






TL;DR: AI's origin traces back to two Bronx High School of Science alumni — Rosenblatt (perceptron, 1957) and Minsky (symbolic AI) — whose rivalry defined the field for 50 years. Their competing visions ultimately merged into the transformer architectures powering today's frontier models. Taskade Genesis completes the arc: Workspace DNA (Memory + Intelligence + Execution) turns AI from lab theory into a deployed teammate. Try it free →
The Real Origin of AI
Most people think artificial intelligence was born in Silicon Valley or MIT’s ivory towers.
They’re wrong.
AI’s real origin story starts in a New York City public high school: Bronx High School of Science. Two kids walked those halls in the 1940s, two years apart:
Frank Rosenblatt (Class of ‘46) invented the perceptron in 1957, the first artificial neural network. Marvin Minsky (Class of ‘44) co-founded MIT’s AI Lab, champion of symbolic AI, and the man who nearly buried neural nets with a single book.
Their feud, neurons vs. symbols, connectionism vs. logic, defined AI for half a century.
That’s the Bronx Science legacy: a school where teenagers casually invented the future, disagreed violently about it, and left the rest of the world to fight over the ruins.
A National Treasure
In 1988, a local TV crew filmed Bronx Science’s 50th anniversary celebration. Principal Milton Koppelman walked the cameras through a school the Carnegie Foundation had called "a school that works" — a national treasure tucked into a corner of the Bronx that had already produced eight Nobel Prize winners, more than most universities on Earth.
The numbers were staggering:
| Bronx Science by the Numbers (1988) | |
|---|---|
| Nobel laureates | 8 (7 Physics, 1 Chemistry) — more than most universities |
| Westinghouse finalists | Decades of national dominance (now Regeneron Science Talent Search) |
| AP enrollment | 300+ seniors in 14 college-level courses, 700+ exams per year |
| Scientific careers | ~60% of graduates entered scientific fields |
| Student clubs | 50+ (ethnic, artistic, academic, community service) |
| Languages offered | 8 foreign languages |
| Commute culture | Students from all five boroughs — up to 2 hours each way |
But what the anniversary video captures isn’t a STEM factory. It’s a Rhino XR2 robot programmed by juniors to shake hands. Mock constitutional law trials where students argue precedent. A Holocaust Center with artifacts "of the rarest quality found anywhere in the world." Students dissecting ventricles in AP Biology and asking why the wall thickness differs. An art teacher explaining:
"Art and Science coexist. An Einstein and a Michelangelo would have done very well here. They would have made friends, learned from one another, and as a result would have been better people."
That last line is the thesis. Bronx Science didn’t produce Nobel laureates through narrow specialization. It produced them by forcing collision — physics students taking art appreciation, debate champions studying constitutional law, musicians learning robotics, poets dissecting hearts.
Rosenblatt was a psychologist who built machines. Minsky was a mathematician who theorized about minds. The school made that kind of boundary-crossing inevitable.
Decades later, I walked those same halls.
My Bronx Science Story
I didn’t care about AI history when I was there.
I cared about keeping servers alive.
I was commuting two hours a day from Forest Hills — the classic Bronx Science pilgrimage. In the 1988 anniversary video, a junior from Bayside, Queens describes the same two-hour ritual: "I really think it's worth the trip." Some things never change.
I was spending late nights in the computer lab, and running a web hosting + video streaming business while my classmates were grinding SAT vocab lists. My stack looked like this:
- Physical servers I could barely afford, duct-taped together.
- VPS slices carved into existence with more hacks than best practices.
- FFMPEG pipelines crashing when someone uploaded a cursed AVI file.
- Customers who didn’t care if I was a high schooler.
Every outage was a fire. Every support ticket was a gut punch.
And that’s how I learned three lessons more valuable than any AP class:
- Systems break. Always. Build for failure.
- Nobody cares about your tech stack. They care if it works.
- Execution beats theory, every single time.
Those lessons burned into me before I could legally drive a car. I didn’t realize it then, but they were the same lessons AI itself was learning in the wilderness years.
The Perceptron’s Rise and Fall
Frank Rosenblatt’s idea was radical: a machine that could learn, not by following rules, but by adjusting weights, like a brain. The perceptron was simple:
- Inputs with weights
- Sum them
- Apply a threshold
- Adjust based on error
The Rosenblatt Perceptron (1957) Inputs Weights Neuron Output
┌──────┐ ┌──────┐ ┌────────────┐
│ x₁ │───│ w₁ │──▶│ │
│ x₂ │───│ w₂ │──▶│ Σ(xᵢwᵢ) │──▶ 0 or 1
│ x₃ │───│ w₃ │──▶│ threshold │
└──────┘ └──────┘ └────────────┘
If sum > threshold → fire (1)
If sum ≤ threshold → don't fire (0)
Adjust weights based on error. Repeat.
That's it. That's the ancestor of today's frontier AI models.
In 1957, Rosenblatt unveiled the Mark I Perceptron, a room-sized contraption with 400 photocells wired to motors. It could learn to recognize shapes.
The New York Times headline?
“Perceptron, embryo of an electronic computer that will walk,
talk, see, write, reproduce itself, and be conscious of its existence.”
It was hype. And hype is dangerous.
Marvin Minsky, fellow Bronx Science alum, symbolic AI evangelist, struck back. His book Perceptrons (1969, co-authored with Seymour Papert) mathematically proved single-layer perceptrons couldn’t solve XOR.
He wasn’t wrong. But the effect was devastating. Funding vanished. Neural nets were dismissed as a dead end. The field entered its first AI Winter.
And Rosenblatt? He died in 1971 in a boating accident at 43. He never lived to see his vision resurrected. Minsky lived until 2016, long enough to watch deep learning eat the world.
He never fully admitted he was wrong.
Two Bronx Science kids. Same hallways. Polar opposites. Both right. Both wrong.
The Perceptron’s Revenge
The perceptron didn’t die. It waited.
And while it waited, something unexpected happened: physics showed up.
In 1982, a physicist named John Hopfield — not a computer scientist, not an AI researcher — looked at the Ising model of magnetism and saw something everyone else had missed. Atoms in iron carry tiny magnetic spins that tend to align with their neighbors, settling into low-energy configurations. Hopfield realized this was the same math as associative memory: replace atoms with neurons, magnetic coupling with weighted connections, and the system’s tendency to minimize energy becomes a tendency to converge on stored patterns.
The Hopfield network could memorize patterns and retrieve them from noisy inputs — like recognizing a friend’s face in a crowd. Feed it a corrupted image, and it relaxes into the nearest stored memory, rolling downhill through an energy landscape like a marble finding a valley.
Then Geoffrey Hinton took it further. His Boltzmann machine (1985) — named after the physicist who invented statistical mechanics — added probabilistic learning using concepts borrowed directly from thermodynamics: temperature, entropy, simulated annealing. Training a neural network became indistinguishable from the physics of a system cooling into an ordered state.
But there's a missing chapter most histories skip. At Stanford in 1959 — a decade before Minsky's Perceptrons book — Bernard Widrow and his new graduate student Ted Hoff had a Friday afternoon meeting that came agonizingly close to discovering modern backpropagation. Instead of Rosenblatt's ad hoc learning rule, they used calculus to compute the gradient of the error function directly — the LMS algorithm. It was elegant. It was efficient. It worked beautifully for single-layer networks.
But when they tried to extend it to multi-layer networks, they hit a wall: the binary step activation function. Early artificial neurons outputted 1 or 0 — all or nothing. The derivative of a step function is zero everywhere (and undefined at the jump). Calculus couldn't flow through it. The gradient died at the layer boundary.
The fix, in hindsight, was absurdly simple: replace the step function with a sigmoid — a smooth S-curve where the derivative is never zero. That single substitution turned the error landscape from flat plateaus and infinite cliffs into rolling hills that gradient descent could navigate. But nobody made this connection until 1986, when Rumelhart, Hinton, and Williams published backpropagation — citing Widrow and Hoff's LMS algorithm as the starting point and extending it through multiple layers with sigmoid activations. Twenty-seven years between almost-discovering and actually-discovering the algorithm that would power modern AI.
Widrow would later say: "You don't have to square anything or compute the actual error. The power of that compared to earlier methods is just fantastic." And Ted Hoff? He left Stanford and went to Intel, where he co-invented the microprocessor — the Intel 4004. The same person who nearly discovered backpropagation built the hardware that would eventually run it.
Then came GPUs, big data, and algorithmic tricks like dropout and attention.
By 2012, AlexNet — built by Hinton’s student Ilya Sutskever (later co-founder of OpenAI) — blew ImageNet wide open with 10,000x more compute via Nvidia GPUs. Inside, researchers found the network had independently learned edge detectors, texture recognizers, and face detectors — a hierarchy of understanding mirroring biological visual cortex. Its embedding space organized images into a geometry where similar concepts clustered together. AlexNet was the moment AI stopped being hand-crafted and started being grown.
By 2017, transformers changed everything. Self-attention replaced recurrence, scaling soared, and the stage was set for GPT.
By 2023, ChatGPT brought AI into the mainstream.
And on October 8, 2024, the circle closed: Hopfield and Hinton won the Nobel Prize in Physics. Not the Turing Award. Physics. Because the math governing magnets, neural networks, and phase transitions in learning is the same math.
And here's the irony: every transformer, every LLM, every "GenAI" breakthrough is still built on perceptrons. GPT-3 alone contains roughly 10 million artificial neurons spread across 96 layers — each layer still using blocks that OpenAI calls by the name Rosenblatt gave them almost 70 years ago: multi-layer perceptrons. You would need 10 million of our perceptron machines, each with over 10,000 dials, to implement GPT-3. GPT-4 is reportedly 10x larger — approximately 100 million perceptrons. All trained with an extension of the algorithm Widrow and Hoff sketched on a Stanford blackboard in 1959, flowing through the sigmoid activation that unlocked the gradient.
Rosenblatt's insight → Widrow and Hoff's calculus → Hopfield's physics → Hinton's backpropagation → Sutskever's scale → today's frontier AI. A straight line from a Bronx Science hallway to a Nobel Prize in Stockholm.
Minsky’s rules live on too in attention, logic layers, structured reasoning.
The Bronx Science feud resolved itself into synthesis — with an unexpected assist from the physics of magnets.
The Perceptron's Family Tree
| Year | Milestone | Ancestor | What Changed |
|---|---|---|---|
| 1957 | Perceptron | — | First learning machine |
| 1969 | Perceptrons book | Perceptron | "Proved" limits → AI Winter |
| 1982 | Hopfield network | Ising model (physics) | Physics → associative memory |
| 1985 | Boltzmann machine | Hopfield network | Thermodynamics → learning |
| 1986 | Backpropagation | Multi-layer perceptrons | Networks can learn depth |
| 2012 | AlexNet | Deep neural networks | GPUs + data = vision breakthrough |
| 2017 | Transformer | Attention mechanism | Parallel processing, scaling |
| 2022 | ChatGPT | GPT-3.5 (transformer) | AI goes mainstream |
| 2024 | Nobel Prize in Physics | Hopfield + Hinton | Physics and AI are the same math |
| 2025 | Frontier models (OpenAI, Anthropic, Google) | Transformer + RLHF | Reasoning, coding, 4-hour tasks |
| 2025 | Taskade Genesis | All of the above | Execution layer: agents + automations |
Every row is built on the row before it. Every breakthrough traces back to a Bronx Science hallway.
Bronx Science → Modern AI: The Lineage Rosenblatt (1957) Minsky (1969)
┌──────────────┐ ┌──────────────┐
│ Perceptron │ │ Symbolic AI │
│ (learning) │ │ (rules) │
└──────┬───────┘ └──────┬───────┘
│ │
▼ ▼
┌──────────────┐ ┌──────────────────┐
│ Hopfield │ │ Expert Systems │
│ Network │ │ McCarthy: LISP │
│ (1982) │ │ Feigenbaum: │
└──────┬───────┘ │ "knowledge │
│ │ engineering" │
▼ │ (1980s) │
┌──────────────┐ └──────┬───────────┘
│ Backprop │ │
│ (1986) │ ┌──────┴───────────┐
└──────┬───────┘ │ BRITTLE: │
│ │ McCarthy warns │
▼ │ "no common sense"│
┌──────────────┐ └──────┬───────────┘
│ Deep │ │
│ Learning │ ┌──────┴───────┐
│ AlexNet │ │ Knowledge │
│ (2012) │ │ Graphs │
└──────┬───────┘ └──────┬───────┘
│ │
└──────────┬───────────────┘
▼
┌──────────────────┐
│ Transformers │
│ (2017) │
│ Synthesis: │
│ learning + │
│ attention + │
│ structure │
└────────┬─────────┘
▼
┌──────────────────┐
│ Taskade Genesis │
│ (2025) │
│ Memory + │
│ Intelligence + │
│ Execution │
└──────────────────┘
The feud resolved itself into synthesis.
McCarthy's common sense problem is still unsolved.
The Execution Layer
Fast forward to today.
LLMs are powerful. But they’re trapped in demos. Clever chatbots, neat proofs of concept, “AI assistants” that collapse under real-world complexity.
The missing piece? Execution.
Rosenblatt wanted machines that act. Not just predict text. Not just generate code. Act.
That’s where Taskade Genesis comes in.
Taskade Genesis is the execution layer where humans and AI collaborate to actually get things done.
Projects → Knowledge DNA (documents, notes, and tasks = structured memory).
Agents → Intelligence DNA (AI agents trained on your work, not just a prompt window).
Automations → Execution DNA (always-on workflows that execute without babysitting)
Here's what the Workspace DNA loop looks like in practice — User, Project, Agent, and Automation working as a self-reinforcing system:
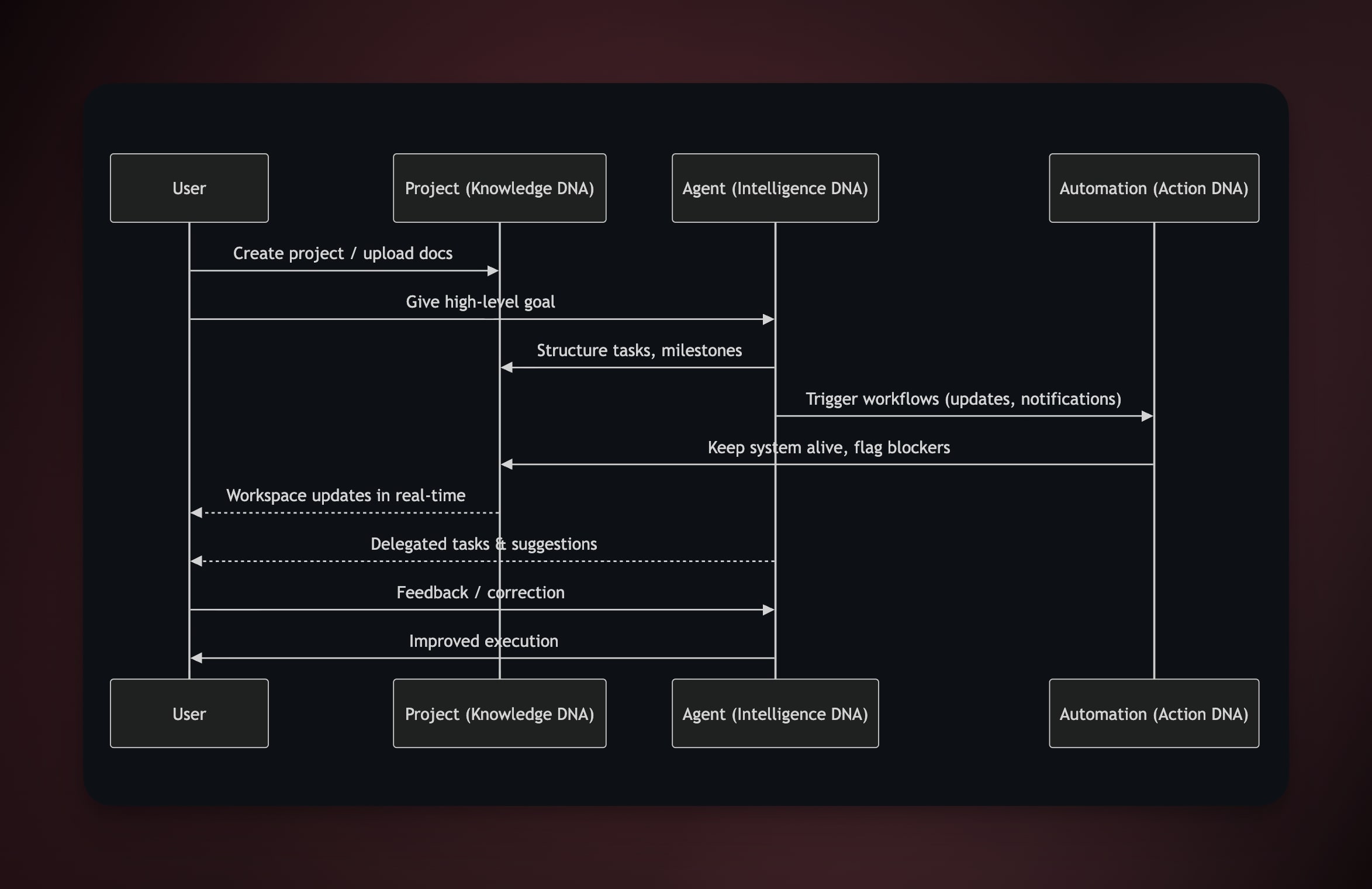
One prompt → a living workspace. Not a paragraph. Not a suggestion. A system that plans, delegates, and ships.
This is what Rosenblatt was dreaming of: not electronic brains locked in labs, but learning systems embedded in human workflows.
Watch: Taskade Genesis turns a single prompt into a live, deployed application.
The Science Behind the Magic
Rosenblatt’s perceptron was simple. What it spawned is not.
If you want to go deeper into the science that connects Bronx Science to modern AI, we’ve built an entire knowledge cluster:
- How Do LLMs Actually Work? — From Rosenblatt’s perceptron to the transformer architecture powering today’s frontier models
- The 27-Year Accident: Widrow, Hoff, and the Sigmoid That Wasn't — The Stanford whiteboard afternoon in 1959 that almost invented backpropagation — 27 years early
- Doug Engelbart's 1968 Demo Was Taskade — The parallel human-augmentation track that converges with the machine-learning track in Genesis
- From VisiCalc to Spreadsheet-of-Thought — The end-user programming lineage that gave a billion non-developers real power
- What Is Mechanistic Interpretability? — How researchers are finally peering inside neural networks to understand what the weights actually learned
- What Is Grokking in AI? — The moment when a network stops memorizing and starts understanding — Rosenblatt’s dream made visible
- What Is Artificial Life? — How intelligence and purpose emerge from computation, from cellular automata to self-replicating code
- What Is Intelligence? — The question Rosenblatt and Minsky were really fighting about
- What Is AI Safety? — Why understanding AI matters more than ever as systems become autonomous
The perceptron’s family tree keeps branching. Every branch leads somewhere fascinating.
Connecting My Dots
When I look back, the threads are clear:
Bronx Science taught me abstraction. Find the pattern or drown in chaos.
The hosting hustle taught me infrastructure. Uptime is everything.
Taskade taught me collaboration. The bottleneck isn’t intelligence, it’s coordination.
Abstraction. Infrastructure. Collaboration.
That’s the DNA of Taskade Genesis.
Rosenblatt knew it. Minsky fought it. I lived it.
Why This Matters
People talk about the PayPal Mafia. The Fairchild Eight.
Nobody talks about the Bronx Science Mafia.
But it’s real:
Rosenblatt and Minsky — two teenagers from the Bronx who accidentally set the trajectory of AI. Generations of builders trained to survive by finding patterns in chaos.
And now, me — a kid from Forest Hills who kept servers alive at Bronx Science and ended up building the execution layer for AI.
Not because I was supposed to.
Because Bronx Science drills into you that systems can always be hacked.
Closing the Circle
The perceptron took 70 years to go from Rosenblatt’s lab to ChatGPT in your pocket.
The next leap, from AI as tool to AI as teammate, won’t take 70. It’ll take 7. Maybe less.
Taskade Genesis is that leap.
Not theory. Not hype. Execution.
Because that’s the Bronx Science way:
- Find the pattern.
- Build the system.
- Ship it before anyone realizes what happened.
The full thesis is here. The execution-layer argument is here. The architecture, compressed to eight symbols, is here.
Epilogue: Irony in the Details
There's a 1984 episode of The Computer Chronicles where John McCarthy — the man who coined “artificial intelligence” and invented LISP — sits alongside Nils Nilsson and Edward Feigenbaum discussing the future of AI. Their answer? Expert systems. Rule-based programs encoding human knowledge. Feigenbaum called it “knowledge engineering.” McCarthy, even then, saw the flaw: these systems had no common sense. A medical expert system could diagnose infections but couldn't understand that a patient is a person.
McCarthy was right. The expert systems were brittle — they shattered the moment reality exceeded their rules. The second AI winter followed. But here's the irony: McCarthy was right about the problem and wrong about the solution. He thought common sense could be formalized into logical axioms. Instead, common sense emerged — imperfectly, approximately — from the brute-force statistical learning that Rosenblatt had championed decades earlier.
In 2013, Google bought DeepMind — a pure neural network shop — for $500 million.
In 2016, the year Minsky died, AlphaGo beat Lee Sedol at Go using deep neural networks.
Rosenblatt never saw his vindication.
Minsky lived long enough to watch the “dead end” consume the world.
McCarthy lived until 2011 — long enough to see neural networks begin their comeback, but not long enough to see them win. His common sense problem remains the hardest unsolved challenge in AI.
And me? I’m building on their shoulders, in the same Bronx Science lineage, with Taskade Genesis — the execution layer where perceptrons finally fulfill their promise.
The perceptron didn’t die.
It was just waiting.
Now it’s awake.
John Xie is the founder and CEO of Taskade. He attended Bronx High School of Science, where he ran a video hosting business between classes and learned that execution beats theory every time. Taskade Genesis is his answer to 70 years of AI evolution: stop talking about intelligence, start shipping execution.
Read more: History of cPanel & WHM (1996 → 2026) | Chatbots Are Demos. Agents Are Execution. | From Web Hosting to AI Infrastructure | How Do LLMs Actually Work? | What Is Intelligence?
Build with Taskade Genesis: Create an AI App | Deploy AI Agents | Automate Workflows | Explore the Community
Frequently Asked Questions
Who invented the first artificial neural network?
Frank Rosenblatt, a graduate of Bronx High School of Science (Class of 1946), invented the perceptron in 1957 — the first artificial neural network capable of learning from data. The perceptron is the ancestor of every modern deep learning system, from GPT to image recognition models.
What was the Rosenblatt vs Minsky debate in AI history?
Frank Rosenblatt championed connectionism (neural networks that learn from data), while Marvin Minsky (Bronx Science Class of 1944) championed symbolic AI (logic-based systems with explicit rules). In 1969, Minsky and Papert published 'Perceptrons,' which argued neural networks couldn't solve complex problems — triggering an 'AI winter' that set back neural network research for decades. History proved Rosenblatt's approach correct.
How did the perceptron lead to modern AI systems like GPT?
Rosenblatt's perceptron established the core principle: artificial neurons can learn patterns from data by adjusting connection weights. This evolved into multi-layer networks (1980s), deep learning (2010s), and finally transformer architectures (2017) that power GPT, Claude, and Gemini. Every modern language model is a descendant of Rosenblatt's 1957 insight that intelligence emerges from pattern-matching, not hand-coded rules.
What is the connection between psychology and artificial intelligence?
AI's founders were deeply influenced by cognitive psychology. Rosenblatt was a psychologist who modeled the perceptron on biological neurons. Modern AI systems mirror cognitive processes: attention mechanisms (transformers), memory (context windows and RAG), and learning (gradient descent mimics synaptic plasticity). Understanding how minds work turns out to be essential for building systems that think.
What is the connection between Bronx Science and modern AI?
Bronx High School of Science produced two of AI's most important founders: Frank Rosenblatt (Class of 1946), who invented the perceptron and pioneered connectionism, and Marvin Minsky (Class of 1944), who co-founded MIT's AI Lab and championed symbolic AI. Their competing visions — neural networks vs. logic-based systems — defined AI research for 50 years and ultimately synthesized into the transformer architectures powering GPT, Claude, and Gemini today.
How does the perceptron relate to transformers and GPT?
The perceptron established the foundational principle that artificial neurons can learn by adjusting connection weights based on error signals. Multi-layer perceptrons led to backpropagation (1986), deep learning (2012), and transformer architectures (2017). Modern frontier LLMs are built from billions of artificial neurons — direct descendants of Rosenblatt's 1957 perceptron — stacked into layers with attention mechanisms that enable parallel processing and contextual understanding.
What is grokking and how does it connect to the perceptron?
Grokking is the phenomenon where a neural network suddenly transitions from memorizing training data to genuinely understanding underlying patterns — a phase shift from rote learning to generalization. This connects directly to Rosenblatt's original vision for the perceptron: he believed machines could learn to recognize patterns, not just store them. Grokking validates that insight, showing that neural networks can achieve deep understanding given enough training.
What is Taskade Genesis and how does it connect to AI history?
Taskade Genesis is the execution layer where AI stops being a demo and starts being a teammate. It connects to AI history through the Workspace DNA framework: Memory (projects and documents), Intelligence (AI agents powered by 15+ frontier models), and Execution (automations with 100+ integrations). This fulfills Rosenblatt's original dream of learning systems embedded in real-world workflows — not locked in labs, but actively planning, delegating, and shipping alongside humans.
Why did it take 27 years to discover backpropagation after the perceptron?
In 1959, Bernard Widrow and Ted Hoff at Stanford discovered the LMS algorithm — a calculus-based method for training neural networks remarkably close to modern backpropagation. But multi-layer networks required gradients to flow through activation functions, and the binary step function (output 1 or 0) killed the gradient — its derivative is zero everywhere. The fix was replacing the step function with a smooth sigmoid curve. Nobody made this connection until 1986 when Rumelhart, Hinton, and Williams published backpropagation. That 27-year gap is one of the great what-ifs in computing history. Ted Hoff left Stanford for Intel, where he co-invented the microprocessor.
How many Nobel Prize winners came from Bronx High School of Science?
Bronx High School of Science has produced eight Nobel Prize winners — seven in Physics and one in Chemistry — more than most universities worldwide. Notable laureates include Leon Cooper (1972, superconductivity), Sheldon Glashow and Steven Weinberg (1979, electroweak unification), Melvin Schwartz (1988, muon neutrino), and H. David Politzer (2004, asymptotic freedom). This extraordinary concentration of physics talent from a single public high school is unmatched in educational history.
What was John McCarthy's common sense problem and why does it matter?
John McCarthy — who coined artificial intelligence in 1956 and invented the LISP programming language — identified that AI systems could encode specialist knowledge (medical diagnosis, computer configuration) but could not reason about the things everybody knows. In a 1984 appearance on The Computer Chronicles alongside Nils Nilsson and Edward Feigenbaum, McCarthy argued that expert systems were fundamentally limited because they lacked common sense. This brittleness triggered the second AI winter. McCarthy's common sense problem remains unsolved in 2026 — modern LLMs approximate common sense through massive training data but still make errors that reveal gaps in genuine world understanding.