





In June 2025, Andrej Karpathy reposted a tweet with one line: +1 for "context engineering" over "prompt engineering." By March 2026, Gartner reported a 1,445% surge in agentic and context inquiries. A new discipline had a name. By April 2026, the conversation moved on again — from how to fill the context window to what to do with multiple parallel ones. Cursor 3 shipped the Agents Window. Windsurf Wave 13 brought first-class parallel worktrees. OpenAI Codex v2 went multi-agent. Google Research published ReasoningBank showing +8.3% on WebArena and +4.6% on SWE-Bench-Verified. The 2025 Nobel Prize in Physics had just been awarded for the first chip-scale demonstration of quantum tunneling on a Josephson junction. The industry-and-physics signal converged in 90 days: parallel branches, phased to interfere, are the architecture.
This post is about that next move. It is the engineering deep-dive on interference merge — the architecture that lets N parallel AI agents reason in superposition and converge through structural diff into a single committed app, with the divergences surfaced as user-facing questions and the outliers discarded.
If Workspace DNA was the substrate that made context engineering shippable as a product, interference merge is what you do with it once it's shipped.
TL;DR: Interference merge runs N parallel agents on the same prompt, then structurally diffs their outputs — invariants commit, divergences become user questions, outliers discard. Only Taskade Genesis Quantum ships this on Workspace DNA primitives, because text-based code generators have no stable merge alphabet. 150,000+ apps live.
🧩 What Multi-Agent Means Today (and Why Most Of It Is Sequential)
The 2025 wave of "multi-agent" AI systems has been remarkably homogeneous. Almost all of them are sequential pipelines in disguise:
USER ─► planner agent ─► coder agent ─► reviewer agent ─► output
▲ ▼
one branch, no parallelism, single point of failure
LangGraph defaults to this shape. CrewAI defaults to this shape. AutoGen has parallel capability but most production deployments serialize. Cursor's "background agents" are parallel from the user's perspective but each agent is single-branch.
A second pattern, best-of-N, did spread in 2024–2025:
┌─► agent_α ─┐
USER ─► split ──┼─► agent_β ─┼─► picker ─► output
└─► agent_γ ─┘ ▲
(other N-1 thrown away)
OpenAI's o1-pro effectively ships this — N parallel reasoning traces, picked by an internal judge. Cursor's "tab competition" ships a UX version of this. The cost is N×; the quality lift over single-shot is real (~10–25% on benchmarks); the waste is also real (N-1 candidates discarded).
The pattern almost nobody is shipping in production — and the one we will spend the rest of this post on — is interference merge:
┌─► agent_α ─┐ ─── invariants ───
│ │ │ (≥ all agree) │ ──► commit
USER ─► split ──┼─► agent_β ─┼──►├── divergences ──┤ ──► Ask-Questions(user)
│ │ │ (some agree) │
└─► agent_γ ─┘ ─── outliers ───── ──► discard
▲
STRUCTURAL DIFF
on Workspace DNA
(Project · Agent · Automation · Interface)
The rest of this post is a deep dive on why this third pattern is the moat-shaped one — and why only Taskade Genesis can ship it.
🏗️ The Five Components of Interference Merge
Multi-agent interference merge decomposes into five components — a fan-out orchestrator that spins N parallel agents, isolated branch sandboxes that prevent decoherence, a structural normalizer that types each branch's output, a cross-branch intersector that bins records into invariants / divergences / outliers, and an Ask-Questions tool integration that surfaces divergences to the user. Each component reuses Taskade infrastructure that already exists.
1. Fan-out orchestrator
Wrap your single-agent loop in N parallel calls. The naive version is a Promise.all([...]). The non-naive version respects:
- Per-branch temperature variation so branches actually diverge (
temperature = base + 0.1 × i) - Shared cache prefix so the system prompt and read-side context aren't duplicated N times (use
cacheControl: { type: 'ephemeral' }if your provider supports it) - Per-branch timeout at ~1.3× single-branch p95 — slow branches get dropped rather than blocking the merge
- Telemetry per branch — duration, tool calls, credits, workspace-write count
Without all four, fan-out either costs N× too much or produces N identical branches with no information yield.
2. Branch-isolated sandbox (the cryogenic chamber)
This is the most important component and the hardest to build. If branches share write access to the same workspace, they decohere each other. One branch creates /projects/contacts.taskade; the second branch's parallel write either races or overwrites; the user sees a half-built app mutating mid-flight; the merge layer can't tell which version came from which branch.
The fix: per-branch sandbox. Each branch reads from the source workspace but writes to its own in-memory overlay. The overlays are diffed at the end. The user's real workspace is untouched until the merge commits.
ASCII view of the isolation pattern:
source workspace
(read-only during fanout)
│
┌────────────────────┼────────────────────┐
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ branch_α │ │ branch_β │ │ branch_γ │
│ overlay │ │ overlay │ │ overlay │
│ (writes go │ │ (writes go │ │ (writes go │
│ here) │ │ here) │ │ here) │
└──────────────┘ └──────────────┘ └──────────────┘
│
merge layer reads
all 3 overlays + source
│
▼
chosen invariants commit
to source workspace once
This builds on the install path that already powers Taskade Genesis app import, export, and clone — sandboxes inherit it for free. The branched subsystem is bounded: overlays cap at ~1 MB per branch, slow branches get dropped, and the entire fan-out aborts if the workspace state changes mid-flight.
3. Structural normalizer
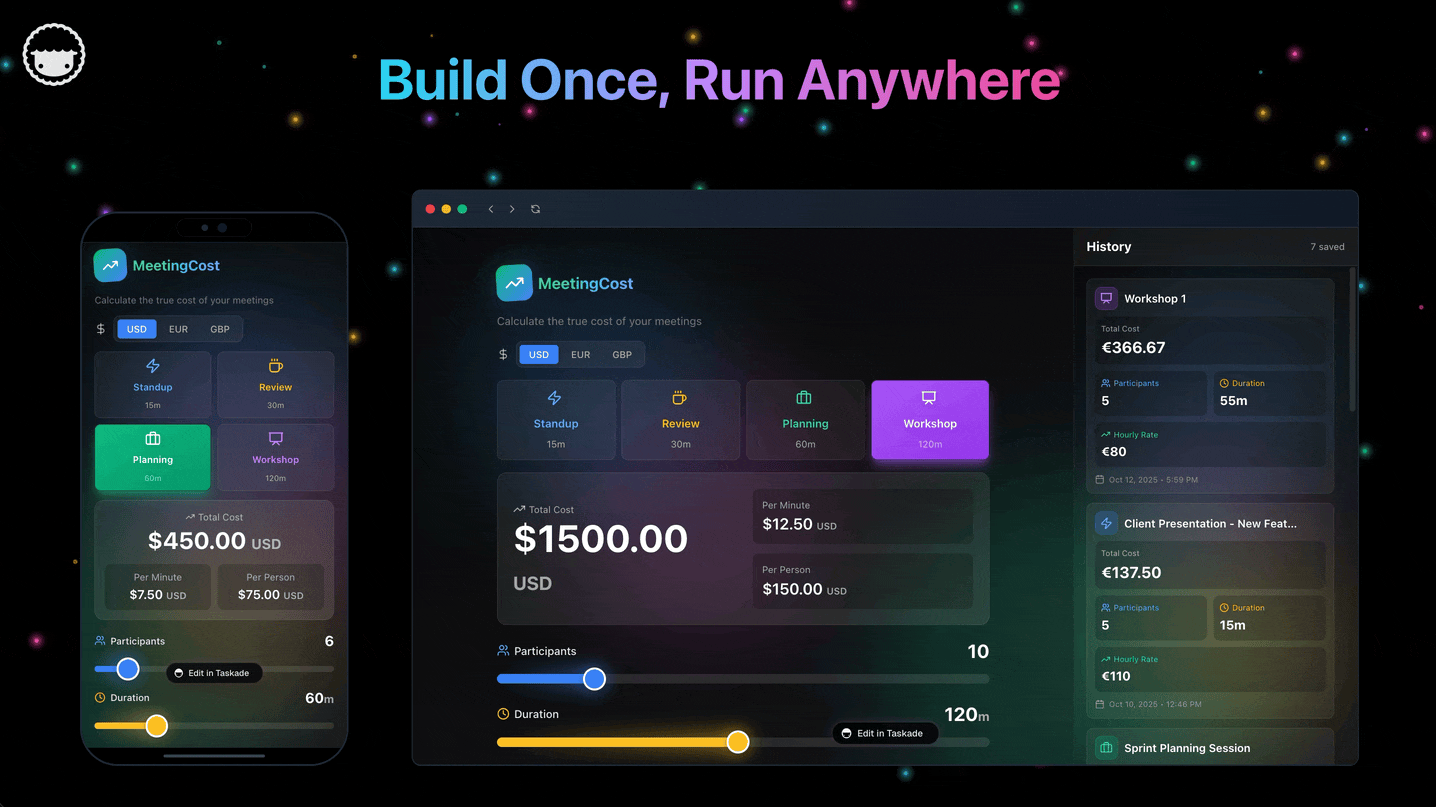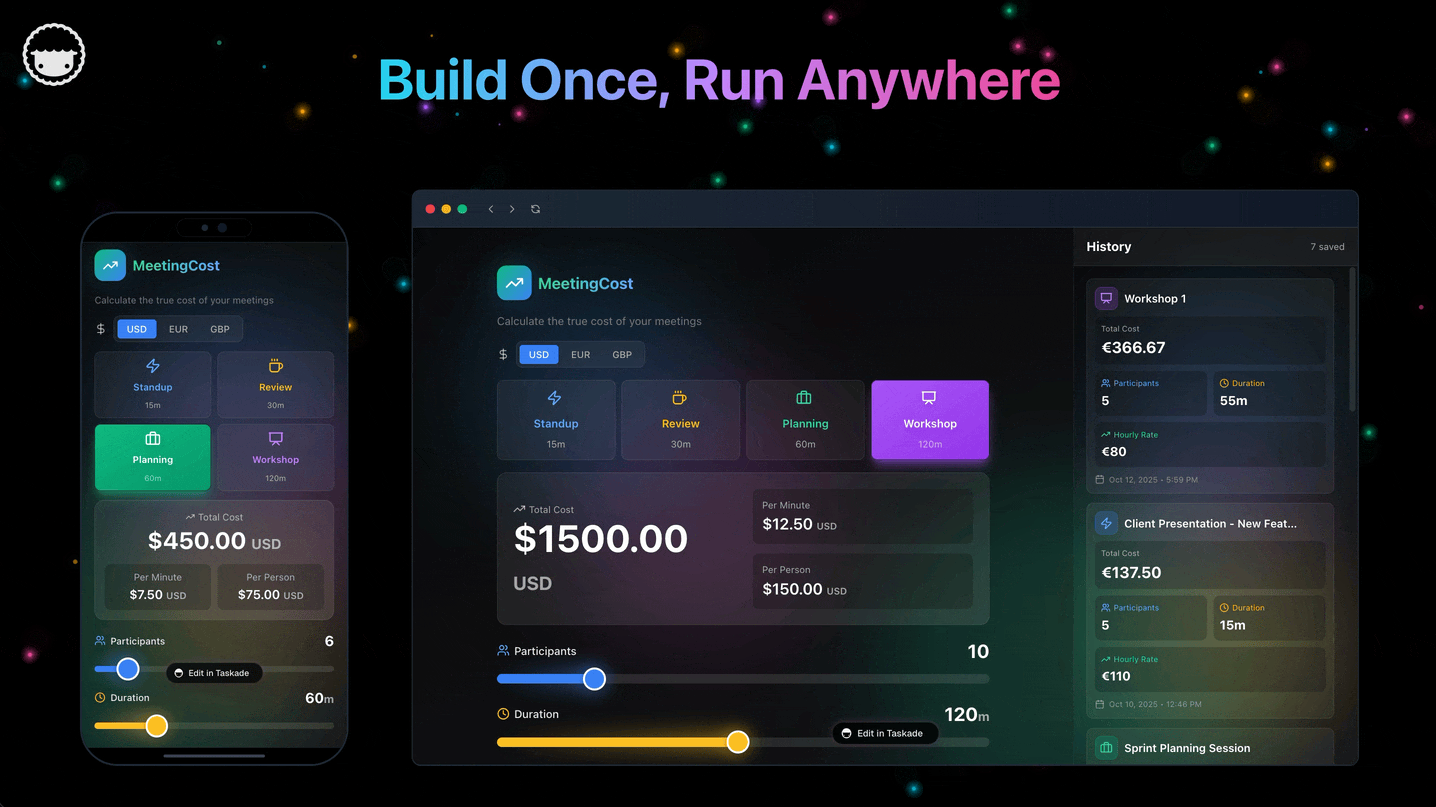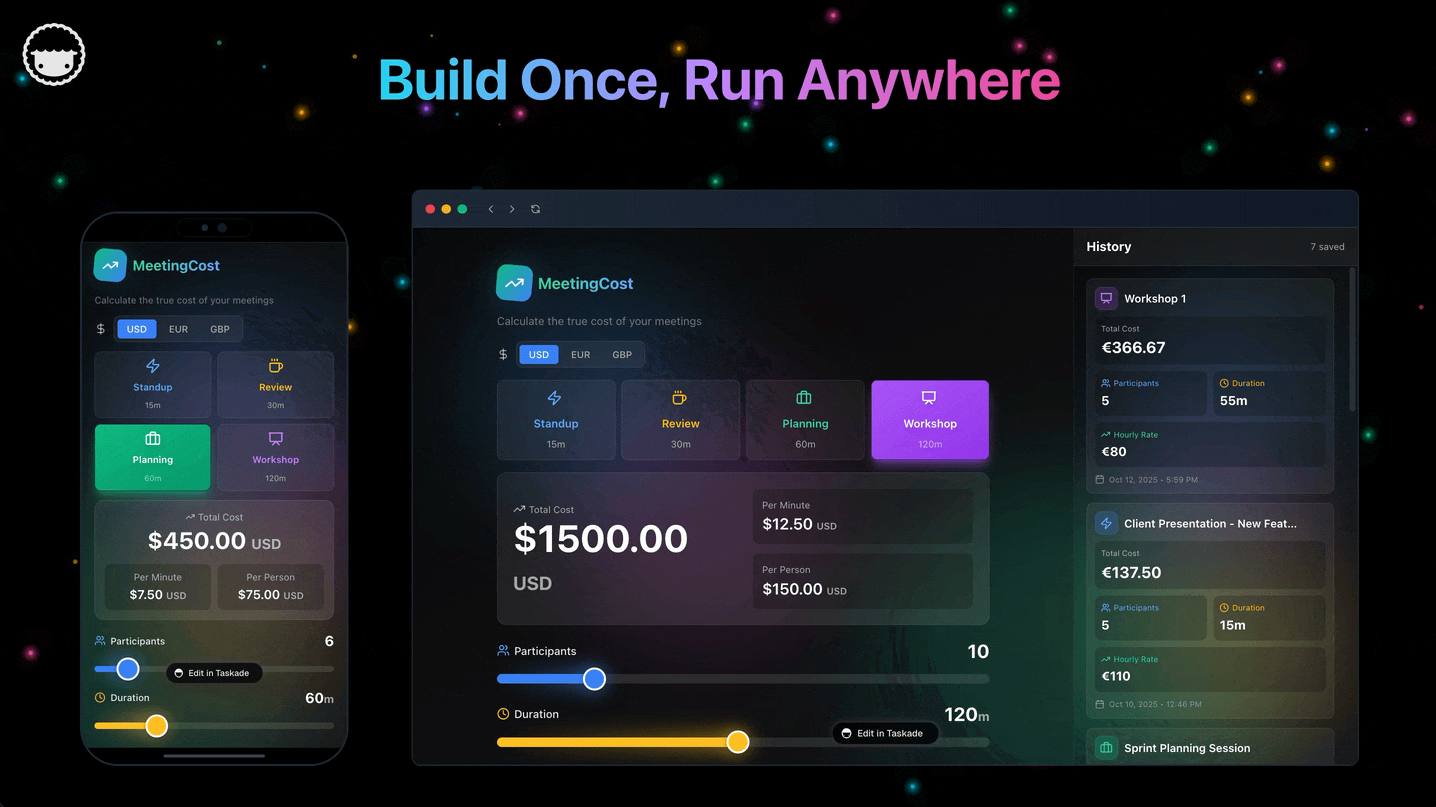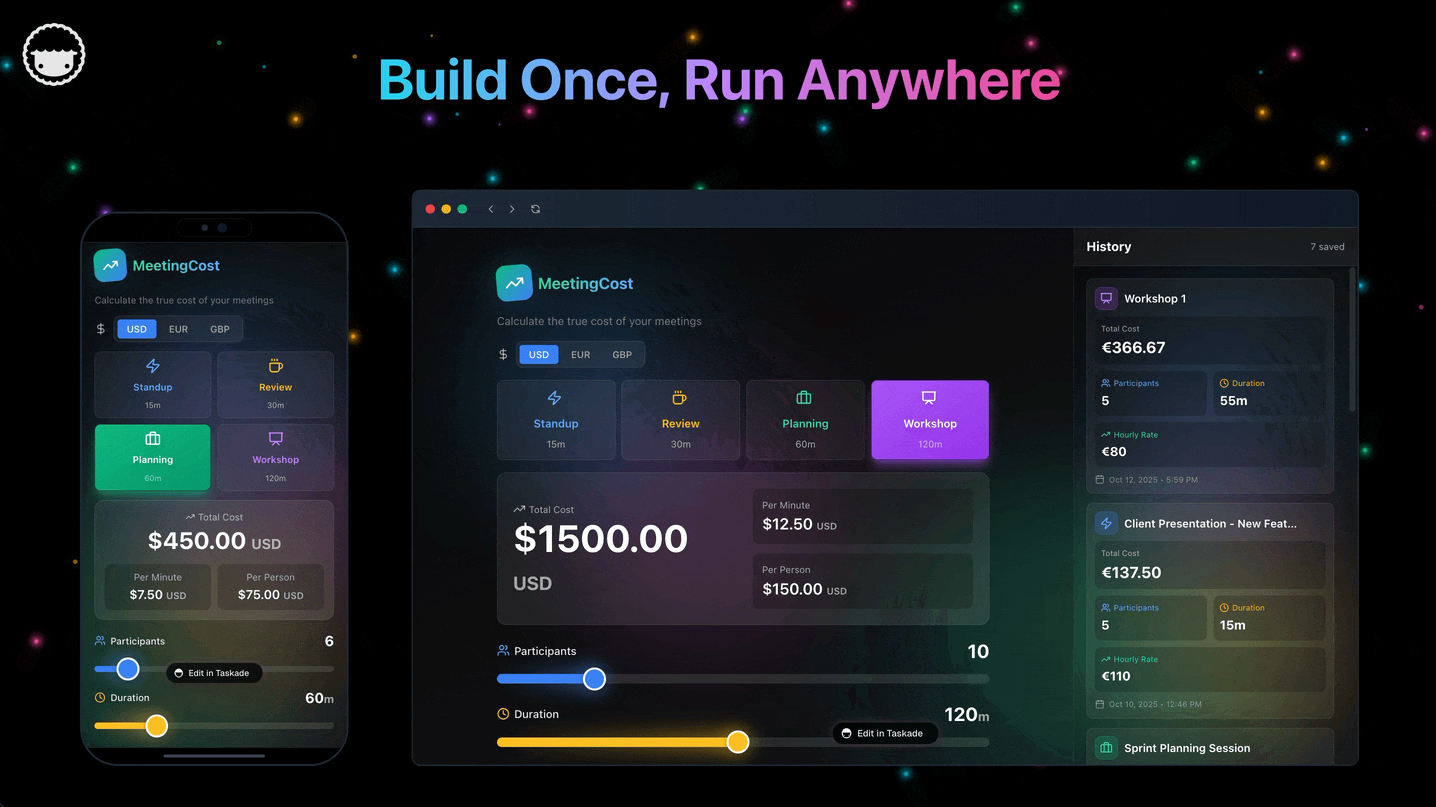
Parse each branch's overlay writes into typed records. The four record kinds match Workspace DNA exactly:
| Record kind | What it captures | Schema source |
|---|---|---|
| Project | id, title, view type, custom fields | Taskade Project schema (with 7 view types: List, Board, Calendar, Table, Mind Map, Gantt, Org Chart) |
| Agent | id, name, role, tools, knowledge project ids | Agents v2 schema (custom tools, slash commands, persistent memory, 33 built-in actions) |
| Automation | id, trigger spec, action list | Automation Workflow schema (branching, looping, 100+ bidirectional integrations) |
| Interface | page id, component tree | Taskade Genesis App schema (compiled to live URL with SSL + custom domain) |
Each record has a semantic identity — a deterministic key that captures structural equivalence regardless of trivial differences. Two projects both titled "Contacts" with custom fields [email, phone] get the same key, even if their UUIDs differ. This is what makes the merge actually work.
4. Cross-branch intersector
For each semantic key, count how many branches produced an equivalent record. Three buckets:
| Count of branches | Bucket | Action |
|---|---|---|
| ≥ ⌈N/2⌉ (majority) | Invariant | Commit to user's real workspace via the same install path that powers Genesis app clone/import |
| Between 2 and ⌈N/2⌉−1 | Divergence | Surface as an Ask-Questions prompt — show the user which branches voted for each option |
| Exactly 1 | Outlier | Discard. Log to branchTrace memory project for transparency |
Inside an invariant — say all 4 branches produced the "Contacts" project — there can still be field-level divergences. One branch had 5 custom fields, another had 7. We recurse: the project is invariant, but its customFields is a divergence question.
This is the precise analog of Feynman's interference principle at the structural level. Right answers reinforce. Wrong answers cancel. Disagreements get measured.
5. Three-bin sort + Ask-Questions integration
The output of the intersector becomes:
- A workspace installation payload (the invariants) — committed via the same path Genesis already uses for app clone and import
- An Ask-Questions prompt (the divergences) — fired through EVE's existing question tool, with a side-by-side branch tally
- A branchTrace project (everything: invariants, divergences, user choices, outliers) — written under
projects/memories/branchTrace/so the whole reasoning trail is a real workspace artifact you can revisit
Reusing the existing infrastructure for all three is what makes the implementation tractable. We are not building new database tables, new RPC surfaces, or new UI components. We are composing primitives Taskade already ships.
🧬 Why Workspace DNA Is the Only Substrate That Works
Here is the question every multi-agent paper has dodged for two years: what is your merge alphabet?
| Substrate | Merge unit | Failure mode |
|---|---|---|
| Source code (Cursor, Lovable, v0, Bolt, Replit) | Lines of text | Whitespace, naming, refactor noise drowns signal. Renames break diffs. Functionally identical code looks different. |
| Free-form natural language (most ChatGPT plugins) | Tokens | No structure. Two paraphrases of the same answer don't match. |
| Linear flow JSON (Zapier, Make.com) | Step nodes | No memory layer; no intelligence layer. Two-dimensional. |
| Embedding similarity (RAG-heavy systems) | Cosine distance | Opaque. Cannot surface to user as a question. Threshold-tuning brittle. |
| Workspace DNA primitives | Project · Agent · Automation · Interface | Stable semantic identity. Deterministic diff. Surface-able to user. |
This is the moat. The reason no competitor can ship structural interference merge is that they don't have the alphabet. They have text.
A "Contacts project" is the same primitive whether spelled contacts.taskade, Contacts.taskade, or customer-records.taskade — the semantic identity (a project containing contact records with email/phone fields) survives the trivial differences. A "Sales-Coach agent with the Sales-Pipeline project as knowledge" is the same primitive whether the agent ID is agt_001 or agt_xyz — the role + knowledge linkage is the identity.
This is exactly the property Bill Atkinson named in HyperCard: "Use the same primitive everywhere. The icon, the menu, the stack — never invent new abstractions, compose what exists." Workspace DNA inherits the lineage. The longer arc is in History of Primitives.
🪄 The Five Strategies of Multi-Branch Context Engineering
Context engineering's five strategies — selection, compression, ordering, isolation, format — were defined by LangChain for single-agent systems. Each one applies one level up to multi-agent systems, where the unit becomes branches rather than tokens. Below is the mapping that turns each strategy into a multi-branch primitive.
| Strategy | Single-agent meaning | Multi-agent multi-branch meaning |
|---|---|---|
| Selection | What facts enter the context window | Which branches participate in the merge (drop slow / failed / corrupted) |
| Compression | Summarize long histories | Compress per-branch tool call traces into invariant records |
| Ordering | Place priority info where attention peaks | Order branches by semantic similarity to canonicalize the merge fixed-point |
| Isolation | Separate sub-agent contexts | Branch-isolated sandbox — the cryogenic chamber pattern |
| Format | Structure as tables, JSON | Structure outputs as typed Workspace DNA records, not free text |
The branch-isolated sandbox is the single most important upgrade. Without it, your N branches contaminate each other and the merge produces nonsense. Decoherence kills computation. This is the single deepest lesson the history of quantum computing hands to AI engineers: isolate the computation from the environment, then measure once at the end.
Read more in the Context Engineering Field Guide 2026.
🧪 End-to-End Example — A 4-Branch CRM Generation
The simplest way to grok interference merge is to walk through a concrete generation. Below: a 4-branch fan-out on a CRM prompt. The user types one sentence; EVE spins 4 isolated branches; the structural diff bins every project, agent, and automation into invariants (commit), divergences (ask user), and outliers (discard). User prompt:
"Build a CRM to track leads, deals, and follow-up automation. We're a 6-person sales team."
Branch 1 (α): the canonical answer
Projects:
- Contacts (Table view, fields: email, phone, company, status)
- Deals Pipeline (Board view, 4 stages: Lead → Qualified → Proposal → Closed)
- Activity Log (List view, fields: type, date, outcome)
Agents:
- Sales Coach (knows Contacts + Deals Pipeline, drafts follow-ups)
Automations:
- New contact → assign to Lead stage
- Stage change → notify in Slack
Branch 2 (β): same but with 6 stages
Projects:
- Contacts (same)
- Deals Pipeline (Board, 6 stages: Lead → Qualified → Proposal → Negotiation → Closed Won → Closed Lost)
- Activity Log (same)
Agents:
- Sales Coach (same)
Automations:
- Same two flows
Branch 3 (γ): same as α but agent named differently
Projects:
- Contacts (same)
- Deals Pipeline (4 stages, same as α)
- Activity Log (same)
Agents:
- Pipeline Coach (same role as Sales Coach)
Automations:
- Same two flows
Branch 4 (δ): same as α plus an extra project
Projects:
- Contacts (same)
- Deals Pipeline (4 stages, same as α)
- Activity Log (same)
- Forecasting (Table view, fields: month, target, actual)
Agents:
- Sales Coach (same as α)
Automations:
- Same two flows
- Plus: monthly rollup → write to Forecasting
What the merge layer does
INVARIANTS (in 4 of 4 branches):
✓ Contacts project
✓ Activity Log project
✓ "Pipeline" project (semantic match — disagrees on stage count, but the project is invariant)
✓ Sales/Pipeline Coach agent (semantic match — same role)
✓ "New contact → Lead" automation
✓ "Stage change → Slack" automationDIVERGENCES (some but not all branches agree):
? Deals Pipeline stages: 4-stage (α, γ, δ) vs 6-stage (β)
→ ask: "Pipeline stages: 4-stage (Recommended — 3 of 4 branches) or 6-stage with Negotiation/Won/Lost split?"
? Agent name: "Sales Coach" (α, β, δ) vs "Pipeline Coach" (γ)
→ silently choose majority; log in branchTrace
OUTLIERS (in 1 branch only):
✗ Forecasting project (only in δ)
→ discard. log to branchTrace.
✗ Monthly rollup automation (only in δ)
→ discard with the project it depends on.
What the user sees
EVE's chat response (cinematic, per the existing prompt convention):
"🌅 The dream begins.
I imagined four versions of your CRM. They agreed on three projects (Contacts, Deals Pipeline, Activity Log), one Sales Coach agent, and two automations (Lead-stage assignment, Slack stage-change notifier). Three of the four branches went with a 4-stage pipeline; one branch proposed 6 stages with Negotiation/Won/Lost split. One branch also added a Forecasting project for monthly rollups.
Two questions before I commit:
1. Pipeline stages — 4-stage (Recommended) or 6-stage?
2. Add the Forecasting project + monthly rollup automation?Or keep it as the agreed-on core and we'll layer Forecasting later. Branch trace lives in projects/memories/branchTrace/2026-05-XX-CRM."
The user picks 4-stage and "skip Forecasting for now." The invariants commit. The branchTrace project is now a workspace artifact the user can revisit.
What lands in your workspace (the receipt)
Most multi-agent systems leave nothing behind. Interference merge writes the entire decision to disk as a real Taskade Project. After the run above, projects/memories/branchTrace/2026-05-02_crm.md lands in your workspace — clone-able, fork-able, link-shareable:
branchTrace · 2026-05-02 · CRM (N=4)
─────────────────────────────────────────────────────────────────────
PROMPT Build a CRM to track leads, deals, and follow-up automation
N=4 temperatures [0.5, 0.6, 0.7, 0.8] wall-time 47s credits 312
(≈ 2.1× a single-branch run, measured May 2026)✓ INVARIANTS (committed automatically)
• Project: Contacts ← in α β γ δ (4/4)
• Project: Deals Pipeline ← in α β γ δ (4/4)
• Project: Activity Log ← in α β γ δ (4/4)
• Agent: Sales Coach ← in α β δ (3/4) semantic match w/ γ "Pipeline Coach"
• Automation: Lead-stage assign ← in α β γ δ (4/4)
• Automation: Stage-change Slack ← in α β γ δ (4/4)
? DIVERGENCES (asked the user — answers logged)
• Pipeline stages: 4 (α γ δ) vs 6 (β) → user picked 4
• Agent name: 3-vote majority "Sales Coach" → applied silently
✗ OUTLIERS (discarded)
• Project: Forecasting (only δ) → log only
• Automation: Monthly rollup (only δ, depended on Forecasting) → log only
COLLAPSED → /spaces/sp_8h2k_demo · 4 stages · Sales Coach · 3 automations · 6 seats
This file is a real Taskade Project — open it in any view (List, Board, Table), fork it as a starting point for the next CRM, or share the URL with a teammate. The merge is auditable. That is the difference between an inference-time architecture and a black box.
💰 What This Costs
The honest engineering accounting:
| Component | LOC | Effort | Why bounded |
|---|---|---|---|
| Fan-out orchestrator | ~600 | 40h | Wraps existing single-agent loop; no new model calls beyond the N parallel agent.stream() invocations |
| Branch-isolated sandbox | ~700 | 60h | Extends existing workspace-write router; overlay pattern caps memory at 1MB/branch |
| Interference merge primitive | ~800 | 80h | Reuses Workspace DNA Zod schemas; semantic-key + intersection are deterministic algorithms |
| Mermaid + branchTrace | ~250 | 40h | Extends existing mermaid output; branchTrace is a normal Project marked as internal memory |
| Observer copy + auto-tune-N | ~150 | 16h | Prompt edits + heuristic |
| Total | ~2,500 LOC | ~236 engineering hours | One sprint cycle for one team |
The actual marginal runtime cost for N=4 branches is about 2× a single-branch run, not 4×, because:
- The system prompt is shared (~25% of typical token budget) — cached once via ephemeral cache control
- The read-side workspace read context is shared — branches diverge only on writes
- Slow branches are dropped at the 1.3× p95 timeout
Information is physical and erasure has thermodynamic cost (Landauer). Don't pay for branches you don't need. The auto-tune-N heuristic picks N=1 for trivial edits, N=4 for new spaces, N=16 only when the user explicitly toggles Deep Think.
The bars are runtime cost; the line is information yield. After ~N=4, the marginal cost continues to rise but the yield asymptotes. That's why the default is N=4.
📚 How This Compares to the Research Literature
The closest research ancestors. We extend the table forward to April 2026 because the literature accelerated sharply in the first four months of the year:
| Paper / system | Year | Mechanism | What it gets right | What interference merge adds |
|---|---|---|---|---|
| Self-consistency (Wang et al., arXiv 2203.11171) | 2022 | N samples, majority-vote final answer | Showed +10–25pp on math/code | Operates on tokens; we operate on structural records |
| Tree of Thoughts (Yao et al., arXiv 2305.10601) | 2023 | Branch-and-prune at intermediate steps | First explicit search-tree LLM | Single value function; we use user measurement |
| Reflexion (Shinn et al., arXiv 2303.11366) | 2023 | Episodic-memory verbal reflection | Persistent memory across attempts | Sequential, not parallel |
| Self-Refine (Madaan et al., arXiv 2303.17651) | 2023 | Generate → critique → revise loop | Free, no labels | Single-branch; no parallel exploration |
| TIES-Merging (Yadav et al., arXiv 2306.01708) | 2023 | Trim → Elect Sign → Merge model weights, naming "interference" as the merge problem | Coined the interference terminology in model merging | We extend the same word, one level up — to multi-agent reasoning, not weights |
| OpenAI o1 | 2024 | Inference-time chain-of-thought | Proved the inference-time scaling law | Token-level, not structural |
| OpenAI o3 / o4-mini | 2024–25 | Native multimodal reasoning at inference | Operationalized the "reasoning-revolution" scaling regime | Single model; we use N independent agents on shared substrate |
| PDR+RTV — Scaling Test-Time Compute for Agentic Coding (arXiv 2604.16529) | Apr 2026 | Plan-Develop-Refine + Round-Trip Verification | "Decisively outperformed prior state-of-the-art inference-time scaling methods in the agentic regime." | Operates on file-level edits; we operate on full Workspace DNA structures |
| CATTS — Agentic Test-Time Scaling for WebAgents (arXiv 2602.12276) | 2026 | Per-step compute budgeting | Showed: "uniformly increasing per-step compute saturates fast in long-horizon environments." Argues for branched compute over deeper compute. | We are the branched-compute answer at the app-build layer |
| ReasoningBank / MaTTS (Google Research) | 2026 | Memory-of-experience for agents | +8.3% on WebArena, +4.6% on SWE-Bench-Verified vs memory-free agents | We persist branchTrace as workspace memory automatically — no separate store |
| Autosys (UC Berkeley I-School) | 2026 | "Git diff discipline applied to agent reasoning" — Claims/Evidence/Decisions graph | Production-grade reasoning auditability | We operationalize this through Workspace DNA's stable schema |
Interference merge sits one level above all of these: it operates on structurally-typed outputs (Workspace DNA), uses user measurement (the Ask-Questions prompt) instead of a learned value function, and emits a persistent workspace artifact (branchTrace) that becomes training data for future runs.
If you want the cognitive-science cousin of this idea, Metacognitive AI traces the lineage from Flavell (1979) to Reflexion to today — the thinking about thinking loop is the human-cognition analog of branch-aware reasoning.
April 2026 — the multi-agent convergence event
In a single month, three IDE-bound coding tools and one OpenAI release shipped multi-agent fan-out as a first-class product surface — and a half-dozen academic papers landed simultaneously confirming the inference-time scaling regime. Verbatim from Nimbalyst's analysis: "Cursor 3 released the Agents Window with worktree-aware multi-agent workflows, Windsurf Wave 13 brought first-class parallel sessions and worktrees, and OpenAI shipped Codex multi-agent v2 with structured inter-agent messaging."
APRIL 2026 — MULTI-AGENT TOOLING CONVERGENCE
───────────────────────────────────────────
Cursor 3 — Agents Window ●━━━━━━━━┓
Windsurf Wave 13 — worktrees ●━━━━╋━━━━┓
OpenAI Codex v2 — multi-agent ●━━━╋━━━━╋━━━━┓
arXiv: PDR+RTV (agentic coding) ●━╋━━━━╋━━━━╋━━━┓
Google Research: ReasoningBank ●━━╋━━━━╋━━━━╋━━━╋━━━┓
Berkeley I-School: Autosys ●━━━━━━╋━━━━╋━━━━╋━━━╋━━━╋━━━┓
▼ ▼ ▼ ▼ ▼
All converging on the
same idea: parallel
branches > deeper passes
│
▼
but all of them are
still operating on TEXT.
Workspace DNA is the
*structural* substrate
none of them have.
The whole industry is racing to productize what a 1985 paper described and a 2025 Nobel Prize confirmed: parallel branches, phased to interfere, are the right architecture. What is missing — and what Taskade Genesis ships — is the substrate. Workspace DNA primitives have stable semantic identity. Source code does not.
🌳 Branch-Aware AI Agents — A Defined Term
Most "multi-agent" systems shipping today are sequential pipelines or best-of-N picker patterns wearing the multi-agent label. Branch-aware AI agents are something different. We define the term explicitly because no one else has, and the SERP for the phrase currently returns nothing — which is itself a sign that the category needs a name.
Branch-aware AI agent (n.): an AI agent that knows it is one of N candidates running the same prompt in parallel, that its writes are scoped to a per-branch sandbox, and that its output will be structurally diff-merged against the other branches before any of it touches the user's real workspace. The agent does not need to coordinate with siblings, because the merge layer is the coordination — agreements commit, disagreements surface, outliers discard.
Why the term matters:
- Sequential agents know about each other (planner → coder → reviewer) but do not branch — so a single bad reasoning step poisons everything downstream.
- Best-of-N agents branch but do not know they branched — only one survives, the rest are wasted.
- Branch-aware agents branch and know it — so each branch optimizes for being a useful candidate in a merge, not for being a complete answer on its own. The constraint is liberating: a branch can take a risk because the merge will catch it if every other branch disagrees.
Branch-aware reasoning is the same architectural shape as the history of quantum computing hands AI: superposition over candidates, interference at the merge, measurement at the end. It is the productized form of metacognitive AI — agents that reason about their own role in a parallel computation.
🚀 What's Next — The Roadmap
Three follow-ups, in order of confidence:
Q3 2026: ML-ranked picker — Replace majority-vote with a small reward model trained on accumulated branchTrace data. Threshold for shipping: ≥10K real branchTrace projects with explicit user measurements. Until then, majority vote is the ceiling.
Q4 2026: Cross-branch agent debate — Within a divergence, let the branches that voted differently exchange one round of reasoning before the user is asked. This is a partial revival of the AutoGen-style debate, but scoped to the divergence set instead of the whole problem. Latency budget: +1 round-trip per divergence.
Q1 2027: Branch sharing — Publish a branchTrace as a Community Gallery item. Other users see "I built this CRM from this prompt; here are the 4 alternatives EVE considered" — recruiting demo and conversion artifact in one. Privacy review required (branchTrace contains user prompts).
⚙️ Try It
Taskade Genesis Quantum is rolling out to Pro and above ($16/month annual) behind a feature flag. Free and Starter plans get full Workspace DNA — Projects, Agents v2, Automations, Taskade Genesis Apps with custom domains and SSL — without the parallel-branch reasoning, today.
- Build your first Taskade Genesis app: taskade.com/create
- Browse 150,000+ live apps: /community
- Templates and AI generators: /templates and /generate
- Step-by-step guides: /learn/genesis/faq · /learn/agents/custom-agents · /learn/automation/triggers
Read the rest of the cluster:
- History of Quantum Computing: From Deutsch to Taskade Genesis Multi-Agents — the 50-year arc this architecture inherits, including the Oct 2025 Nobel Prize for the Josephson-junction physics behind every superconducting qubit
- Quantum Supremacy for App Builders: Why Taskade Genesis Builds in Parallel Branches — comparison vs Cursor, Lovable, v0, Bolt, Replit, Windsurf, Bubble, Webflow, Adalo, Glide
- Workspace DNA: The Context Engineering Blueprint for 2026 — the substrate this architecture depends on
- Metacognitive AI: How Agents Learn to Think About Thinking — the cognitive-science cousin (Flavell 1979 → Reflexion → branch-aware reasoning)
- Agentic Engineering: Karpathy and the AI Agents History — the broader inference-time-scaling arc
- Context Engineering Field Guide 2026 — the canonical strategies
- History of Primitives — why structural primitives win the era
- History of Mermaid.js — the diagram language we use to render branchTrace
- Workspace Memory Knowledge Graph — the workspace-scoped graph surface (open from the workspace sidebar) visualizing how Memory, Intelligence, and Execution interconnect
The next era of AI app builders is multi-agent. The moat is structural merge. The math has been on the table since 1985. The first commercial implementation is shipping now. Try Taskade Genesis →
Frequently Asked Questions
What is multi-agent interference merge?
Multi-agent interference merge is an inference-time architecture in which N AI agents run the same prompt in parallel, then their outputs are structurally diff-merged into three sets — invariants (records that appear in a majority of branches, committed automatically), divergences (records or fields that disagree, surfaced as user-facing questions), and outliers (records that appear in only one branch, discarded). The pattern mirrors quantum computing's interference principle. Wrong answers cancel, right answers reinforce. Taskade Genesis Quantum is the first commercial app builder to ship this on Workspace DNA primitives.
How is interference merge different from best-of-N?
Best-of-N runs N candidates and picks one — the other N minus 1 are discarded entirely. Interference merge keeps all N. Records that show up in the majority commit immediately as invariants. Records that disagree on specific fields become user-facing questions. Only the truly unique outliers are discarded. The information yield per fan-out is up to N times higher because every branch contributes its agreements, not just the winner. Self-consistency papers in 2022-2024 showed that majority-vote across N samples beats best-of-N by 10 to 25 percentage points on math and code benchmarks; interference merge generalizes that across structural records, not just final tokens.
Why can only Taskade Genesis ship structural interference merge?
Code generators like Cursor, Lovable, Bolt, and v0 produce text — their merge unit is a line of code. Text-diff merging is brittle. Renaming a variable breaks the diff, whitespace differences cause false positives, and refactor noise drowns the signal. Taskade produces Workspace DNA primitives — Project, Agent, Automation, Interface — with stable semantic identity. A Contacts project with email and phone fields is the same primitive whether the underlying schema uses CamelCase, snake_case, or different UUIDs. The diff is exact and deterministic. The merge alphabet has to be structural for the technique to be reliable.
What are Workspace DNA primitives?
Workspace DNA is Taskade's self-reinforcing 3-pillar loop — Memory (Projects that hold structured data with 7 view types), Intelligence (Agents with custom tools, persistent memory, and 22 plus built-in actions), and Execution (Automations that branch, loop, and integrate with 100 plus external services). The complete Taskade Genesis app is assembled from four canonical primitives that map to the loop — Project (Memory), Agent (Intelligence), Workflow (Execution), and App (the Interface that runs on top). Each primitive has stable schema and addressable identity, which is what enables structural merge across parallel agent branches.
How does branch isolation prevent decoherence?
In quantum computing, decoherence is the contamination of a superposed system by leaks to the environment, destroying the computation. The same problem appears in multi-agent AI when N branches all write to the same workspace mid-flight. Writes interleave, race conditions corrupt the state, and the user sees half-built apps mutating in real time. Branch isolation gives each parallel agent its own branch sandbox clone. The agent reads from the source workspace but writes to an isolated overlay that is never persisted until the merge layer decides what to commit. The user's actual workspace stays unchanged until the final committed result.
What is the role of the Ask-Questions tool in interference merge?
The EVE Ask-Questions tool is the user's measurement device. When parallel branches diverge — say two branches produce a 4-stage pipeline and two produce a 6-stage pipeline — the merge layer surfaces the divergence as a structured question. The user's answer collapses the parallel possibilities into one chosen reality, exactly the way a quantum measurement collapses a superposition into a single observed outcome. This preserves user agency. The AI does not silently choose; the user is shown the trade-off and picks.
What is the cost of running N branches?
Naively, N branches cost N times one branch. With prompt caching across the shared prefix — the system prompt, user message, and read-side workspace read context — the actual marginal cost for a 4-branch fan-out is closer to 2x a single run. The branchTrace project that gets persisted afterward has zero marginal cost because it reuses Taskade's existing project storage. The auto-tune-N heuristic chooses N equals 1 for trivial edits, N equals 4 for new spaces, and N equals 16 only when the user explicitly toggles Deep Think. This keeps the cost bounded.
How does interference merge relate to tree of thoughts and self-consistency?
Self-consistency (Wang et al., 2022) and tree of thoughts (Yao et al., 2023) are the closest research ancestors. Self-consistency runs N samples and majority-votes the final answer. Tree of thoughts branches at intermediate steps and prunes by value. Interference merge generalizes both. It operates at the structural-record level rather than the token or step level, it preserves the divergence set instead of collapsing it, and it uses the user's measurement to resolve conflicts rather than a learned value function.
Why does the merge layer use majority vote and not a learned reward model?
Majority vote is parameter-free, interpretable, and produces no training-data flywheel debt. A learned reward model needs labeled data, suffers from reward hacking, and creates a single point of failure. The Taskade Genesis Quantum v1 design starts with majority vote and persists every branchTrace as labeled data inside the user's workspace. After enough branchTrace projects accumulate, a learned ranker can be trained later as an optional refinement — but v1 ships without it because majority vote already beats best-of-1 reliably.
Can I see the alternate apps EVE considered?
Yes. Every Quantum fan-out persists a branchTrace as a real Project under projects/memories/branchTrace/ in your workspace. The project has a Board view with one column per branch, a Table view of invariants vs divergences vs outliers, and a List view of the user's chosen answers. You can revisit it, fork it, share it via Taskade's existing 7-tier role-based access, or ask EVE to restore a discarded branch — go back to branch beta — at any time. The exploration is itself a workspace artifact.
What is decoherence in plain language?
Decoherence is the wall between branches. In quantum computing it is the process by which a superposition becomes a single classical outcome when the system interacts with its environment. In multi-agent AI it is the equivalent. When parallel branches contaminate each other's writes, the parallel reasoning collapses into a noisy mess. Branch-isolated sandbox prevents that. The wall is what lets parallel computation actually finish before the world looks at it.
Is interference merge open source?
The technique is described in this article and is not patented. The Taskade Genesis Quantum implementation is part of the Taskade product and is currently rolling out to Pro and above plans behind a feature flag. The Workspace DNA primitives that make it work — Projects, Agents v2, Automations, Taskade Genesis Apps — are the platform. You can build with them at taskade.com/create starting on the Free plan.