






"Multi-agent AI" stopped meaning one thing in 2026.
It can mean a Python class in CrewAI. A visual graph in Lindy. A custom GPT chain in ChatGPT Teams. A LangGraph DAG in production. These are all "multi-agent", and they share almost no infrastructure.
For a team buying a platform, the question isn't which is "best". It's which collapses the most of the org chart while leaving the parts that matter to humans alone.
TL;DR: Eight production multi-agent platforms compared on the seven capabilities that actually matter for teams, shared memory, human co-edit, native automations, role-based access, bidirectional MCP, clone-as-team, and time-to-first-team. Taskade Genesis is the only one that passes all seven. Clone any of 78 live agent apps to see the workspace-native pattern firsthand.
The Three Buckets of "Multi-Agent" in 2026
In 2026, every multi-agent buyer faces three distinct platform categories. Frameworks ship Python primitives. Visual builders ship drag-and-drop flows. Workspace-native platforms ship a workspace that agents live inside. Picking the wrong bucket is the most expensive mistake a team can make in the AI-tools budget.
┌────────────────────────────────────────────────────────────────────────┐
│ Three buckets, three buyer profiles │
├────────────────────────────────────────────────────────────────────────┤
│ Frameworks For engineering-led teams who want bespoke │
│ orchestration — accept 10-14 day setup cost. │
│ CrewAI · AutoGen · LangGraph │
│ ───────── │
│ Visual Builders For ops-led teams who want one agent in 2-4 hours, │
│ and accept that the agents stay siloed. │
│ Lindy · Dust · Relevance AI · Flowise │
│ ───────── │
│ Workspace-Native For teams who want a 3-agent team with shared │
│ memory and automations running in 30 minutes. │
│ Taskade Genesis (canonical implementation) │
└────────────────────────────────────────────────────────────────────────┘
The Seven Capabilities That Actually Matter
Every team buying a multi-agent platform in 2026 should ask seven questions. The answers separate the workspace-native one from the rest.
| # | Capability | Why It Matters |
|---|---|---|
| 1 | Shared persistent memory | Without it, every agent re-primes context every run |
| 2 | Real-time human-agent co-edit | Without it, humans poll Slack for outputs |
| 3 | Native automation triggers | Without it, you write webhook glue forever |
| 4 | Workspace-scoped RBAC | Without it, you cannot give agents the same permissions as humans |
| 5 | Bidirectional MCP | Without it, you are either a server or a client, not both |
| 6 | Clone-as-team | Without it, you cannot share a working agent stack |
| 7 | Time-to-first-team | Without it, you cannot ship before the budget closes |
The Eight Platforms, Scored
1. Taskade Genesis: Workspace-Native (all 7 pass) ★
The only platform that passes all seven capabilities. Workspace DNA, Memory + Intelligence + Execution, is the connective tissue. Agents live in real Projects, share persistent memory by default, co-edit with humans in real time, and trigger automations natively. Clone an entire team in one click from the 78-app library.
Best for: Teams shipping in days, not weeks. Operators who want a working stack, not a coding project. Anyone replacing the operational middle layer of their org chart.
2. Lindy: Visual Builder
Strong single-agent UX. Drag-and-drop visual builder. Each agent is its own world. Team coherence, multiple agents sharing context, handing off work, seeing each other's outputs, requires manual Slack relay.
Best for: Solo operators with one specific workflow to automate. Not for teams.
3. Dust: Workspace-Aware Chat
Closest to workspace-native among the visual-builder cohort. Multi-LLM, multi-assistant, workspace data sources. Missing the execution layer, no native automation triggers. Read-mostly.
Best for: Knowledge-heavy enterprises that want an LLM on top of their docs.
4. Relevance AI: Visual Builder + Tools
Strong tool wiring. Per-agent memory (not team-shared). Good template library. No real-time human-agent co-edit.
Best for: Teams that want one well-wired agent and are okay deploying it standalone.
5. CrewAI: Python Framework
The most ergonomic of the three major frameworks. Roles, tasks, crews. Excellent for engineering-led teams who want full control. Plan for 10 to 14 days to ship a production team with hosting, memory, UI, and RBAC all DIY.
Best for: Engineering-led teams with a custom orchestration need outside a standard workspace.
6. AutoGen: Microsoft Research Framework
Powerful for experimentation and research. Group chat patterns are sophisticated. No UI, no RBAC. Plan for 7 to 10 days.
Best for: AI research teams and prototype work.
7. LangGraph: Production Framework
Best for stateful production graphs. Steep learning curve (10 to 14 days). Excellent observability via LangSmith. No native multi-tenant workspace.
Best for: Engineering-led teams shipping a stateful agent backend behind their own UI.
8. Claude Projects / ChatGPT Teams: Chat Multi-Agent
Chat threads scoped to documents. Shared context per project. Zero execution layer, cannot trigger HubSpot writes, cannot post to Slack, cannot update a CRM. By design.
Best for: Q&A over a corpus. Not what the rest of the industry means by "multi-agent."
Deep Dive: What Each Platform Actually Costs to Run
The "free framework" framing hides operational cost. Here is what shipping a 3-agent production team actually costs across the eight options once you add hosting, models, observability, and engineering time.
| Platform | Software cost | Hosting | Model spend (3 agents, mod use) | Eng. time to ship | True 90-day cost (est.) |
|---|---|---|---|---|---|
| Taskade Genesis (Business) | $40/mo | bundled | $0 (15+ models included up to plan limit) | 30 min operator | ~$120 / 90d |
| Lindy Pro | $49/mo | bundled | bundled credit pool | 2-4 h × 3 agents | ~$200 / 90d (incl. operator hours) |
| Dust Pro | $29/user/mo | bundled | bundled credit pool | 1 day | ~$300 / 90d (3 users) |
| Relevance AI Team | $39/user/mo | bundled | bundled | 1.5 day | ~$400 / 90d |
| CrewAI (self-host) | $0 framework | Fly.io / Render ~$50/mo | OpenAI ~$200-400/mo | 10-14 day eng × $150/h = ~$15K | ~$16K / 90d |
| AutoGen (self-host) | $0 framework | $50/mo | $200-400/mo | 7-10 day eng | ~$11K / 90d |
| LangGraph (self-host) | $0 framework | $50/mo + LangSmith $39 | $200-400/mo | 10-14 day eng | ~$16K / 90d |
| ChatGPT Teams | $30/user/mo | bundled | bundled | minutes | ~$270 / 90d (3 users) — but no execution |
The math flips the picture. Workspace-native is the cheapest production stack when you count engineering time honestly, and engineering time is the dominant cost for everyone except the operator-led Taskade path.
Per-Platform Verdict (Honest Long-Form)
CrewAI: The Ergonomic Framework
CrewAI shipped the cleanest role/task abstraction of the framework cohort. Define roles, define tasks, instantiate a Crew, run. Excellent docs. Strong community. Has a hosted "CrewAI Enterprise" tier as of 2026 but the core remains a Python framework.
Where CrewAI wins: engineering-led teams who want full control of orchestration and don't need a UI. Research teams. Backend agent services.
Where CrewAI loses: No UI, no workspace, no real-time co-edit, no native automations beyond what you wire. The "Enterprise" tier closes some gaps but at framework-grade pricing without workspace-grade benefits.
Honest takeaway: If you have engineers and want primitives, CrewAI is excellent. If you have operators and want a working team, CrewAI is the wrong starting point.
AutoGen: Microsoft Research's Group-Chat Bet
AutoGen ships sophisticated multi-agent group-chat patterns out of Microsoft Research. Excellent for experimentation. Best-in-class for "what happens when agents argue with each other" research.
Where AutoGen wins: Research labs. Prototype work. Multi-agent dialogue patterns. Microsoft-ecosystem teams.
Where AutoGen loses: No UI, no RBAC, no native triggers. Production hardening is DIY.
LangGraph: The Stateful Production Bet
LangGraph is the answer when you need a stateful agent graph in production with observability. LangSmith integration is excellent. The graph abstraction is more powerful than CrewAI's role abstraction for complex flows.
Where LangGraph wins: Engineering teams shipping stateful backends behind their own UI. Complex orchestration that needs explicit state.
Where LangGraph loses: Steep learning curve (10–14 days). Still no UI, no RBAC, no workspace. The graph design itself is a multi-week project for non-trivial cases.
Lindy: The Solo-Agent Visual Builder
Lindy ships the strongest single-agent visual UX in the visual-builder cohort. Drag-and-drop. Strong template library. Polished onboarding.
Where Lindy wins: Solo operators with one specific workflow. SMB inbound automation. Polished UI for non-developers.
Where Lindy loses: Each agent is its own world. Team coherence, multiple agents sharing memory, handing off work, requires Slack relay. No clone-as-team. No bidirectional MCP.
Dust: The Workspace-Aware Chat Bet
Dust is the closest non-Taskade option to workspace-native. Multi-LLM, workspace data sources, multiple assistants. Recent funding round signals enterprise traction.
Where Dust wins: Knowledge-heavy enterprises with engineering buyers. Strong on the chat-over-corpus axis.
Where Dust loses: Read-mostly. No execution layer, no native automation triggers. No clone-as-team. No bidirectional MCP at scale.
Relevance AI: The Tool-Wired Visual Builder
Relevance AI ships strong per-agent tool wiring with a clean visual builder. Good template library. Solid enterprise SSO.
Where Relevance AI wins: Single-agent deployments with rich tool needs.
Where Relevance AI loses: Per-agent memory (not team-shared). No real-time human-agent co-edit. No clone-as-team.
ChatGPT Teams + Claude Projects: Read-Mostly Chat
ChatGPT Teams and Claude Projects ship chat scoped to projects. Excellent reading experiences. Project memory works well. Not multi-agent in the operational sense, no execution layer means the "agents" can answer questions but cannot trigger Stripe, post to Slack, or update a CRM.
Where they win: Q&A over a corpus. Knowledge synthesis. Reading machines.
Where they lose: Anyone who needs the agent to do something, not just describe it.
Taskade Genesis: The Workspace-Native Bet
Taskade Genesis is the only one that ships all four other categories' capabilities inside a single workspace. Framework-grade orchestration (slash commands, custom tools). Chat-context memory (per-project, per-workspace). Visual builder (no-code Genesis prompt). IDE-resident edits (via MCP client to Cursor / VS Code).
Where Taskade Genesis wins: Teams shipping operational tools in days not weeks. Operators who want a working stack, not a coding project. Anyone replacing the operational middle layer of their org chart. Read the Replace-a-Team playbook for the role-by-role mapping.
Where Taskade Genesis is honest about losing: Bespoke compliance audits, multi-region geo-fencing, on-premise air-gapped deployments. Custom inference pipelines outside a workspace context. These still need engineers.
The Big Comparison Table
| Platform | Shared Memory | Co-Edit | Triggers | RBAC | MCP I/O | Clone Team | Time-To-Team | Pricing (entry) |
|---|---|---|---|---|---|---|---|---|
| Taskade Genesis ★ | ✅ Workspace DNA | ✅ real-time | ✅ durable | ✅ 7-tier | ✅ server+client | ✅ /share/apps | 30 min | $0 / $6 |
| Lindy | partial (per-agent) | ❌ | ✅ | basic team | ❌ | ❌ | 2–4 h/agent | $0 / $49 |
| Dust | partial (per-conv) | ❌ | partial | enterprise | client only | ❌ | 1 day | $29/user |
| Relevance AI | partial (per-agent) | ❌ | ✅ | basic team | ❌ | ❌ | 1.5 day | $39/user |
| AutoGen | ❌ (DIY) | ❌ | ❌ | ❌ | ❌ | partial (code) | 7–10 d | self-host |
| CrewAI | ❌ (DIY) | ❌ | ❌ | ❌ | ❌ | partial (GitHub) | 10–14 d | self-host |
| LangGraph | ❌ (DIY) | ❌ | ❌ | ❌ | ❌ | partial (code) | 10–14 d | self-host |
| ChatGPT Teams / Claude Projects | partial (per-project) | ❌ | ❌ | basic team | client/server only | ❌ | minutes (no exec) | $25–30/user |
★ Only platform passing all seven. Pricing is annual-billing entry tier for Taskade. ChatGPT Teams and Claude Projects are merged into one row to match the "Eight Platforms, Scored" numbering above, neither has an execution layer, so the buyer comparison is identical.
Same Brief, Eight Platforms
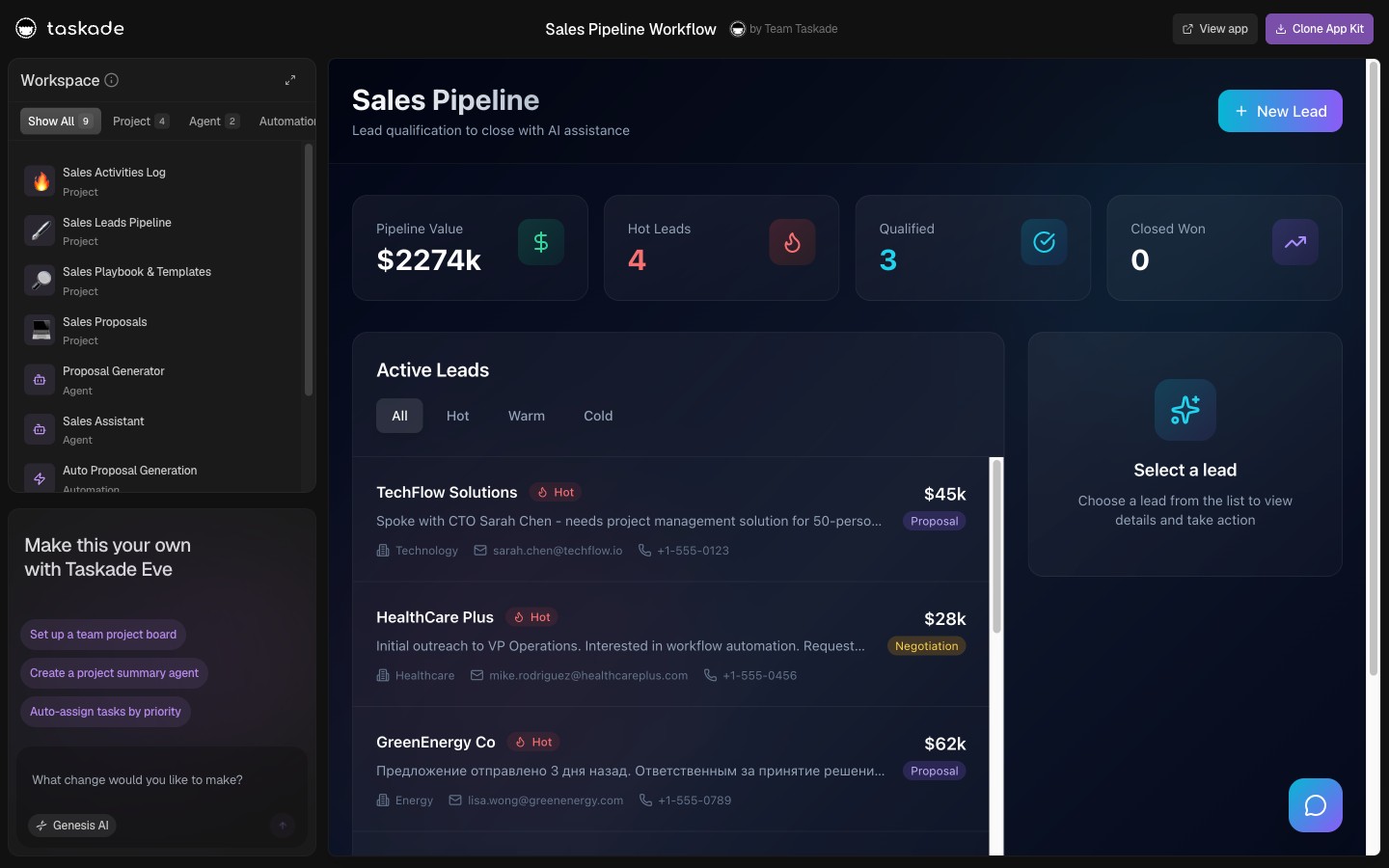
The buyer scenario: Build a Sales SDR agent + a Research agent + a CRM-update agent that all share customer context.
| Platform | Setup steps | Time | What you ship | What breaks |
|---|---|---|---|---|
| Taskade Genesis | Open Project · /agent × 3 · wire Slack + HubSpot · publish |
30 min | Live cloneable 3-agent team with shared memory + automations | nothing at this scope |
| Lindy | Sign up · build agent 1 · build agent 2 separately · Slack-relay between them | 4 h | Three separate agents, Slack-glued | losing context across agents = manual re-prime |
| Dust | Create workspace · build assistant · attach data sources · build second assistant | 1 day | Two assistants reading same data | no native trigger — external orchestration needed |
| Relevance AI | Sign up · build agent 1 · wire tools · build agent 2 separately · share state via webhook | 1.5 day | Two tool-wired agents, no shared memory | per-agent memory only — context drift |
| CrewAI | pip install crewai · define 3 roles · write tasks.py · wire memory · host · build UI · add auth |
10–14 d | A working backend, no UI | every step DIY |
| AutoGen | similar to CrewAI | 7–10 d | research-grade demo | no production hardening |
| LangGraph | similar to CrewAI + graph design | 10–14 d | stateful production graph | no UI, no RBAC |
| ChatGPT Teams / Claude Projects | Buy seats · create custom GPTs or Claude Projects · hope they share project data | minutes | Three GPTs/projects scoped to a corpus | cannot trigger HubSpot writes; no execution layer |
How Agent-to-Agent Handoff Actually Works (Workspace-Native)
In a workspace-native platform, the three agents see each other's outputs the moment they happen because they all read the same Workspace Memory. In a framework, the developer wires this manually, vector store, retrieval logic, output formatting, scheduling. In a chat tool, this loop doesn't exist at all.
Time-to-First-Team (The 30-Minute Bar)
The chart reads 0.02 days for Taskade. That's thirty minutes. The chart reads 0.03 days for ChatGPT Teams. But the result has no execution layer, so it's not directly comparable.
Decision Matrix
┌──────────────────────┐
│ Do you ship in days │
│ or weeks? │
└──────────┬───────────┘
│
┌───────────────┼───────────────┐
│ days │ │ weeks
▼ ▼
┌──────────────────────┐ ┌──────────────────────┐
│ Visual or workspace? │ │ Framework comfort? │
└──────────┬───────────┘ └──────────┬───────────┘
│ │
┌──────┼──────┐ ┌──────┼──────┐
│ │ │ │
▼ ▼ ▼ ▼
Lindy Taskade CrewAI LangGraph
(single) (team) (Python) (production)
How Workspace DNA Powers Multi-Agent
┌────────────────────────────────────────────────────────────────────────┐
│ Workspace DNA Loop │
│ │
│ ▲ MEMORY ─────► ■ INTELLIGENCE ─────► ● EXECUTION │
│ ▲ │ │
│ └──────────────────────────────────────────┘ │
│ │
│ Projects · Agents v2 (34 tools) · Automations (100+ integrations) │
│ All agents share the SAME memory in the same workspace. │
└────────────────────────────────────────────────────────────────────────┘
Workspace DNA is the reason workspace-native passes the seven-test bar by default. Read the full criteria in the canonical workspace-native essay.
A Live Multi-Agent Team You Can Clone in 60 Seconds
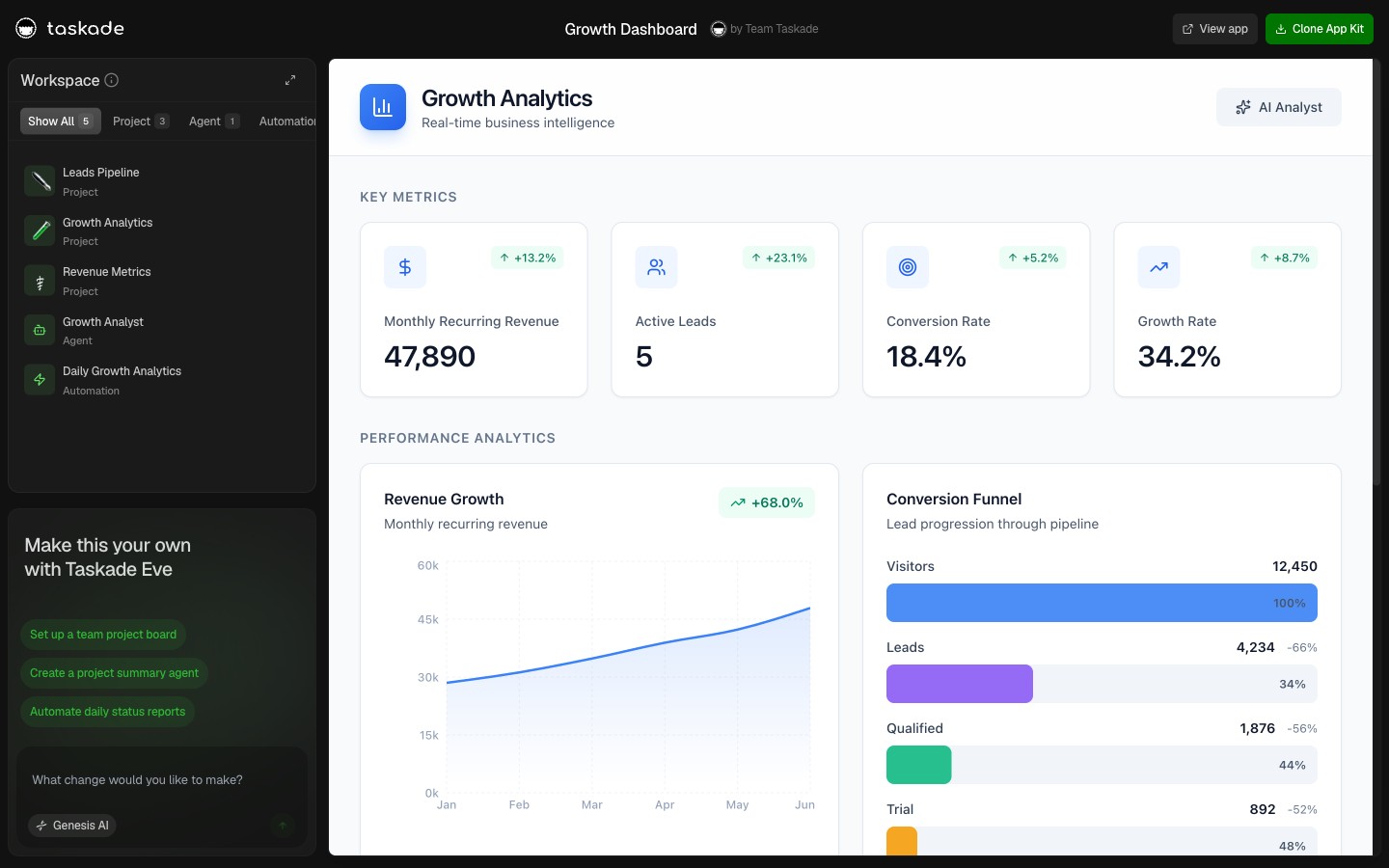
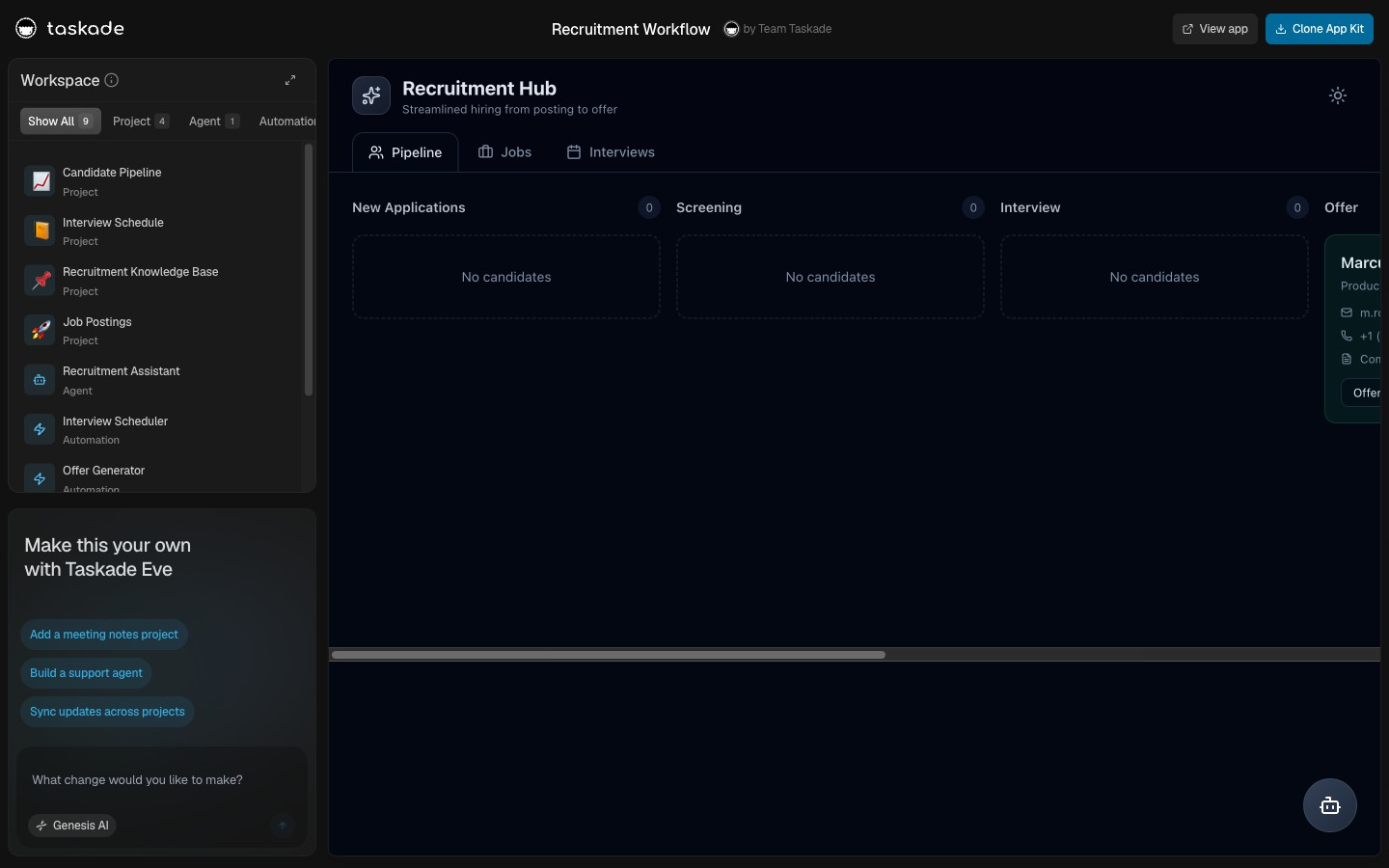
Each app is a working agent team. Each clone is one click.
Frequently Asked Questions
What is a multi-agent AI platform?
Software that lets specialized AI agents collaborate, delegate, and share memory to complete workflows. A sales agent hands off to a marketing agent without human relay. The leading 2026 platforms are CrewAI, AutoGen, LangGraph (frameworks); Lindy, Dust, Relevance AI (visual builders); and Taskade Genesis (workspace-native).
What is the difference between a framework and a workspace-native platform?
Frameworks give you Python primitives. You build the rest (hosting, memory, UI, RBAC). Workspace-native ships with all of it built in. Ten to fourteen days versus thirty minutes for the same outcome.
Which platforms have built-in shared memory?
Taskade Genesis (Workspace DNA, all agents share it). Dust offers per-conversation memory. CrewAI / AutoGen / LangGraph require manual wiring. Lindy and Relevance AI offer per-agent memory but not team-shared.
Which is the best multi-agent platform for non-developers?
Taskade Genesis for workspace-native. Lindy as the strongest visual builder. The frameworks all require Python.
Can multi-agent platforms be cloned as a team?
Most cannot. CrewAI ships GitHub repos. AutoGen ships Python. Taskade Genesis ships running cloneable workspaces at /share/apps/*.
Do multi-agent platforms support MCP?
Taskade Genesis is the only major platform supporting both inbound and outbound MCP. Most are one-direction.
Which platform has the lowest time-to-first-team?
Taskade Genesis at thirty minutes for a 3-agent team with shared memory plus automations plus RBAC.
How do multi-agent platforms handle human-agent collaboration?
Most relay via Slack. Workspace-native lets humans and agents co-edit projects in real time.
What does pricing look like?
Frameworks are free but you pay for hosting and models. Hosted platforms run $29–$49 per user per month. Taskade Genesis annual pricing: Free, Starter $6, Pro $16, Business $40, Max $200, Enterprise $400.
Which platforms have RBAC for mixed human-agent teams?
Rare. Taskade Genesis offers 7-tier role-based access at workspace scope for both humans and agents.
▲ ■ ● Memory · Intelligence · Execution, the workspace is the platform; the platform is the multi-agent team.
Try Taskade Genesis free → · Read the workspace-native authority post → · Browse 78 cloneable agent apps →