






In 2024, a car dealership's customer-service chatbot agreed to sell a truck for one dollar. In countless other cases, a single planted instruction inside a web page or document quietly hijacked an agent into ignoring its rules. None of these were model failures, exactly. They were guardrail failures — the agent did precisely what it was asked, because nothing stood between the request and the action.
As AI agents move from demos to production — and as regulators set hard 2026 deadlines — guardrails have shifted from nice-to-have to non-negotiable. This is the vendor-neutral guide to what they are, the five layers that make up a real guardrail stack, and how to build them without overspending on theater.
TL;DR: AI guardrails are runtime controls that constrain what an agent reads, does, and says — distinct from evals, which measure quality offline. The standard is defense in depth across five layers: input guards, tool/action gating, output guards, human-in-the-loop approval, and evals as the feedback loop. EU AI Act transparency duties land August 2, 2026. Taskade applies this pattern with tool scoping, approval gates, and 7-tier roles built in.
What Are AI Guardrails?
AI guardrails are the enforcement layer that sits around a model, not inside it — runtime controls that decide what an agent is allowed to read, do, and say on every request. The model generates; the guardrails govern. They block a prompt-injection attempt before the model sees it, deny a tool call the agent shouldn't make, catch an ungrounded answer before it reaches a user, and pause a high-risk action for human approval.
This is fundamentally different from training a "safer" model. A model's behavior is probabilistic and can always be coaxed off-policy; guardrails are deterministic checks you control. They're the observability and safety layer of the AI agent stack — the part that turns an impressive agent into one you can actually run in production.
That diagram is the whole article. The rest explains each layer, the one distinction teams get wrong, and the regulatory clock now ticking behind all of it.
Guardrails vs. Evals: The Distinction Every Team Gets Wrong
Guardrails enforce policy at runtime; evals measure quality offline. Teams constantly conflate them, then wonder why a great eval score didn't prevent a production incident — or why guardrails didn't tell them whether the agent was actually good. They do different jobs, and you need both.
| Dimension | Guardrails | Evals |
|---|---|---|
| What they do | enforce policy live | measure quality |
| When they run | on every request, in production | offline, on test sets, before ship |
| Output | block / modify / approve | a score or grade |
| Failure they catch | unsafe or off-policy actions | regressions, low quality |
| Analogy | a seatbelt | a crash test |
The two form a loop: evals reveal where the agent fails, you tighten guardrails to prevent it, and guardrails generate the production signals that feed your next eval round. This post is the runtime-enforcement half; the agent evals guide is the offline-measurement half. NIST's AI Risk Management Framework even names this split — its Measure function is the offline counterpart to runtime enforcement.
The Full Guardrail Stack: 5 Layers
A real guardrail strategy is defense in depth — five independent layers, each catching what the others miss. OWASP recommends exactly this layered approach because no single control reliably stops a determined prompt-injection attack.
DEFENSE IN DEPTH — 5 LAYERS, EACH CATCHES WHAT THE LAST MISSES [1] Input guards → prompt-injection, PII, jailbreak filters
[2] Tool/action gate → least-privilege, allowlists, scoped creds
[3] Output guards → grounding, schema, content-safety checks
[4] Human approval → high-risk actions wait for a person
[5] Evals feedback → offline measurement tunes layers 1-4
No single layer is enough. The stack is the strategy.
| Layer | What it inspects | Blocks / modifies | Latency impact |
|---|---|---|---|
| 1 · Input guards | user request + retrieved content | injection, PII, jailbreaks | low–medium |
| 2 · Tool & action gating | which tools/actions the agent may use | unauthorized calls | low |
| 3 · Output guards | the agent's draft answer / tool args | hallucination, schema, unsafe content | medium |
| 4 · Human approval | high-risk actions | anything irreversible/external | high (waits for human) |
| 5 · Evals feedback | offline test sets | (tunes the other layers) | none (offline) |
Layer 1 — Input guards
Input guards inspect everything coming into the agent — the user's message and any retrieved or external content — to block prompt injection, jailbreaks, and sensitive data before the model acts. This matters because OWASP ranks Prompt Injection as LLM01:2025, the #1 LLM risk for the second consecutive edition, precisely because models process instructions and data in the same channel. A core technique OWASP recommends: segregate untrusted external content so a planted instruction in a web page or document can't be treated as a command.
Layer 2 — Tool and action gating
Tool gating enforces least privilege — an agent should only have access to the specific tools and actions its job requires. If an agent can only read calendars, a hijack can't drain a bank account. This is the highest-leverage, lowest-cost guardrail: scope the tools an agent has, use allowlists, and give each tool narrowly-scoped credentials. When agents reach external systems via MCP, the same principle applies to every connected server.
Layer 3 — Output guards
Output guards inspect what the agent produces before it reaches the user — checking for hallucination and grounding, validating against an expected schema, screening unsafe content, and preventing data leaks. OWASP's advice: define and validate expected output formats with deterministic code, so a malformed or off-policy response is caught mechanically, not left to chance.
Layer 4 — Human-in-the-loop approval
For high-risk actions, the right guardrail is a person. The agent drafts the action, the system pauses at an approval gate, and execution happens only after someone with the right permission signs off. OWASP explicitly recommends requiring human approval for high-risk actions and human-in-the-loop controls for privileged operations. Reserve it for the irreversible and the externally-visible — sending money, deleting data, emailing customers, posting publicly.
Layer 5 — Evals as the feedback loop
Evals are the offline measurement that tunes the other four layers. They tell you whether your guardrails are too loose (incidents slip through) or too tight (false positives frustrate users), and they catch quality regressions before you ship. Without this layer, you're flying blind on whether your guardrails actually work. (Deep dive: agent evals explained.)
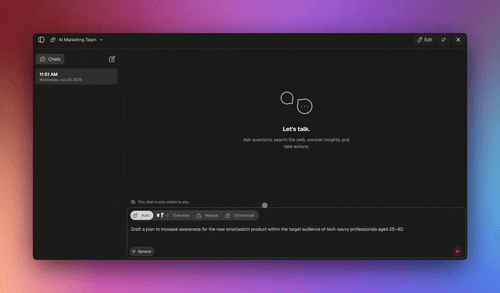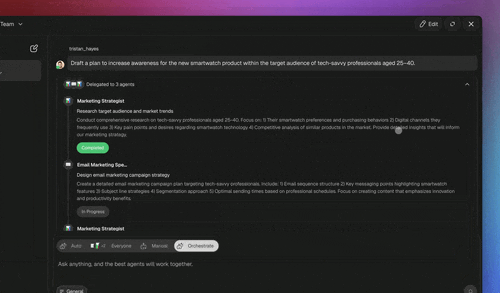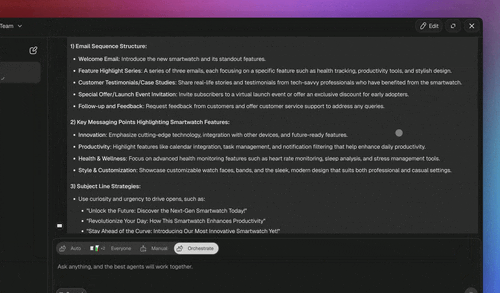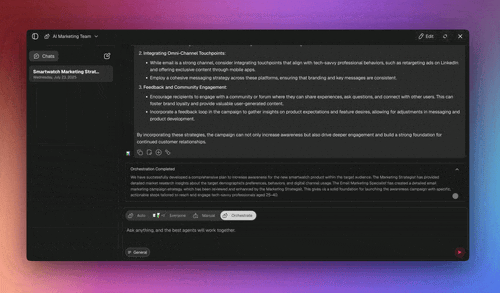
Which Guardrail for Which Risk?
Different risks need different layers — mapping them prevents both gaps and wasted effort. Here's how the most common agent risks map to the layer that catches them.
| Risk | Example attack | Primary guard layer | Human approval? |
|---|---|---|---|
| Prompt injection (LLM01) | planted instruction in a doc | input guards + tool gating | for privileged ops |
| Sensitive-data leak | agent echoes PII | input + output guards | no |
| Excessive agency | agent deletes records | tool/action gating | yes |
| Hallucinated output | confident wrong answer | output guards (grounding) | for high-stakes |
| Unsafe content | toxic / disallowed text | output guards | no |
| Irreversible action | sends payment, emails all | human approval gate | yes |
The Real Trade-Offs Nobody Mentions
Guardrails aren't free — each layer adds latency and can produce false positives, and more isn't always better. The honest engineering question is how much defense for which actions.
The falling line is residual risk; the rising line is added latency. The lesson isn't "max out all layers" — it's calibrate. The OpenAI Agents SDK makes the trade-off concrete: input guardrails can run in parallel mode (lower latency, but the agent may consume some tokens before a tripwire fires) or blocking mode (the guard completes first — safer, slower). Use blocking and full layering for irreversible actions; use lighter, parallel checks for low-risk, high-volume requests.
| Knob | Tighten effect | Loosen effect | Recommended default |
|---|---|---|---|
| Number of layers | safer, slower | faster, riskier | full stack on high-risk actions |
| Block vs. parallel | safer, higher latency | faster, some exposure | block for high-risk, parallel otherwise |
| Approval threshold | fewer incidents, more friction | smoother, riskier | approve irreversible/external only |
| Output strictness | fewer bad outputs, more false positives | fewer false positives, more risk | strict schema on tool args |
The 2026 Tooling Landscape
Several mature, open-source guardrail toolkits exist in 2026, each taking a different approach. Naming them is education — pick by how they fit your stack.
| Tool | License | Guard types | Distinctive feature | Best for |
|---|---|---|---|---|
| NeMo Guardrails | Apache 2.0 | input, dialog, retrieval, execution, output | five rail types incl. dialog rails | conversational flows |
| Guardrails AI | Apache 2.0 | validators (PII, toxicity, hallucination, bias) | Hub of 50+ pre-built validators | output validation |
| OpenAI Agents SDK | open-source | input + output guardrails | tripwire halts execution | agent pipelines |
NVIDIA's NeMo Guardrails offers five rail types — input, dialog, retrieval, execution, and output. Guardrails AI ships a Hub of 50+ pre-built validators for PII, toxicity, hallucination, bias, and profanity. The OpenAI Agents SDK splits guardrails into input guardrails (run on user input) and output guardrails (run on the final output) — usefully read as protecting the agent from users and users from the agent — with a triggered guardrail raising a tripwire exception that immediately halts execution.
The 2026 Regulatory Hook
Guardrails are how you operationalize concrete legal duties that arrive in 2026 — this is no longer just engineering hygiene. Two frameworks matter most.
| Requirement | Source / date | Concrete guardrail pattern | Layer |
|---|---|---|---|
| AI-interaction transparency | EU AI Act Art. 50, applies Aug 2, 2026 | disclose users are talking to AI | output / UX |
| Risk management functions | NIST AI RMF (Govern, Map, Measure, Manage) | document, gate, measure, monitor | all layers |
| GenAI risk areas | NIST-AI-600-1, July 26, 2024 | map 12 GenAI risks to controls | input/output |
The key dates: most of the EU AI Act begins to apply on August 2, 2026, including Article 50 transparency obligations to disclose when users are interacting with AI. While the 2026 Digital Omnibus proposal would defer some high-risk obligations (to late 2027 and 2028), the Article 50 transparency duties stay on the August 2, 2026 schedule. NIST's AI RMF — with its four functions Govern, Map, Measure, Manage — and the GenAI Profile (200+ suggested actions across 12 risk areas) give you the framework to operationalize this. A caution: guardrails help you meet these obligations; no tool grants automatic "compliance."
How Taskade Implements Guardrails for AI Agents
Taskade applies the same defense-in-depth pattern the industry and regulators recommend — as configuration, not a custom build. The point isn't that Taskade invented agent safety; it's that the standard guardrail layers come built into how you set up an AI agent.
- Tool / action gating (Layer 2): agents ship with 34 built-in tools, and you scope which ones each agent can use — least privilege becomes a setting, not a coding project.
- Human-in-the-loop (Layer 4): high-risk agent actions can require human approval before they run, matching OWASP's "require human approval for high-risk actions."
- Role-based control: Taskade's 7-tier roles (Owner to Viewer) gate who can change an agent's configuration and who can approve its actions — an org-level guardrail on top of the runtime ones.
- Visibility and access: agent runs are team-visible, and apps support password protection and built-in user accounts, so you control who can see and do what.
To be accurate about scope: these are sensible, standard controls that let you ship guarded agents without assembling a separate guardrail stack — not a compliance certification or a guarantee of safety. Pair them with evals for the offline half of the loop, and you have the runtime-plus-measurement combination the agent stack calls for. It's the same build-it-for-you philosophy as Taskade Genesis: the standard architecture, assembled so you can focus on the work.
A Reference Architecture: All Five Layers Together
Putting it together, here's the lifecycle of a single guarded agent run — every request passing through the layers, with the tripwire and approval paths that short-circuit it.
Frequently Asked Questions About AI Guardrails
What are AI guardrails in simple terms?
They're runtime controls around a model that constrain what an agent can read, do, and say. They check inputs (blocking injection or PII), gate which tools an agent can use, validate outputs (catching ungrounded or unsafe responses), and route high-risk actions to human approval. Guardrails enforce policy live, on every request — not after the fact.
What is the difference between guardrails and evals?
Guardrails are runtime enforcement; evals are offline measurement. A guardrail blocks or modifies a live request; an eval scores quality on test cases before you ship. They loop: evals reveal weaknesses you fix with guardrails, and guardrails produce signals that feed the next eval round. You need both.
Are input guards and output guards the same thing?
No. Input guards inspect what comes in (user request, retrieved content) to block injection, jailbreaks, and sensitive data. Output guards inspect what the agent produces to catch hallucinations, schema violations, and leaks. A useful framing of the OpenAI Agents SDK's input-vs-output split: input guards protect the agent from users, and output guards protect users from the agent.
How do guardrails stop prompt injection?
Prompt injection is OWASP's #1 LLM risk because models mix instructions and data in one channel. Guardrails use defense in depth: input filtering, segregating untrusted external content so it can't act as commands, least-privilege tool access so a hijacked agent can do little, and human approval for high-risk actions. The layered stack is the defense, not any single check.
When should an AI agent require human-in-the-loop approval?
For any action that's hard to reverse, externally visible, or high-impact — sending money, deleting data, emailing customers, posting publicly, or changing production. OWASP recommends human approval for high-risk and privileged operations. Let the agent draft, pause at an approval gate, and execute only after a permitted person signs off.
Do guardrails add latency, and how much?
Yes — each layer adds a check. Input and output guards add steps around the model run. The OpenAI Agents SDK lets input guardrails run in parallel (lower latency, some token exposure before a tripwire) or blocking (completes first, safer, slower). Tune layer count and mode to your risk and latency budget.
What is the difference between blocking and parallel guardrails?
It's about timing. Blocking mode runs the guard before the agent starts — nothing unsafe executes, but you wait. Parallel mode (an OpenAI Agents SDK option) runs the guard alongside the agent for lower latency, accepting that the agent may use some tokens before a tripwire halts it. Block for high-risk; parallelize where speed matters.
What open-source AI guardrail tools exist in 2026?
Several. NVIDIA NeMo Guardrails (Apache 2.0) has five rail types: input, dialog, retrieval, execution, output. Guardrails AI (Apache 2.0) offers a Hub of 50+ validators for PII, toxicity, hallucination, and bias. The OpenAI Agents SDK has built-in input/output guardrails with tripwires that halt execution. Match the tool to your stack.
Does the EU AI Act require AI guardrails?
It creates duties guardrails help you meet. Most of the Act applies August 2, 2026, including Article 50 transparency (disclosing AI interaction). Some high-risk obligations were proposed for deferral under the 2026 Digital Omnibus, but Article 50 transparency stays on the August 2, 2026 schedule. Guardrails are how you operationalize these duties.
Can guardrails guarantee an AI agent is safe?
No. They reduce risk substantially but can't guarantee safety — models are non-deterministic and attackers adapt. The standard is defense in depth plus evals for measurement and human oversight for high-risk actions. Treat guardrails as risk reduction and monitoring, not a one-time guarantee. Guaranteed AI safety is overselling.
What is defense-in-depth for AI agents?
Stacking multiple independent guardrail layers so that if one fails, others still catch the problem — typically five: input guards, tool/action gating, output guards, human approval for high-risk actions, and evals as the feedback loop. OWASP recommends this layered approach for prompt injection because no single control is reliable alone.
How does Taskade handle guardrails for AI agents?
Taskade applies the industry's defense-in-depth pattern as configuration: you scope which of the 34 built-in tools an agent can use (least privilege), high-risk actions can require human approval, and 7-tier roles (Owner to Viewer) control who configures agents and approves actions. Runs are team-visible, and apps support password protection and built-in user accounts — guarded agents without a separate stack.
The uncomfortable truth about AI agents is that capability and safety are separate problems. A more capable model doesn't make a safer agent — guardrails do. The teams that ship agents into production in 2026 won't be the ones with the smartest model; they'll be the ones whose agents can't do the wrong thing even when asked. That's not a model property. It's an architecture choice.
That's the safety layer of the stack: Memory feeds context, Intelligence reasons, Execution acts — and guardrails watch every pass of the loop. ▲ ■ ●
Want guarded agents without assembling the stack? Start free with Taskade, scope your AI agents with the right tools and approvals, and wire them into automations.