agent | Agent to agent |
| Layer | Tool | Inter-agent | Orchestration | Discovery |
| Transport | JSON-RPC / stdio-HTTP | JSON-RPC + SSE + gRPC | REST / HTTP | DIDs + JSON-LD |
| Identity | Host-managed | OIDC / JWT | HTTP auth | Decentralized (DIDs) |
| Best for | Tool access | Cross-vendor agents | Multimodal REST teams | Open networks |
Is A2A a Single Standard?
A2A has a published specification under the Linux Foundation, but the broader agent-interoperability space is still consolidating. It is best read as a leading pattern, not a frozen monopoly. The same eighteen-month window that produced A2A also produced MCP, ACP, and ANP, and Google Cloud's own notes on A2A's evolution describe ongoing upgrades under shared governance. Betting your entire architecture on one wire format being final in 2026 is premature.
The durable move is to build on the primitives that survive whichever format wins, not on the syntax of any one spec. Five primitives recur across every serious protocol:
| Primitive | What it does | Survives because |
|---|---|---|
| Identity | Proves who sent a message | Every protocol needs trust |
| Capability discovery | Advertises what an agent can do | Agent cards, DIDs, registries all do this |
| Structured messages | A typed envelope, not free text | Required for reliable parsing |
| Tracking IDs | Correlates a conversation end to end | Debugging is impossible without it |
| Expiry / TTL | Bounds how long an instruction lives | Stops stale messages from acting |
Design your agents to require these five, and you can swap A2A for ACP, or a homegrown envelope for a future standard, without rewriting your coordination logic. That portability is worth more than early adoption of any single spec.
How Do You Structure an Inter-Agent Message?
A reliable inter-agent message is a structured envelope, not a free-text chat line. The most common cause of flaky multi-agent systems is agents passing each other vague prose ("look into the pricing thing") instead of typed fields with a clear definition of done. Borrowing the spirit of the Twelve-Factor App, here is a "12-factor for agent messages" envelope every handoff should carry.
{
"from": "research-agent", # verified sender identity
"to": "writer-agent", # explicit recipient
"objective": "Draft a 600-word intro on A2A",
"inputs": { "sources": [ ... ] }, # only what the recipient needs
"outputs": "markdown", # expected shape of the reply
"constraints": [ "no competitor links", "cite arXiv" ],
"done_when": "intro passes fact-check + word count",
"tracking_id": "task-8f3a-0192", # correlates the whole thread
"expires_at": "2026-06-19T12:00:00Z" # TTL: stale after this
}
Each field removes a class of failure. Without objective and done_when, the recipient guesses when it is finished, a top cause of loops. Without tracking_id, you cannot trace a conversation across agents. Without expires_at, a delayed message can act on context that no longer exists. The table below maps each field to its purpose.
| Field | Purpose | Example |
|---|---|---|
| from / to | Identity + explicit routing | research-agent → writer-agent |
| objective | The single task in plain language | "Draft a 600-word intro" |
| inputs | Scoped context, not the full transcript | three source URLs |
| outputs | Expected shape of the reply | markdown, JSON, a number |
| constraints | Hard rules the reply must obey | cite arXiv, no PII |
| done_when | Explicit definition of done | passes fact-check |
| tracking_id | Correlates the whole thread | task-8f3a-0192 |
| expires_at | TTL after which the message is void | ISO timestamp |
This is the same discipline our context engineering field guide applies to a single agent, extended to the seams between agents.
Coordination Patterns Beyond Topology
Topology decides who can talk; coordination patterns decide how a conversation is structured once they can. Four patterns cover most real systems: maker-checker, group-chat orchestration, multicast, and request-response versus async message passing. They compose with any topology.
| Pattern | What it is | When to use | Trade-off |
|---|---|---|---|
| Maker-checker | One agent produces, another critiques | Quality-critical output | Doubles token cost |
| Group-chat orchestration | Turn-taking under a moderator | Open-ended problem solving | Needs a turn manager |
| Multicast / event-driven | One event, many reactors | Fan-out reactions | Hard to trace |
| Request-response | Synchronous ask-and-wait | Tight dependencies | Blocks the caller |
| Async message passing | Fire-and-forget with callbacks | Long-running work | Needs correlation IDs |
The most under-used of these is maker-checker, separating generation from criticism. A maker agent drafts an artifact, a checker agent critiques it against the constraints, and they loop until the checker accepts (with a hard cap so they cannot loop forever). This separation reliably raises quality because the checker is not anchored on the maker's own reasoning. It mirrors the reflection pattern applied across two agents instead of one.
What does each coordination pattern cost?
Every coordination pattern trades tokens, latency, or wall-clock time for quality and resilience, and the trade is predictable enough to budget for up front. The table below sizes each pattern relative to a single direct agent call (1×) so you can reason about the bill before you ship, not after the invoice arrives.
| Pattern | Relative token cost | Added latency | Buys you | Budget guard |
|---|---|---|---|---|
| Single agent | 1× (baseline) | None | Speed, simplicity | Output validation |
| Maker-checker | ~2–3× | One critique round per loop | Higher-quality output | Hard iteration cap |
| Group-chat | ~N× (one per speaker per turn) | Turns are sequential | Open-ended reasoning | Turn limit + moderator |
| Multicast fan-out | ~N× (parallel) | Lowest — runs concurrently | Speed across reactors | Per-branch isolation |
| Orchestrated team | ~1.5–2× over flat | One coordinator hop | Reliability, clean aggregation | Loop chokepoint |
The lesson hidden in this table: coordination is not free, but the most expensive pattern is the one that loops. A maker-checker pair that never agrees, or a group chat with no turn cap, can burn 10× the expected tokens before anyone notices, which is exactly why the loop-protection section below treats token-budget overrun as a first-class detection signal, not an afterthought.
Which Topology Should You Choose?
Default to orchestrated for most workflows, reach for direct A2A when latency between two tight collaborators matters, and use a message bus when you have many agents reacting to asynchronous events. The table below is the decision at a glance.
| Dimension | Orchestrated (hub-and-spoke) | Direct A2A (peer-to-peer) | Message bus (pub/sub) |
|---|---|---|---|
| Routing | Central coordinator | Agent to agent | Topic-based broker |
| Latency | One extra hop | Lowest (no hop) | One extra hop |
| Context isolation | Strong — coordinator gates it | Manual per agent | Strong — topics scope it |
| Loop control | Easy (one chokepoint) | Hard (every pair) | Medium (broker can cap) |
| Scaling | Coordinator can bottleneck | Connections grow ~N² | Excellent — add subscribers |
| Best for | Most multi-step tasks | Tight, repeated pairs | Many agents, async events |
The scaling row is the one teams underestimate. In a pure peer-to-peer mesh, the number of possible connections grows with the square of the number of agents, five agents have ten possible edges; ten agents have forty-five; twenty agents have one hundred and ninety. Each edge is another pair that needs identity, permission, and loop protection. An orchestrator collapses that to a star: N spokes, one hub, linear growth.
Hub-and-spoke (orchestrated) Full mesh (peer-to-peer)
A A───B
│ │╲ ╱│
D ── HUB ── B │ ╳ │
│ │╱ ╲│
C D───C N spokes, 1 hub (linear) ~N(N-1)/2 edges (quadratic)
The gap is not academic. Plot the two growth curves and the orchestrator's advantage compounds: at twenty agents a hub manages twenty connections while a full peer mesh has to secure one hundred and ninety, each one a fresh pair that needs identity, permission, and loop protection wired and tested.
The mesh line is the reason most production teams converge on a coordinator: it caps the security and observability surface at N no matter how many specialists you add. A simple decision tree captures the rule:
Need agents to coordinate?
├── One coordinator can own the workflow? ──── YES ──> ORCHESTRATED (default)
│ NO
│ │
├── Two agents, latency-critical, repeated? ── YES ──> DIRECT A2A
│ NO
│ │
└── Many agents reacting to async events? ──── YES ──> MESSAGE BUS
NO ──> ORCHESTRATED
Map it to workloads and the choice is usually obvious:
| Workload | Recommended topology | Why |
|---|---|---|
| Multi-step task with one goal | Orchestrated | One owner, easy loop control, clean aggregation |
| Tight pair exchanging fast | Direct A2A | No hub hop, lowest latency |
| Many agents, async events | Message bus | Durable fan-out, single audit log |
This is the same lesson behind our agent orchestration and routing work: a small amount of central coordination buys a large amount of reliability.
How Do You Keep Agent Conversations From Breaking?
Inter-agent communication fails in predictable ways: messages loop, context bleeds between agents, deliveries get dropped, and unverified senders issue instructions they should not have. Each has a known detection signal and a known defense. Build all of them in from the start rather than bolting them on after the first incident.
| Failure | Symptom | Detection signal | Defense |
|---|---|---|---|
| Loop | Agents ping-pong forever | Repeat / similarity / budget | Inject correction, summary exit |
| Context bleed | Role confusion, diluted output | Cross-agent transcript leakage | Scope context per recipient |
| Dropped delivery | Silent stalls under load | Missing acks / timeout | Retry + dead-letter queue |
| Unverified sender | Unauthorized instructions | Failed identity check | Reject + log at the gate |
| Stale instruction | Action on dead context | Expired TTL | Drop + notify |
Identity and permission first: least privilege
Before any agent accepts a message, it should verify who sent it and check what that sender is allowed to ask for. This is least privilege applied to agents: each agent gets exactly the capabilities and conversation partners its role requires, and nothing more. A writer agent does not need database access; a data agent does not need to publish blog posts. Tight scoping removes whole categories of failure before they happen. See agent governance for the policy layer.
Loop protection on every channel
Loops are the most common failure in multi-agent systems, and almost no published guide gives a concrete recipe, OneUptime's implementation guide explicitly omits it. Detection uses three signals: repeated identical messages, rising output similarity across turns, and token-budget overrun. When a loop is detected the system injects a corrective instruction; if that fails, it forces a summary exit so the user still gets partial useful output. Conversation-depth caps and the agent loop controls are the hard backstops, and agentic exception handling defines what happens when a channel trips.
Message expiry and tracking IDs
Every message should carry a tracking ID and an expiry. The tracking ID lets you trace a single conversation across agents, essential for debugging distributed runs and feeding goal monitoring. The expiry prevents stale instructions from acting long after the context that produced them is gone. Together they turn an opaque tangle of agent chatter into something you can audit and replay.
Context isolation by default: less shared context, better output
The counterintuitive production lesson: agents perform better with less shared context, not more. When the research agent's raw search dumps land in the writer agent's window, they dilute attention and sometimes cause role confusion. Each agent should receive only the specific output it needs, not the full transcript. This is a reliability lever, not just a cost lever, and it mirrors how agent memory and multi-agent teams keep specialists focused. Resource-aware optimization and task prioritization extend the same principle to compute.
Every message in a well-built system runs the same gauntlet: identity, permission, expiry, loop check, then scoped delivery.
The same gauntlet reads cleanly as an aligned pipeline, which is easier to scan than the branch diagram:
message ──> [ identity ] ──> [ permission ] ──> [ expiry ] ──> [ loop check ] ──> [ scoped delivery ]
│ │ │ │
reject reject drop correct
+ log + log + notify then exit
Skip any stage and you reintroduce one of the failure modes from the table above.
Security and Trust Between Agents
Inter-agent security rests on three pillars: authenticate every sender, scope every permission, and treat agent-supplied content as untrusted input. The arXiv security analysis of agentic communication protocols evaluates A2A, MCP, ACP, and ANP against a shared threat model and finds the same recurring gaps, weak identity binding, over-broad tool scopes, and prompt-injection across the message boundary.
Authentication in A2A uses OIDC and JWT; agents can also be treated as opaque, a client trusts an agent's published interface without seeing its internals, which limits the blast radius of a compromised partner. Three rules cover most of the surface:
- Verify agent cards from trusted sources. An agent card advertises capabilities, but a forged card can advertise capabilities an agent does not actually have. Fetch cards over authenticated channels and pin the issuers you trust.
- Treat inbound agent messages as untrusted. A compromised or jailbroken upstream agent can attempt prompt injection through the message body. The same input-sanitization discipline you apply to user input applies to agent-to-agent input.
- Scope tools per role, not per system. Identity-spoofing damage is bounded by what the spoofed identity can actually do. Least privilege turns a breach into a contained incident instead of a system-wide one.
These are protocol-agnostic. Whether you run A2A, ACP, or an orchestrated star, the threat model is the same, which is one more reason to build on the durable primitives rather than any single spec.
Where Does Inter-Agent Communication Show Up?
Inter-agent communication is the backbone of nearly every serious agent application: order processing, research pipelines, content production, and operations monitoring all coordinate specialist agents. The pattern is identical even when the domains look nothing alike, a chain or fan-out of specialists passing structured messages under a coordinator.
Swap the agents and you have a research pipeline (crawler, fact-checker, writer, editor, publisher) or a financial-analysis platform (data, technical, fundamental, risk, report). The agents change; the communication architecture does not. That is exactly what Taskade's agent teams automate, and what our agentic workflows and agentic AI systems posts walk through in depth. The communication layer is the part you most want handled for you, because it is the part that breaks most often when hand-rolled.
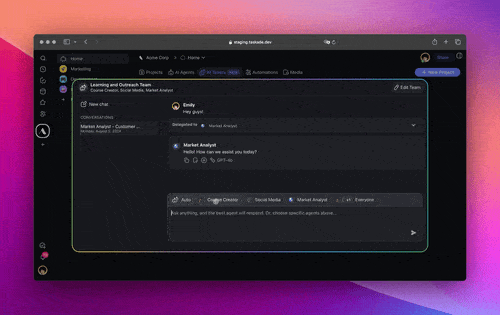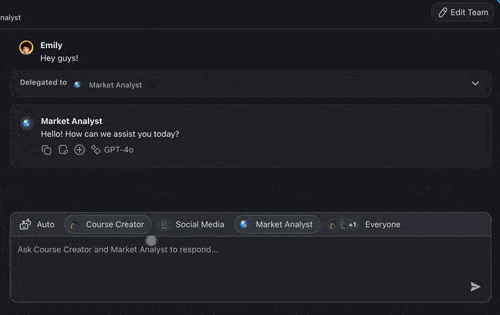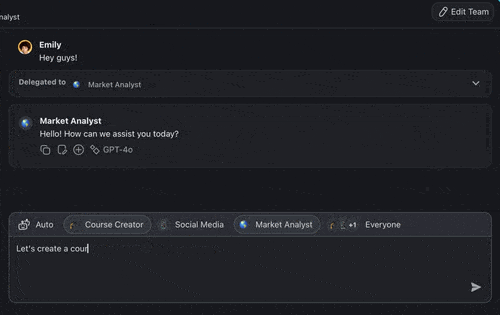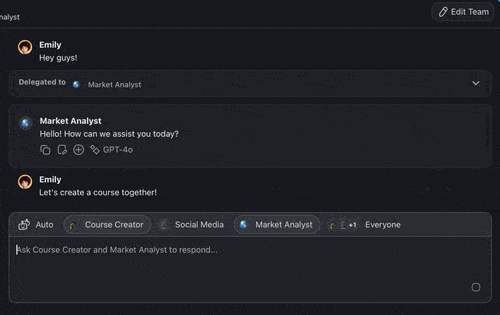
Build a Two-Agent Communication Flow Without Code
Every competitor on this topic assumes you hand-roll transports, brokers, and loop detection in Python. Taskade productizes the most reliable topology, orchestrated hub-and-spoke. So the communication layer is solved before you start. You can build the exact researcher-to-writer handoff this guide describes in code, without writing any transport code at all.
Taskade orchestrates agent teams through Taskade EVE, the Taskade Genesis meta-agent. Taskade EVE breaks a request into sub-tasks, routes each to a specialist agent with its own isolated context, and aggregates the results into one coherent answer, the orchestrated topology, built in. Three execution modes map directly onto the topology choice:
- Simple, describe the outcome and let Taskade EVE handle routing and aggregation. One prompt, a coordinated result.
- Manual. You specify the agents and steps; Taskade runs the messaging and context isolation between them.
- Orchestrate, a fully directed multi-agent run where the lead agent delegates, monitors, and synthesizes across specialists.
A real example, researcher to writer. Create two custom agents: a Researcher scoped to web search, and a Writer scoped to drafting. In Orchestrate mode, Taskade EVE hands the Researcher's findings to the Writer as a scoped message, the Researcher's raw search dumps never flood the Writer's window, which is exactly the context isolation the reliability section recommends. Agents can invoke other agents, call 34 built-in tools, and run across 15+ frontier models from OpenAI, Anthropic, Google, and open-weight providers with Auto selecting the right one per task, routing cheaper work to fast models and harder work to more capable frontier models, scaled by plan.
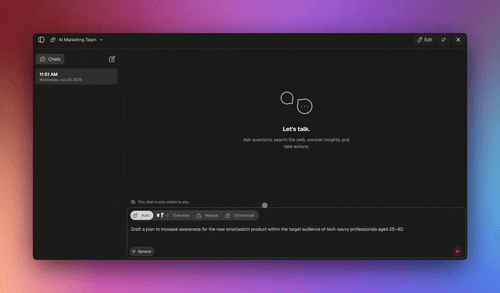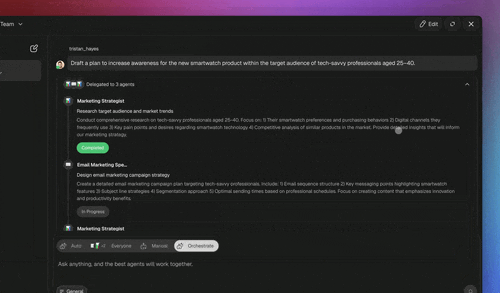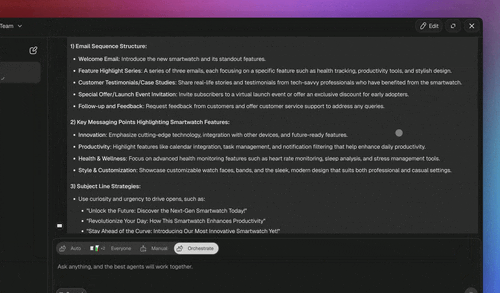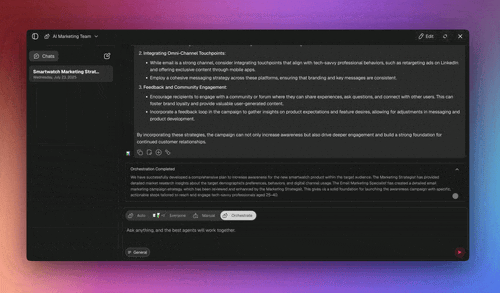
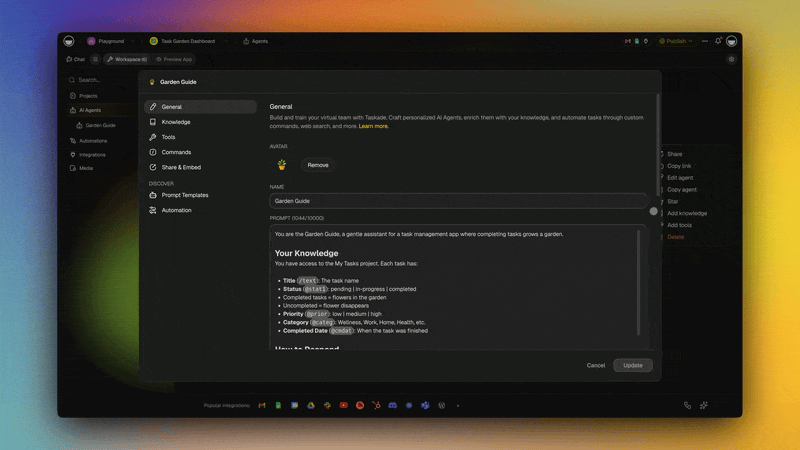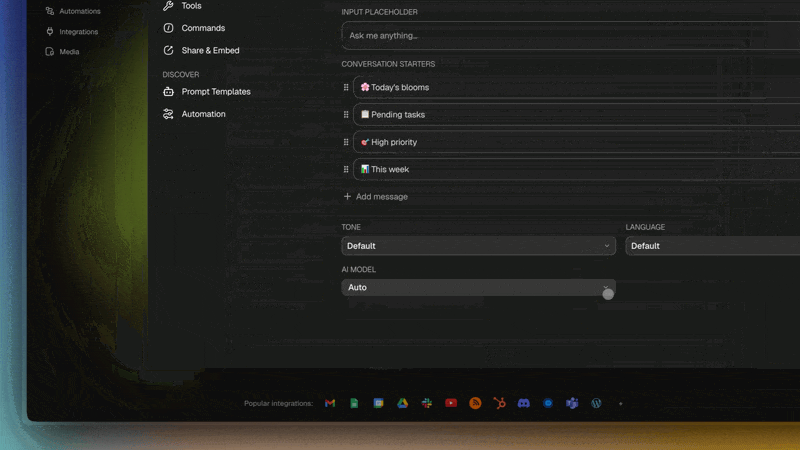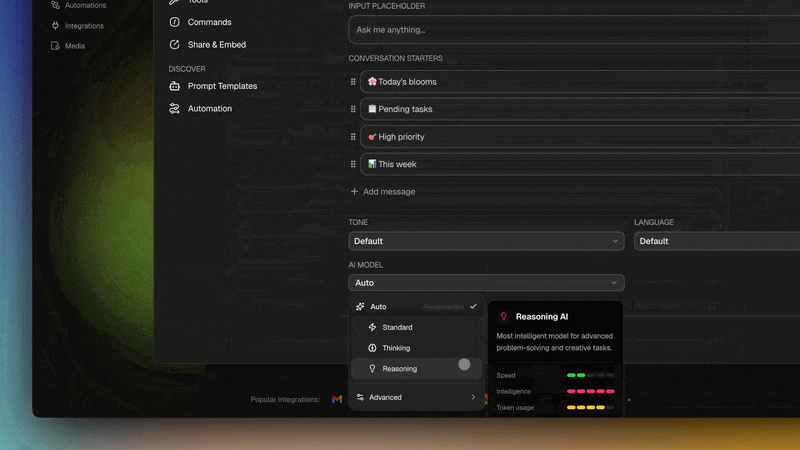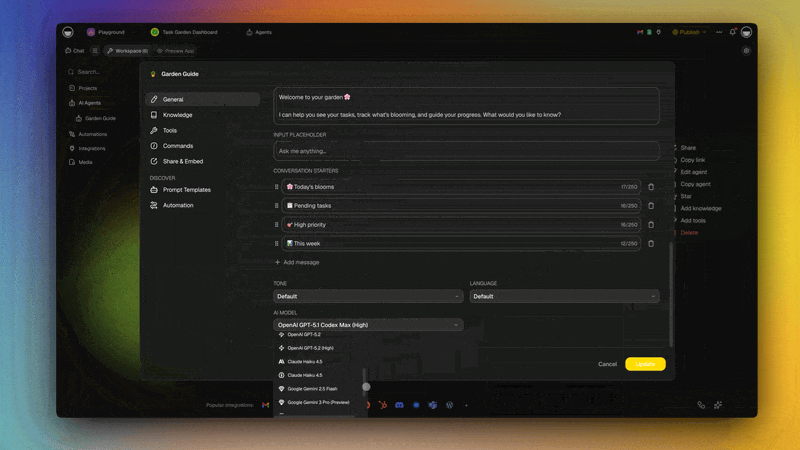
Model selection is a routing decision too. Auto is the default selector, but any agent can pin its own model, a fast lightweight model for the Researcher's high-volume search summaries, a more capable frontier model for the Writer's final draft. That per-agent choice is the model-routing axis layered on top of the agent-routing axis: which agent handles the message, and which model that agent runs on, are two independent decisions you control without leaving the workspace.
The full capability surface you can route across
The researcher-to-writer handoff is the smallest version of the pattern. The same building blocks compose into much larger routed systems, and it helps to see the whole surface at once, every row is something you can wire into a flow today, framed as capability, not as a guaranteed shipped algorithm you bolt on.
| Capability | What it gives the communication layer | Maps to |
|---|---|---|
| Taskade EVE meta-agent | Splits a request, routes sub-tasks, aggregates results | Orchestrated topology |
| 3 modes (Simple/Manual/Orchestrate) | Pick how much coordination control you want | Topology selection |
| 34 built-in tools + slash commands | Each agent reaches data and actions | MCP tool layer |
| Auto model routing + per-agent pin | Right model per task, or a fixed one you choose | Model-routing axis |
| Persistent memory | Each agent keeps its own context across turns | Per-agent identity + isolation |
| Automations + 100+ integrations | A trigger dispatches to the right agent or workflow | Rule-based front door |
Persistent memory is the quiet differentiator. Because each agent keeps its own memory across a run, the orchestrator can hand a specialist a scoped message instead of replaying the entire transcript, context isolation that is a property of the platform, not something you re-implement per project. Memory also closes the Workspace DNA loop: the outcome of one coordinated run becomes context for the next.
Automations are the rule-based router sitting in front of the AI one. A trigger fires on an event, a form submission, a new row, an inbound webhook, and dispatches to the right agent or workflow before any model runs. That is the cheap, deterministic first stage of a layered router: an explicit rule handles the clear cases instantly, and only the ambiguous remainder reaches Taskade EVE for AI routing. The same flow combines rule-based and AI-based routing, extended across 100+ bidirectional integrations.
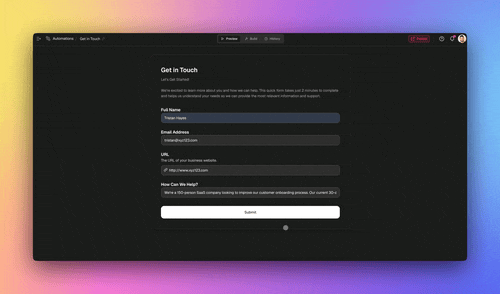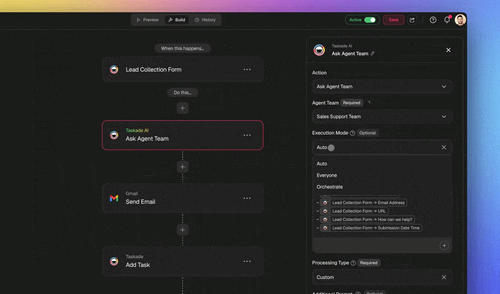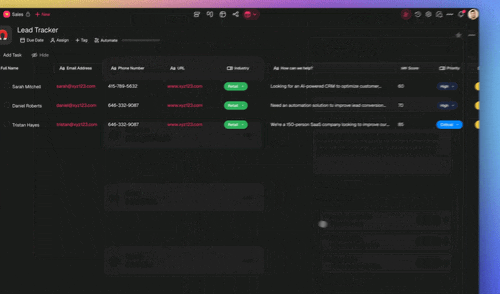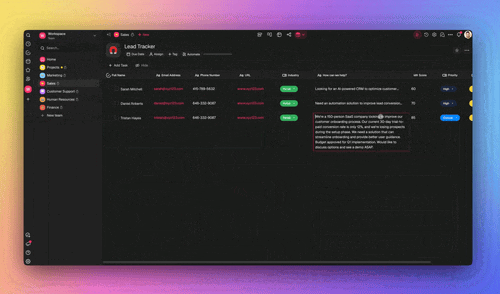
Put the two routers together and you get the layered front door the reliability literature recommends, a cheap deterministic check first, AI only for the ambiguous remainder, assembled without writing a line of transport code.
And because a finished agent team can ship as a live app, built from one prompt, publicly embeddable, optionally on your own custom domain, and listed in the Community Gallery, the communication architecture you assemble is not a throwaway script. It is a deployable system other people can use.
Tools and external data flow through the hosted MCP server and 100+ bidirectional integrations, so the tool layer (MCP) and the agent layer (A2A-style coordination) are both covered. Identity and permission inherit from your workspace's role-based access, least privilege by default, and the orchestrator gives you a single chokepoint for loop protection and observability. That is the reliability advantage of hub-and-spoke without wiring a message bus, building an identity layer, or writing your own loop detection.
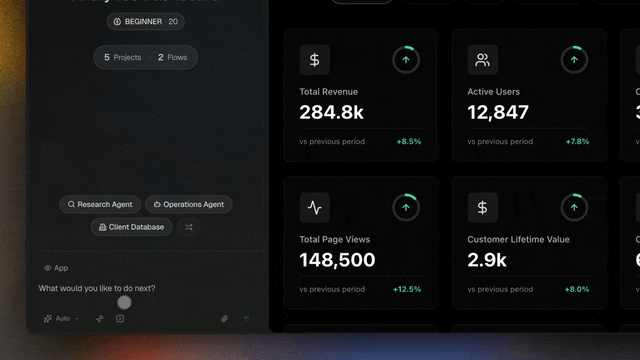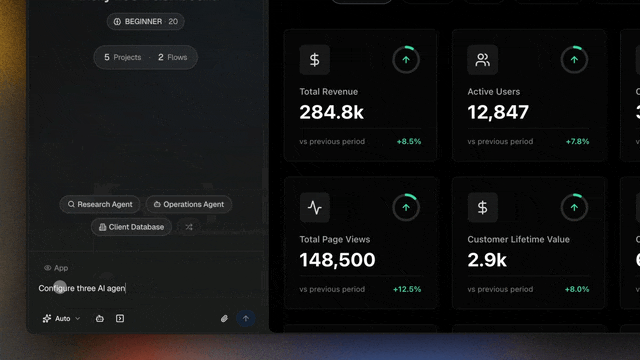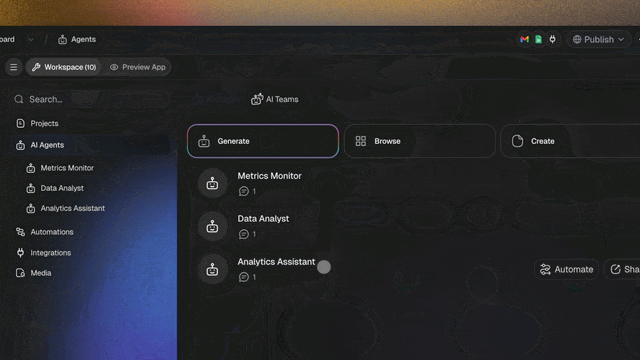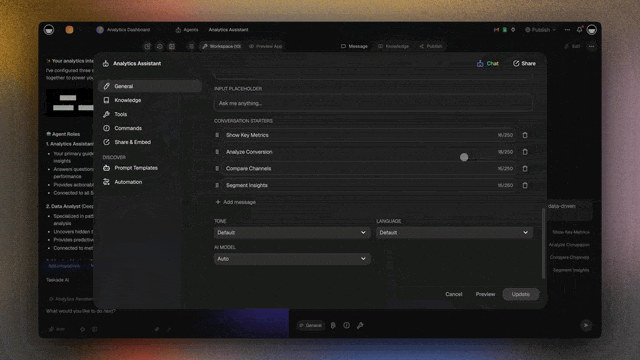
Honest scope: Taskade ships orchestrated agent teams, agent-invokes-agent collaboration, MCP tool access, and built-in loop protection today. It does not claim a finalized open A2A wire standard or a user-facing message-bus configuration surface, the orchestrated path is what we run in production because it is the most reliable, and it is what we recommend you start with. Set your agents up with our custom agents guide, connect them in team chat, and wire downstream actions with automation triggers.

A2A vs MCP vs ACP: Quick Reference
When in doubt, map each protocol to its layer, its transport, and what it is best for. Then combine them. MCP for tools, A2A for agents, ACP for multimodal REST teams, an orchestrator to tie it together.
| Protocol | Layer | Transport | Best for | Combine when |
|---|---|---|---|---|
| MCP | Tool | JSON-RPC / HTTP | Agent reaches tools and data | Always — every agent needs tools |
| A2A | Inter-agent | JSON-RPC + SSE + gRPC | Cross-vendor agent delegation | Agents from different operators talk |
| ACP | Orchestration | REST / HTTP | Multimodal agent messaging | REST-native teams need multipart |
| Orchestrator | Topology | Internal | Reliable coordination + loop control | You want one chokepoint (default) |
The honest answer to "which one do I pick" is rarely one of them. A production system typically runs MCP for tools plus an orchestrator (or A2A) for coordination, the layers stack. This sits inside the broader Workspace DNA loop, where coordination is one stage of a larger cycle.
Putting It Together
The three decisions, transport, protocol, topology, are what actually determine whether your agents collaborate or collapse. Choose orchestrated for most work, direct A2A for tight pairs, and a message bus for many agents reacting to events. Remember that A2A connects agents to each other while MCP connects agents to tools, and that you will usually need both, alongside ACP and ANP as the space consolidates. And never ship inter-agent communication without identity, permission, expiry, and loop protection on every channel.
Build on the durable primitives, identity, capability discovery, structured messages, tracking IDs, expiry, rather than betting everything on one wire format, and your system stays portable as the standards settle. The structured envelope, the maker-checker pattern, and the per-message gauntlet are the parts you carry from one protocol to the next.
If you want to skip the plumbing, that is exactly what Taskade orchestrates for you. Start with two agents, give each a focused role, and let Taskade EVE handle the messaging between them. The communication layer is solved; the question is what team you build on top of it.
▲ Memory feeds context to every specialist. ■ Intelligence routes and coordinates the agents as inter-agent communication. ● Execution turns their combined output into action, and writes the result back to Memory.
Build your first multi-agent team free →
Companion Reads: The Multi-Agent Cluster
- Agentic Design Patterns, the pattern catalog this guide draws from
- Multi-Agent Collaboration in Production: Lessons from 500,000+ Deployments, the engineering story behind the orchestration layer
- Context Engineering Field Guide, why scoped context beats more context
- What Is Agentic Engineering?, the Karpathy-to-agents arc
- The AI Agents Taxonomy, where communicating agents sit in the broader map
- Agentic Workspaces, the workspace as the substrate agents coordinate over
- Orchestration (wiki), the canonical reference for the hub-and-spoke pattern
- Explore real agent teams in the Community Gallery, see the pattern running in published apps
Stan Chang is CTO and co-founder at Taskade. He leads the engineering team behind Taskade's AI agents, the Taskade Genesis app builder, and the automation platform. Follow the engineering series for more production AI architecture posts.
Frequently Asked Questions
What is inter-agent communication in AI?
Inter-agent communication is how multiple AI agents exchange messages, delegate tasks, and share results so they can collaborate on work no single agent could finish alone. It covers three separate decisions people often collapse into one: a transport (how a message physically moves), a protocol (the message format and rules), and a topology (the shape of who talks to whom). In Taskade, Taskade EVE orchestrates agent teams so this coordination happens without you wiring a message bus by hand.
What is the A2A protocol (agent-to-agent)?
A2A (Agent2Agent) is an open protocol, originally announced by Google in April 2025 and now governed by the Linux Foundation, that lets independent agents discover and message each other. Agents publish an agent card at a well-known URL advertising their capabilities, then exchange tasks that move through a lifecycle of submitted, working, input-required, and completed or failed states over JSON-RPC, SSE, or gRPC. Taskade supports A2A-style collaboration through orchestrated agent teams where agents invoke other agents under shared workspace rules.
How is MCP different from A2A?
MCP (Model Context Protocol) connects an agent to tools and data sources, while A2A connects an agent to other agents. MCP answers how an agent uses a capability such as a search tool, a database, or a file system. A2A answers how two agents talk and delegate. Most production systems use both: agents reach tools over MCP and coordinate with each other over A2A or through an orchestrator. Taskade exposes a hosted MCP server and 34 built-in tools agents can call.
What is a message bus in multi-agent systems?
A message bus is a central system that receives messages from any agent and delivers them to the right recipient, like a post office. Agents publish messages to named topics and subscribe to the ones they care about, so they never need direct connections to each other. This decouples agents, scales to many subscribers, and gives you one place to audit every conversation, at the cost of an extra hop and a broker you must keep running. Buses fit best when many agents react to asynchronous events.
When should agents talk directly vs through an orchestrator?
Use an orchestrator (hub-and-spoke) for most workflows: it isolates context per agent, makes loops easy to detect at one chokepoint, and gives you a single aggregation point. Use direct A2A when latency matters and two agents collaborate tightly and repeatedly. Use a message bus when you have many agents, events arrive asynchronously, and you need durable delivery. Taskade defaults to orchestrated teams through Taskade EVE because it is the most reliable pattern in production.
Do AI agents need identity and authentication to talk to each other?
Yes. Before any agent accepts a message, it should verify who sent it and check what that sender is allowed to do. Without identity and permission checks, a compromised or misconfigured agent can issue instructions it should not have access to. This is least privilege applied to agents: each agent gets exactly the capabilities and conversation partners its role requires. A2A uses OIDC and JWT for this; Taskade inherits identity from workspace role-based access.
How do you prevent infinite loops between communicating agents?
Loops are the most common failure in inter-agent communication. Detection uses three signals: repeated identical messages, rising output similarity across turns, and token-budget overrun. When a loop is detected the system injects a corrective instruction, and if that fails it forces a summary exit so the user still gets partial useful output. Conversation-depth caps and message expiry add hard backstops. An orchestrator makes this easy because every message passes through one place.
Is A2A a single fixed standard?
A2A has a published specification under the Linux Foundation, but the broader agent-interoperability space is still consolidating across A2A, MCP, ACP, and ANP in 2026. The durable primitives are stable no matter which wire format wins: identity, capability discovery, structured messages, tracking IDs, and expiry. Build on those primitives so your system stays portable as the standards settle.
What is the difference between A2A, MCP, ACP, and ANP?
They sit at different layers. MCP connects agents to tools and data. A2A connects agents to other agents directly. ACP (Agent Communication Protocol, from IBM and the BeeAI community) is a REST-based protocol for multimodal agent messaging and orchestration. ANP (Agent Network Protocol) targets open, decentralized agent networks using decentralized identifiers (DIDs). Most systems combine MCP for tools with A2A or an orchestrator for coordination.
How does Taskade handle agent-to-agent communication?
Taskade orchestrates agent teams through Taskade EVE, the Taskade Genesis meta-agent. Taskade EVE breaks a request into sub-tasks, routes each to a specialist agent with its own isolated context, and aggregates the results. Agents can invoke other agents, call 34 built-in tools, and run across 15+ frontier models from OpenAI, Anthropic, Google, and open-weight providers. Three modes, Simple, Manual, and Orchestrate, let you choose how much coordination control you want, from one prompt to a fully directed multi-agent run.